About datasets¶
A dataset is a collection of data grouped together to support use cases required by a high-level goal. A dataset may contain smaller datasets, as if they are building blocks.
For example, data that is streamed to Amperity to provide the underlying data that enables real-time workflows may also be configured to run as part of the batch process, which makes that data available to the real-time dataset and the customer 360 dataset.
Data sources¶
Each data source or data asset that is made available to your Amperity tenant acts as a dataset that can be used as a building block for customer profiles. The combination of source datasets is unique to your brand and depends on what types of data your brand wants to make available to Amperity.
Customer profiles¶
A customer profile dataset has a collection of unified customer profiles that your brand can use to build audiences that enable any marketing workflow.
A customer profile dataset is most often represented by the Customer 360 database in your Amperity tenant. This may be configured to filter databases by brand.
Customer profile details are pulled from the Customer 360 table that is located in your brand’s primary customer 360 database. Customer profile details include:
Names (first name, last name), email address, physical address, phone numbers
Transaction details (first purchases, last purchases, total purchases, etc.)
Other custom profile values that are unique to your company
These details can be accessed from the Profile tab on the Customer 360 page.
The Profiles tab shows the date on which the primary customer 360 database was last updated, how long it took to complete the update, and the number of customer profiles in the database.
Each customer profile is a collection of common attributes, transaction attributes, and other custom values that are unique to each customer’s data set. These details are summarized on the Customer 360 page under Customer Profile.
Flexible merge rules¶
Some customer data platforms require using an inflexible merge rule across many fields, which results in lower quality data across your customer 360 profile. This problem is magnified when that inflexible merge rule must also be applied to many databases.
Amperity combines the use of flexible merge rules with a patented system that allows many databases to exist within the same tenant. This ensures that:
Merge rules are 100% configurable
Each field can have its own merge rule
Each database can have its own set of merge rules
Each tenant can support a variety of merge rules to meet all of the requirements for any individual use case
For example, data sources from call centers, online transactions, and email platforms may contain slightly different sets of customer profile data.

After loading this data to Amperity and assigning the Amperity ID to each of your customers, you can use flexible merge rules to support many customer 360 databases.
Your operations teams can combine prioritizing the most common values for each customer with deterministic matching
Your email marketing team can combine prioritizing customer profile values from your email platform with probabilistic matching
Your paid media team can combine all possible values to improve match rates on platforms like Google Ads and Facebook
Ask your Amperity implementation team for recommendations and best practices for how you can configure flexible merge rules to support all of your use cases.
Real-time tables¶
Real-time tables contain data that is streamed to Amperity. Real-time tables are available alongside customer profiles in your brand’s customer 360 database. Real-time tables complement the daily batch process that builds and maintains complete and durable customer profiles over longer timeframes by enabling use cases that require the use of time-sensitive data that is updated more often.
Stitched tables¶
Stitch uses a patented identity resolution workflow to find the hidden connections in your brand’s online and offline customer data. Stitch assigns each customer profile a unique identifier that remains stable over time, even when new and conflicting data is collected.
A stitched dataset has a collection of unified customer profiles that are maintained by Stitch. A stitched dataset provides the foundation for all of the datasets that your brand can build within Amperity. Tables within the stitched dataset are also referred to as “standard core tables”.
Standard core tables¶
Standard core tables contain the results of the identity resolution process for your tenant.
Standard core tables belong to one of the following broad categories:
Stitched domain tables |
A stitched domain table exists for each domain table with:
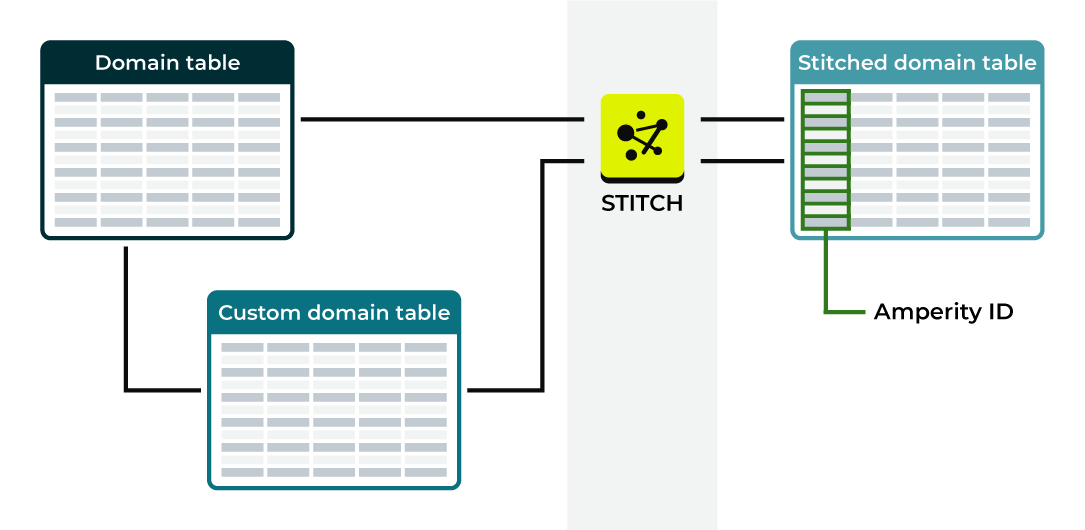
Stitched versions of domain tables have an added column for the Amperity ID and replace the source domain table within Amperity for all downstream use cases, but are otherwise identical to the source domain table. |
Unified tables |
Stitch generates a series of tables that unify your brand’s customer profiles, transactions, and interactions. Rows of records in unified tables are unique by Amperity ID. The collection of unified tables that is generated within your tenant depends on the types of semantic tags that were applied to feeds and custom domain tables in the Sources tab. |
Stitch QA tables |
Stitch generates a series of Stitch QA. Use these tables in a dedicated database to review the quality of the identity resolution process and understand how the Amperity ID gets assigned to each customer profile. Some Stitch QA tables are required by databases that are configured as customer 360 databases. Most are only available from databases that are configured as a Stitch QA database. |
Custom core tables¶
A custom core table built using Spark SQL and may reference one or more core tables or domain tables. Use custom core tables to extend the normalized foundation to support use cases beyond what the set of standard core tables offers.
Custom core tables are reusable across databases, including filtered 360 databases. Core tables store SQL logic that can be referenced by many databases, but can be adapted to provide database-specific logic as well.
For example, the Customer Attributes table typically requires customization to align features within that table to how your brand defines churn prevention status indicators, historical purchase lifecycles, and customer types. This table can be extended to support custom features, and each marketing unit may have different requirements.
If each brand has unique requirements, then each filtered 360 database may require its own customized version of the Customer Attributes table, with each maintained separately.