How Stitch works¶
Stitch uses patented algorithms to process massive volumes of data and discovers the hidden connections in your customer profiles that identify unique individuals. Stitch analyzes customer data, applies the rules you define, and then builds an identity graph with accurate and actionable customer profiles. Each customer profile is assigned an Amperity ID.
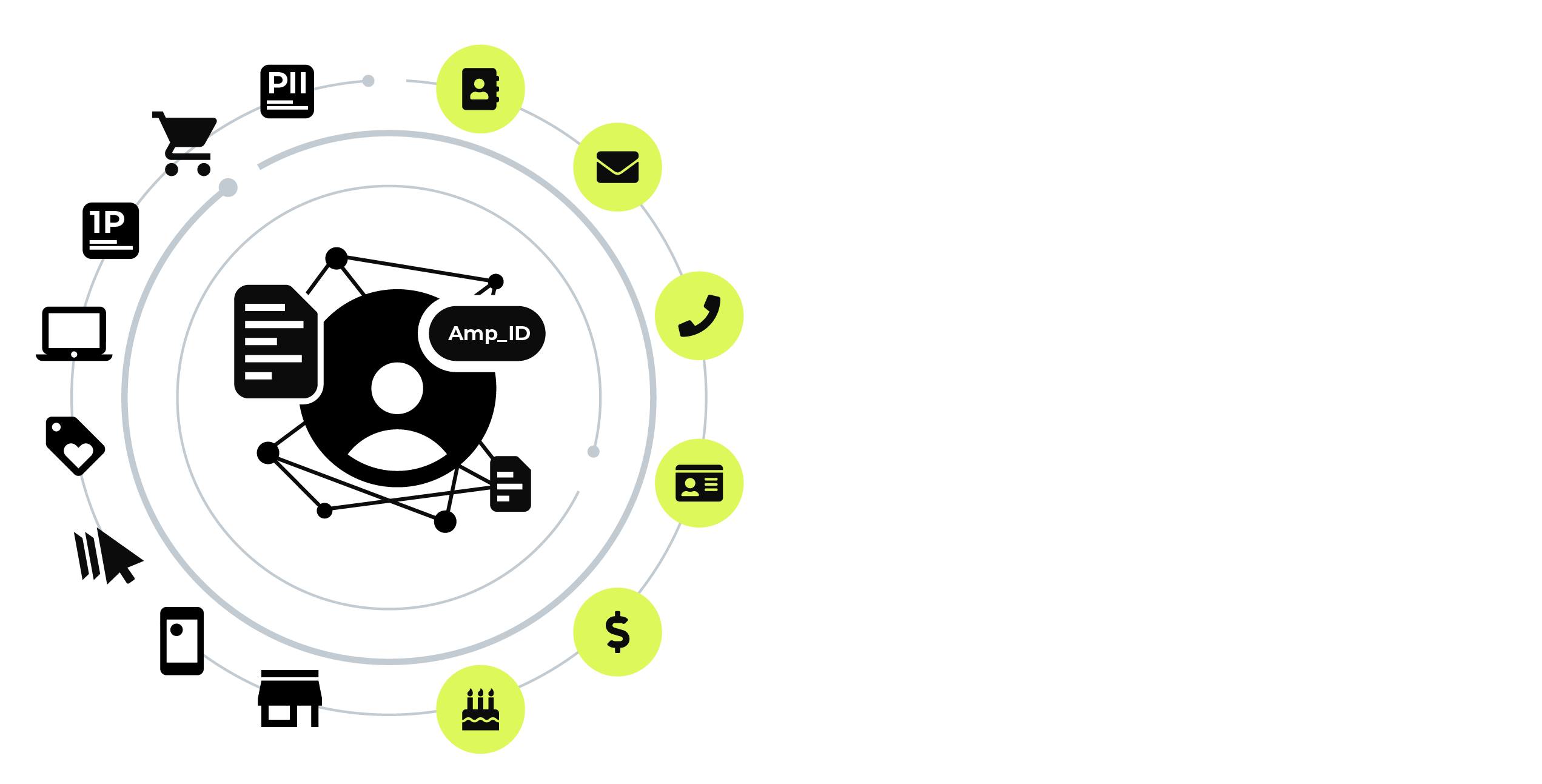
Amperity uses a series of patented innovations to ensure that identity resolution against your customer data is accurate and that the output of the Stitch process represents a unified view of your customers.
Read Entity Matching in the Wild: a Consistent and Versatile Framework to Unify Data in Industrial Applications for a detailed explanation of how Amperity provides a consistent, reliable, and stable customer ID.
Amperity Learning Lab
Stitch evaluates all of your brand’s data to discover hidden connections in customer records and identify unique customers.
Open Learning Lab to learn more about how Stitch works . Registration is required.
Stages of identity resolution¶
Identity resolution is a critical step in understanding who your customers are. Stitch is the component within Amperity that performs identity resolution by comparing all of your customer data, identifying unifying groups of customer records, and then identifying unique customer profiles that represent each of your unique, individual customers.
The stages of identity resolution are:
Preprocess data¶
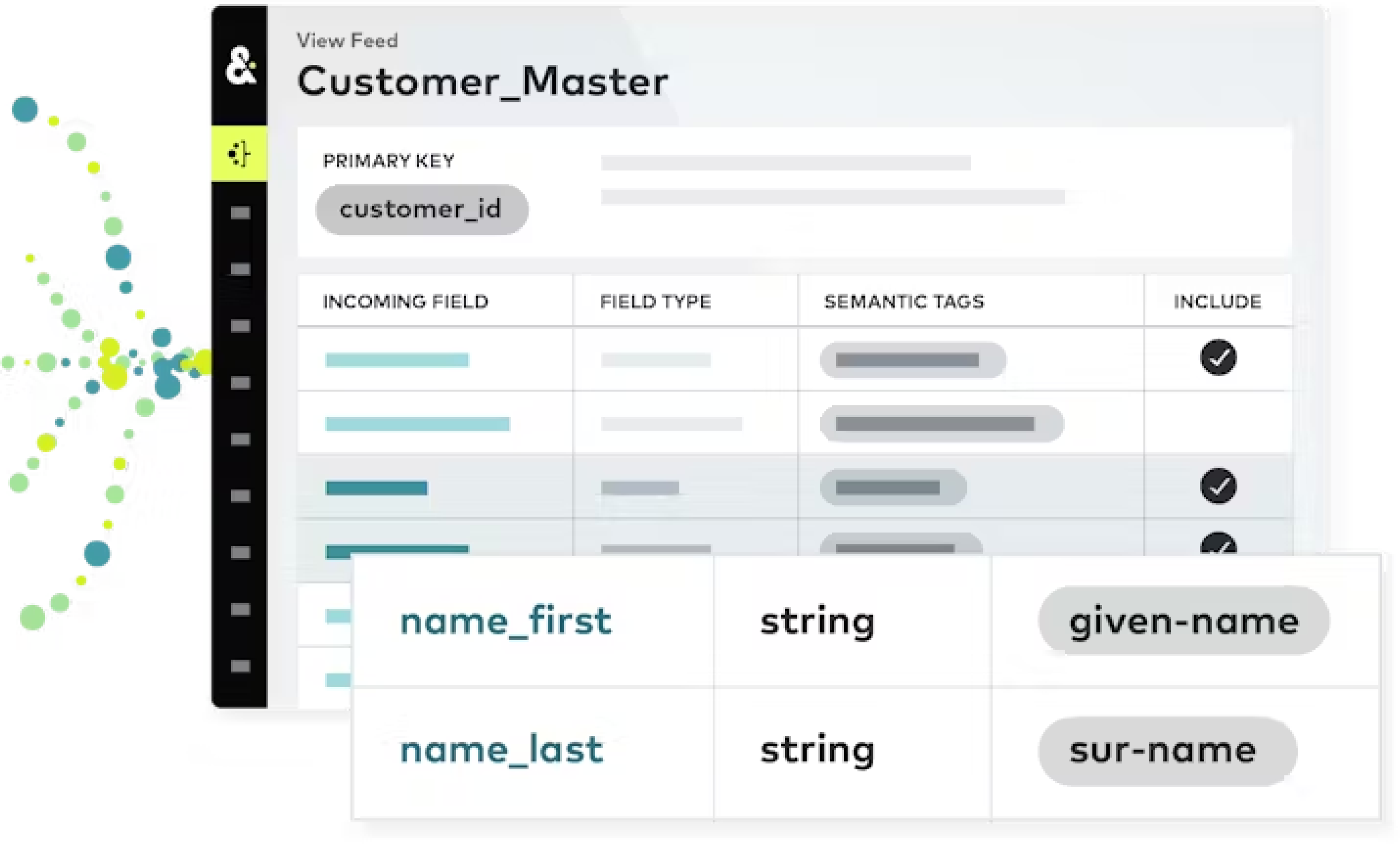
Data is preprocessed into a consistent data pattern before it is combined into a virtual table for use with record matching, blocking, and pairwise comparison. Amperity preprocesses all values in all fields to which semantic tags for profile data were applied.
Note
Preprocessing data ensures that Stitch has access to consistent formatting of data for matching purposes. Preprocessed data is written to the Unified Preprocessed Raw data table. Amperity does not assert that preprocessed data values are better than the original values in the customer’s data.
Addresses¶
Amperity preprocesses addresses by converting common abbreviations to complete words, removing periods and commas–. and ,–and converting all characters to UPPERCASE.
Original value |
Preprocessed to |
|---|---|
|
|
|
|
|
|
|
|
Phone numbers¶
Amperity preprocesses phone numbers by removing parentheses, hyphens, and spaces, consolidating every phone number to a numeric string. Stitch uses the last 10 digits of a phone number for identity resolution.
Original value |
Preprocessed to |
|---|---|
|
|
|
|
|
|
|
|
Email addresses¶
Amperity preprocesses email addresses by ensuring that only the local username and domain are present, separated by @, and converted to UPPERCASE.
Important
All email addresses are validated against a common list of local username patterns that typically indicate junk email addresses, such as test@, no@, or reservation@. When an email address matches one of these patterns, that value is preprocessed to NULL.
Original value |
Preprocessed to |
|---|---|
|
|
|
NULL |
|
|
Note
Field values that were ignored during preprocessing are available as output of Stitch from the Unified Preprocessed Raw table. Fields values that were ignored due to blocklisting are available as output of Stitch from the Unified Coalesced table.
Union of tables¶
All records from all tables that contain customer profile data are merged into a single virtual table that aligns all of the data that is associated with all defined semantic groups.
Semantic tags are applied consistently across data sources. Every email address, physical address, phone number, first and last name is associated to profile semantics. Every order, item, purchase amount, discount amount, return, is associated to transaction semantics.
It is OK if each row does not contain a value for each column. The alignment itself is what is necessary to make this data usable by Stitch for downstream processing and identity resolution.
The following example shows a couple rows from a few tables, the aligned and preprocessed semantic values, and no values when the data source did not provide it. Imagine this for all of your customer data, hundreds of millions of records, hundreds of millions of rows, with fields in the virtual table that span your complete set of customer data.
Source |
Surname |
Address |
Postal |
Loyalty ID |
|
|---|---|---|---|---|---|
Loyalty |
SMITH |
123 MAIN STREET |
98101 |
A-12345-a |
|
Loyalty |
JONES |
10 SOUTH LANE |
10101 |
B-23456-b |
|
In-store |
SMITH |
98101 |
A-12345-a |
||
Online |
SMITH |
123 MAIN STREET |
98101 |
A-12345-a |
|
Online |
JONES |
10 SOUTH LANE |
10101 |
B-23456-b |
|
Clickstream |
A-12345-a |
||||
Clickstream |
B-23456-b |
Blocking¶
Blocking is a technique that groups records into smaller high probability groups before scoring.
Note
Blocking is a non-trivial step for record linking in the Stitch process.
An overly generous blocking strategy may result in a high recall rate, which means too many pairs are evaluated. This can affect system performance.
An overly conservative blocking strategy may result in a low recall rate, which means too few pairs being evaluated.
Individual blocking keys may be conservative or generous.
The combination of blocking keys is what creates the ideal recall rate without compromising the performance of Amperity.
A blocking strategy acts like a filter against large datasets. Each blocking strategy applies its filter. All matching records group together into a block. Each record that matches a blocking strategy is a blocking key.
A blocking key is a specific outcome of a blocking strategy. For example, a blocking strategy for email has a blocking key similar to customer@domain.com.
A block is a group of records that match the characteristics defined by the blocking strategy.
Blocks are created by comparing all records against all blocking strategies. When a record has values that match a blocking strategy these values are combined into a single string value, also referred to as a blocking key.
For example, a blocking strategy that matches:
given-name(3)
surname(3)
postal
results in a blocking key string value similar to Jus:Cur:98101. This operation is similar to the following SELECT statement:
SELECT
left.pk
,right.pk
FROM unified_semantic_data AS left
JOIN unified_semantic_data AS right
ON left.given_name(0,3) = right.given_name(0,3)
AND left.surname(0,3) = right.surname(0,3)
AND left.postal=right.postal
The following sections step through a series of diagrams that describe how blocking works.
Potential blocks¶
The blocking process starts with no matches between records.
Each of these individual dots represents an individual record that can match other records. In the following diagrams, dots are highlighted and lines are added between them to indicate that at least one blocking key match has been discovered by Stitch.
Given name, surname, birthdate¶
The blocking process steps through each blocking strategy, with each blocking strategy defining specific matching patterns against which all records are compared. As records are analyzed and matched to patterns, the matching strings are grouped together for later comparison.

This example shows an important blocking strategy that groups values associated with the following semantics:
The first three characters in given-name
The first character in surname
birthdate.
Given name, surname, ZIP code¶
A record can match more than one blocking key. Some of the records highlighted in this example were also matched in the previous example.

This example shows another important blocking strategy that groups values associated with the following semantics:
The first three characters in given-name
The first three characters in surname
postal.
First 5 characters in email¶
As each blocking strategy is applied, more groups of records are identified.
Many email addresses are not useful for identity resolution. Some of them are generic, such as info@some-domain.com, and are often associated with a place of business and should never be associated with a unique individual. Other email addresses are bogus, having been entered as a requirement for providing a genuine email address, but are otherwise fake, such as 123@some-domain.com.
Amperity uses a list of known “bad” email patterns, such as admin@, contact@, guest@, no@, none@, and then uses the list to exclude from Stitch results any email address that matches a pattern in the list. (This step is done during preprocessing, not blocking.)
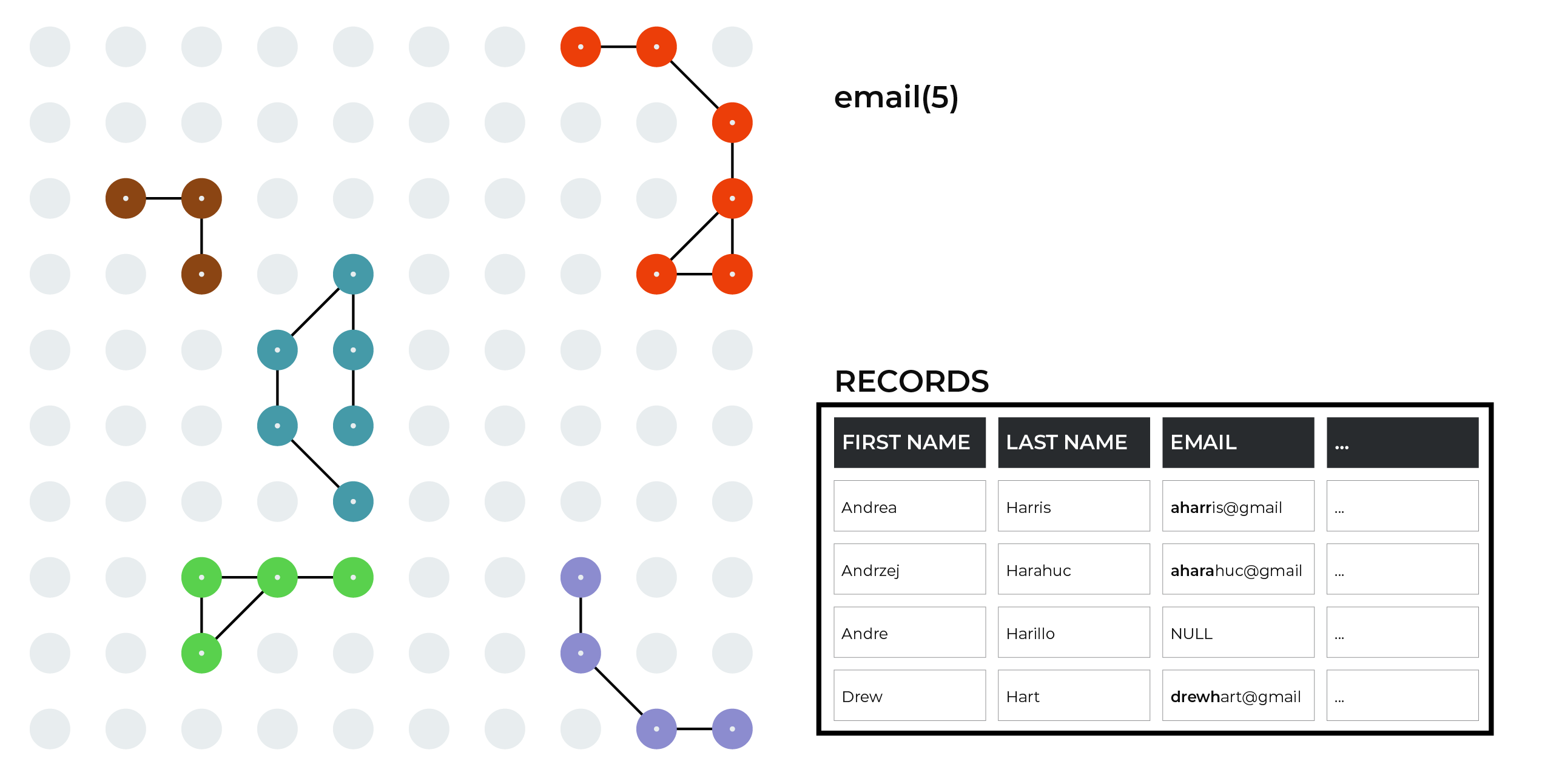
This example shows additional record matches discovered after comparing the first five characters in email addresses across records.
Blocking complete¶
When finished, the blocking process has unioned all of the matching blocking keys together into distinct groups of records.
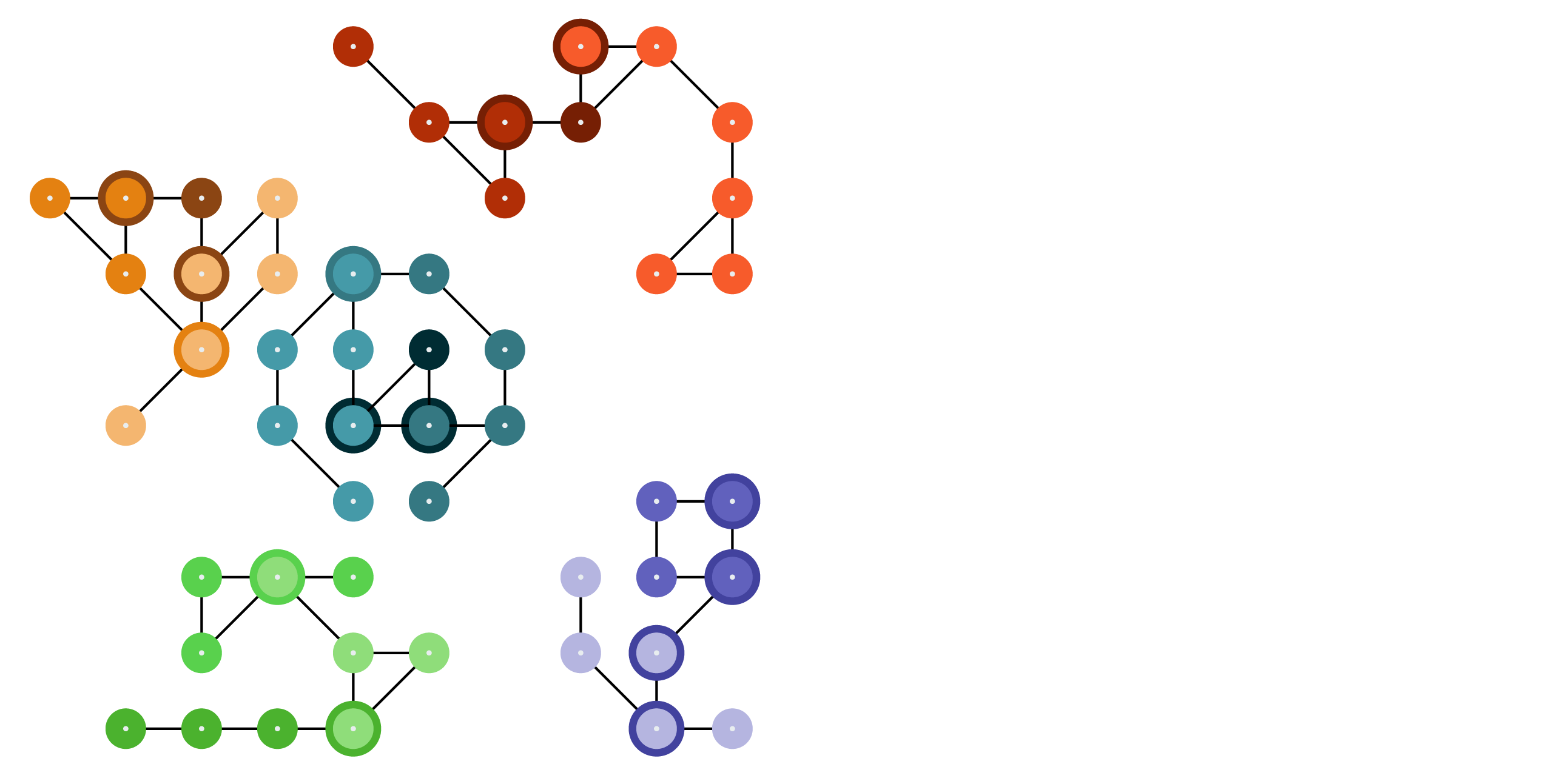
These groups of records will be scored, first as an initial scoring pass that filters out matching pairs that score below threshold, and then as a detailed pass that compares a record in a group to all of the other records in that group.
Initial scoring¶
Each of the matching pairs that were directly identified during blocking are scored. Matching pairs that score below threshold are filtered out, which creates smaller groups of records and also new groups of records, depending on which matching pairs are filtered out.
The following example shows several matching pairs scoring below threshold, using larger dots to indicate which matching pairs scored below threshold.
Four groups of records show matching pairs scoring below threshold in a way that will split each of them into two groups of records.
One group of records shows three scores below threshold, one that does not affect the number of records in the group (because other scores for that record were above threshold) and one that is removed entirely.
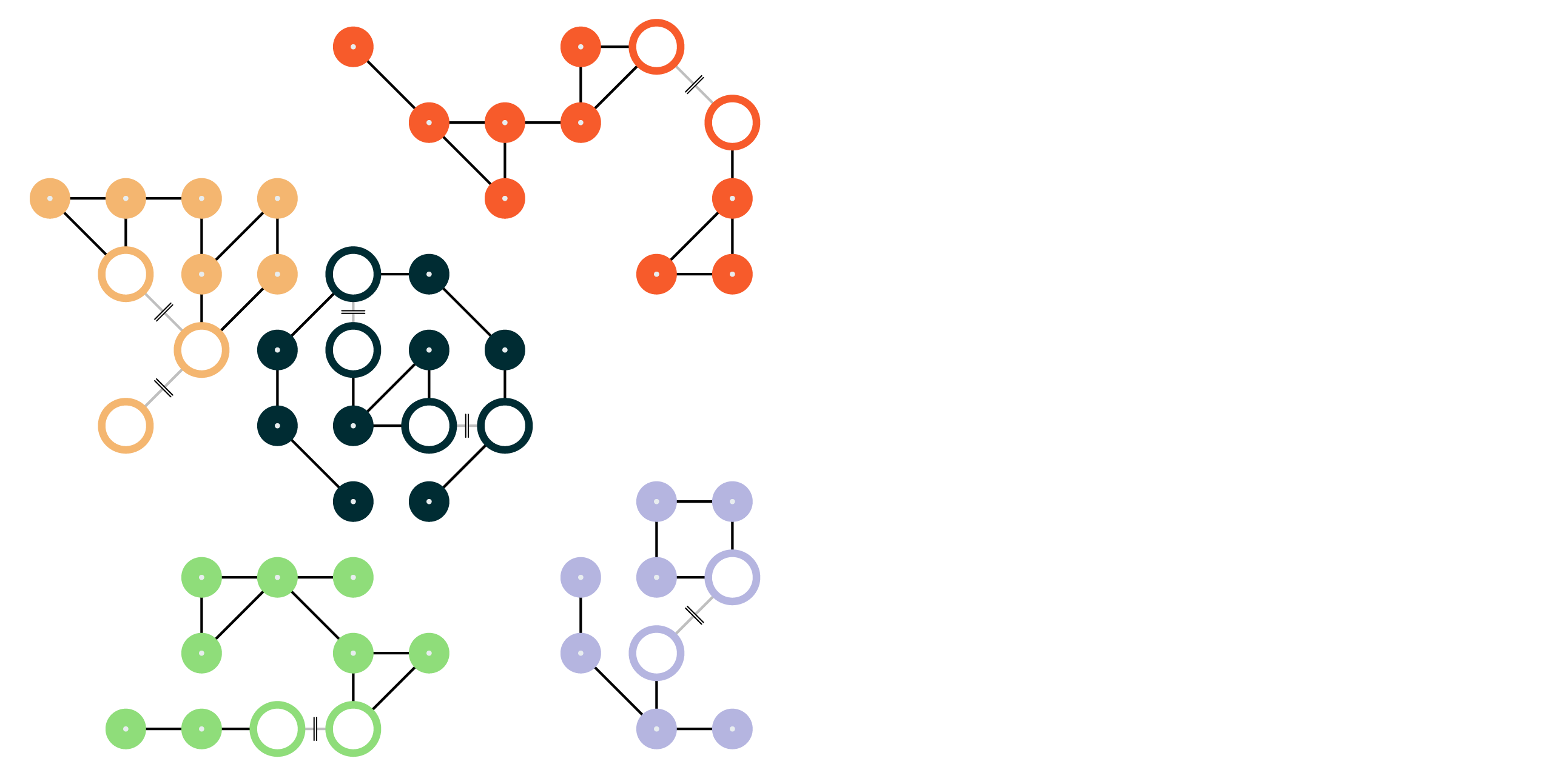
The remaining matching pairs that scored above threshold remain in groups. The following example shows most groups getting smaller, but also four new groups identified.
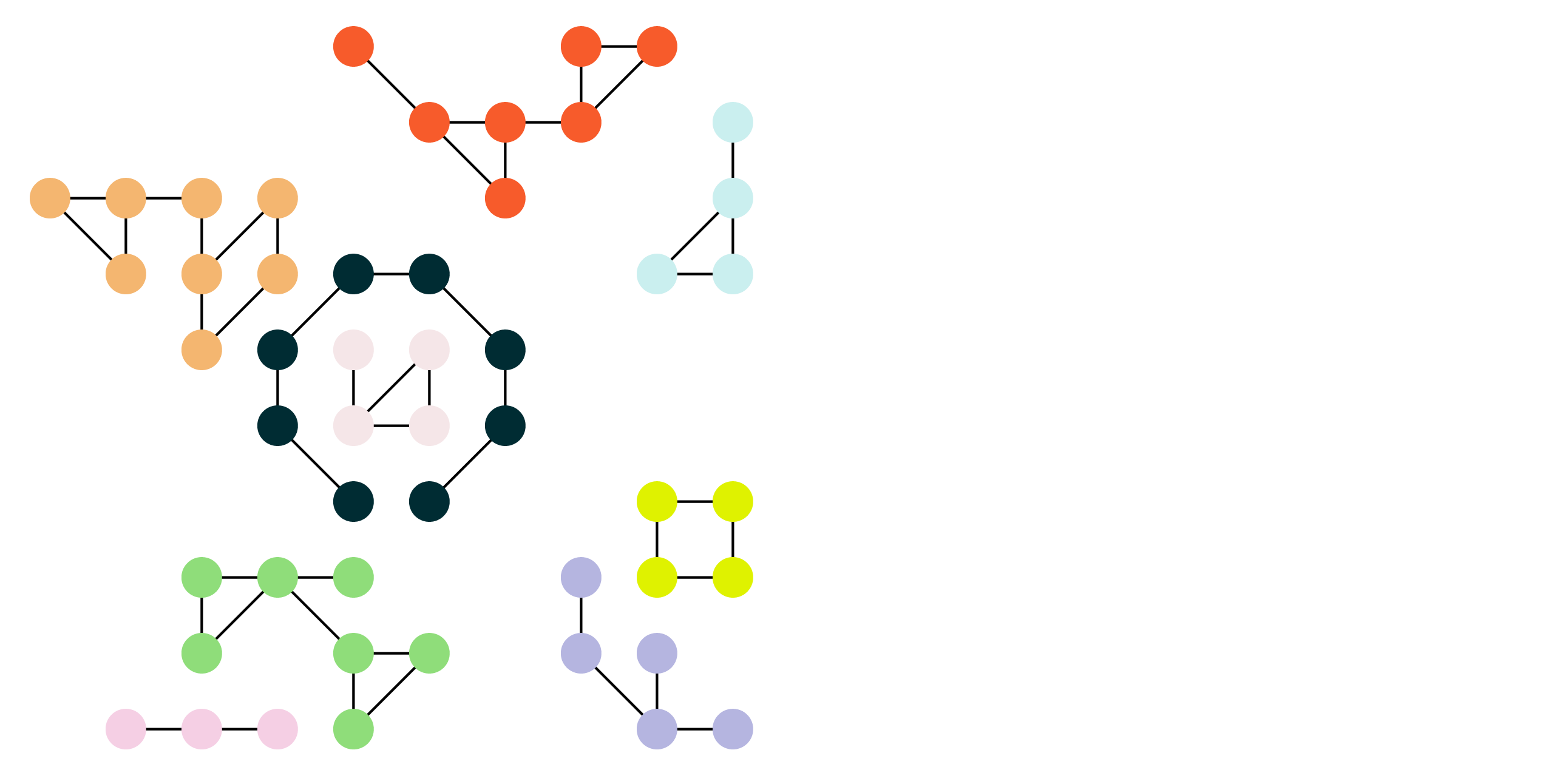
Note
Initial scoring uses the same scoring method as pairwise comparison, with exact, excellent, and high scores being “above threshold” and moderate, weak, and non-matching scores being “below threshold”. The individual scoring methods are covered in greater detail in the following section about pairwise comparisons.
Pairwise comparison¶
Pairwise comparison is a process that compares all possible connections between all records, and then applies scores to build an identity graph.
A pairwise connection is a pair of matching records assigned a score high enough to belong to the same customer profile.
Note
Pairwise comparison uses the same scoring method as initial scoring, but expands scoring to include records with transitive connections.
A transitive connection exists when any two records share a strong match to an intermediate record, but do not have a strong match to each other. For example: record 1 matches record 2, record 3 matches record 2, and records 1 and 3 do not match. A transitive connection exists between records 1 and 3 because both records match record 2.
An example of pairwise scoring using a single block of records:
A pairwise connection has a score with two parts separated by a period.
The first part–the record pair score–correlates to the match category, which is a machine learning classifier applied during identity resolution to individual record pairs:
5 for exact matches
4 for excellent matches
3 for high matches
2 for moderate matches
1 for weak matches
0 for non-matches
Identity resolution uses the second part–the record pair strength–to show the quality of the record pair score. This value appears in the Stitch report as a two decimal number. A record pair strength by itself is not a direct indicator of the quality of a pairwise connection score.
The following thresholds are available:
Threshold |
Match category |
|---|---|
5 |
Exact |
4 |
Excellent |
3 |
High |
2 |
Moderate |
1 |
Weak |
By default, only record pairs with a pairwise comparison score of exact, excellent or high are kept.
Important
Records are scored based on a number of features, including:
String matching patterns, such as Levenshtein and Jaro-Winkler distances, and Jaccard similarity
Commonality statistics that focus on name distributions
Name matching, including for nicknames, combined with addresses and phone numbers
Lookup tables
Comparisons are made across a broad set of categories, including names, birthdates, email addresses, physical locations, and phone numbers.
Category |
Comparisons |
|---|---|
Names |
|
Birthdates |
|
Email addresses |
|
Physical locations |
|
Phone numbers |
|
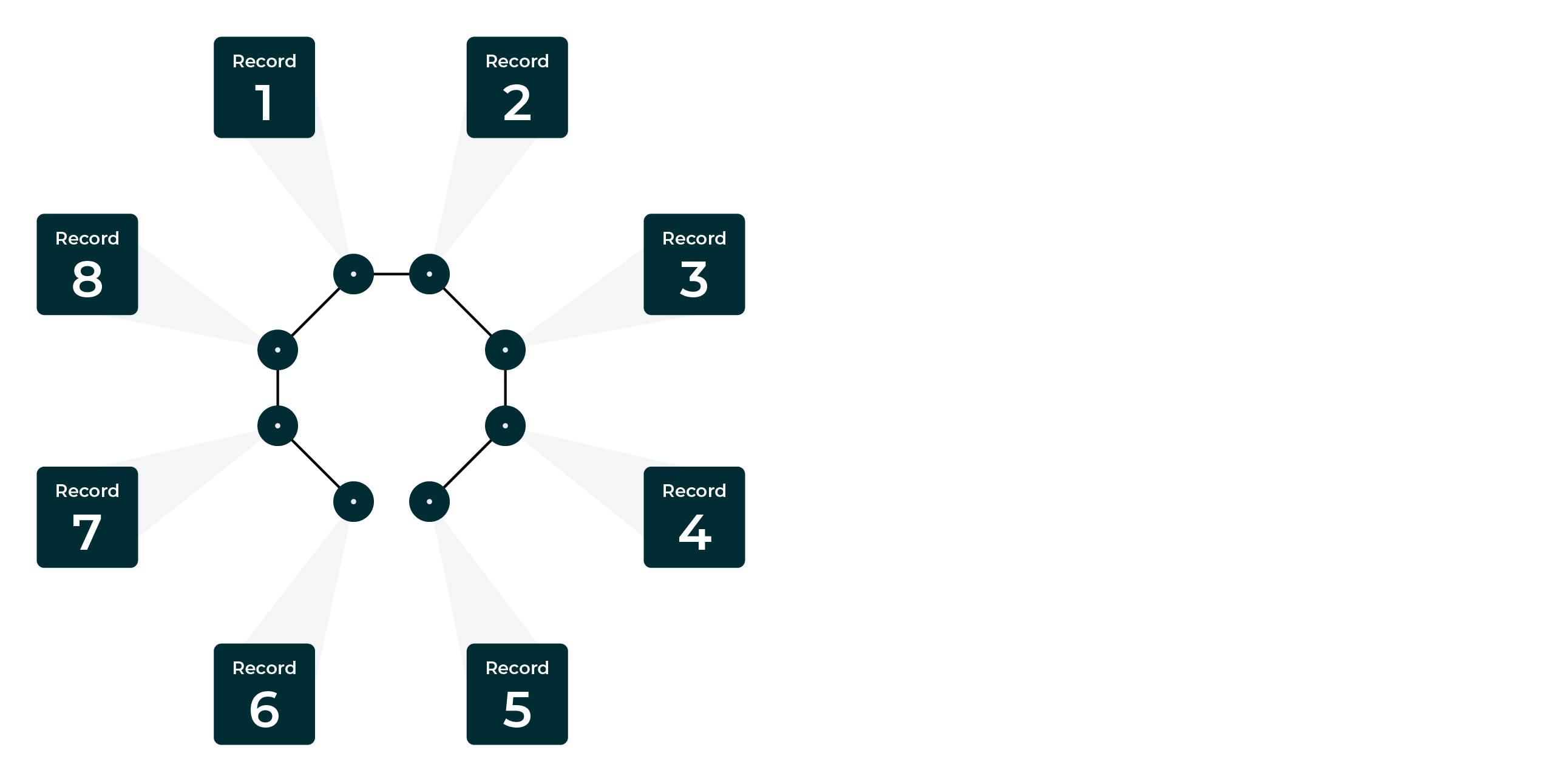
Potential connections¶
The pairwise comparison process goes beyond initial scoring to compare and then score all of the possible connections between all of the records that belong to the same group.
A group of eight records shows how pairwise comparisons work. A line between records will indicate the threshold for the comparison that was discovered.
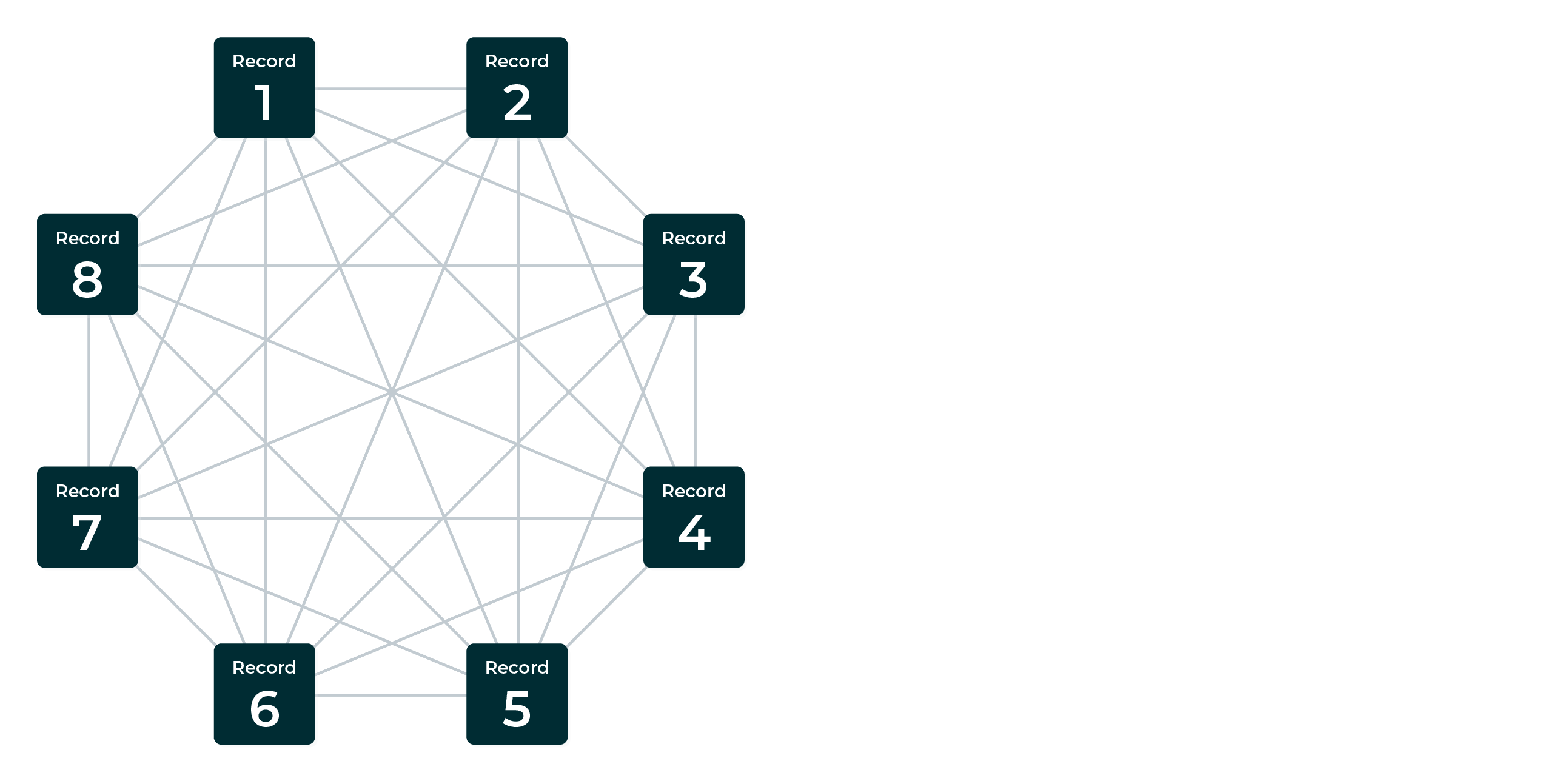
This example shows the start of the pairwise comparison process and zero connections.
Exact matches¶
An exact match score is applied to records in which all profile data matches or when a foreign key is present for both pairs and the associated values are identical.
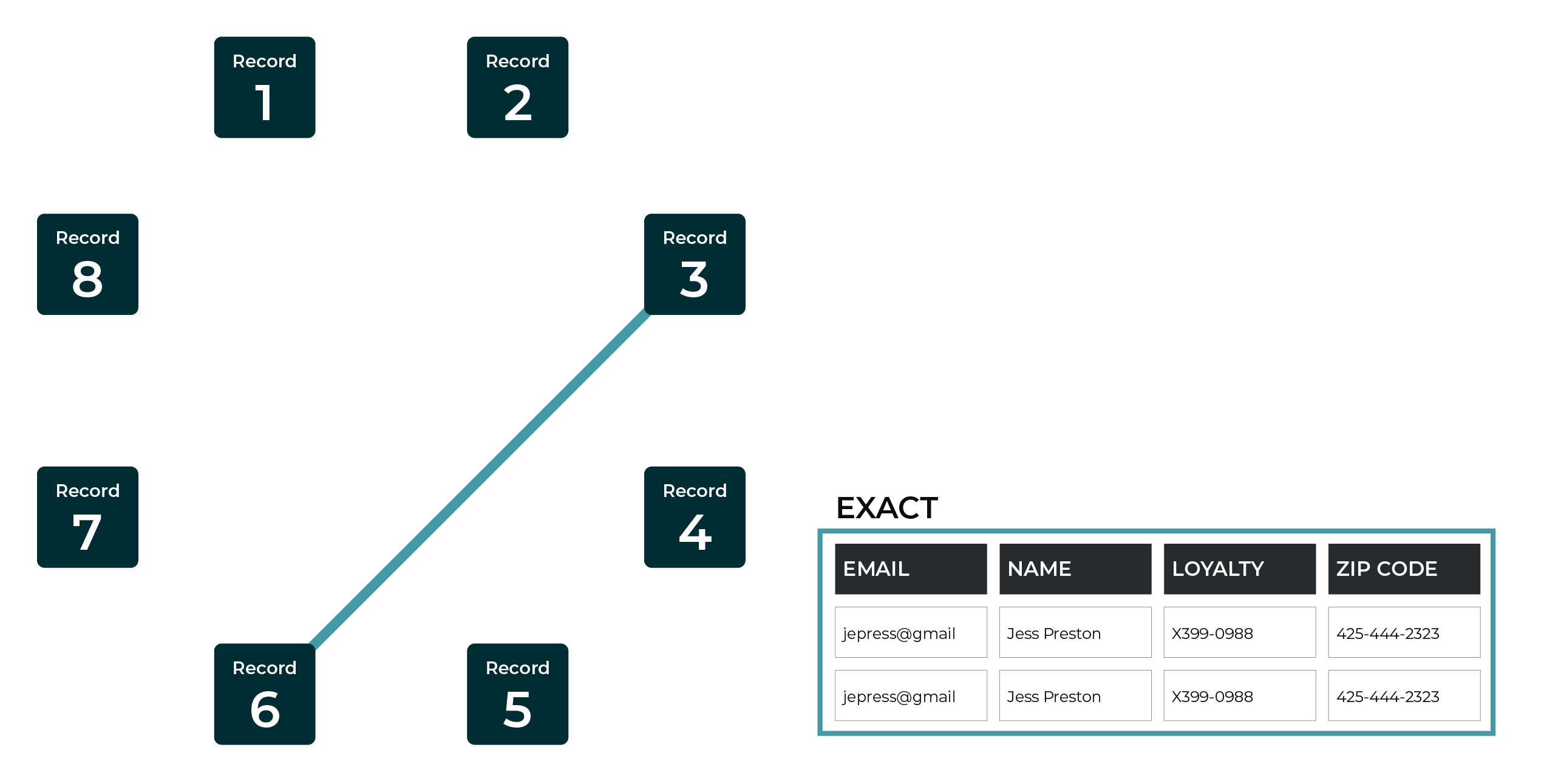
This example shows an exact match between two records.
Excellent matches¶
An excellent match score is applied to records that, even with certain types of profile data not matching, are an obvious match.
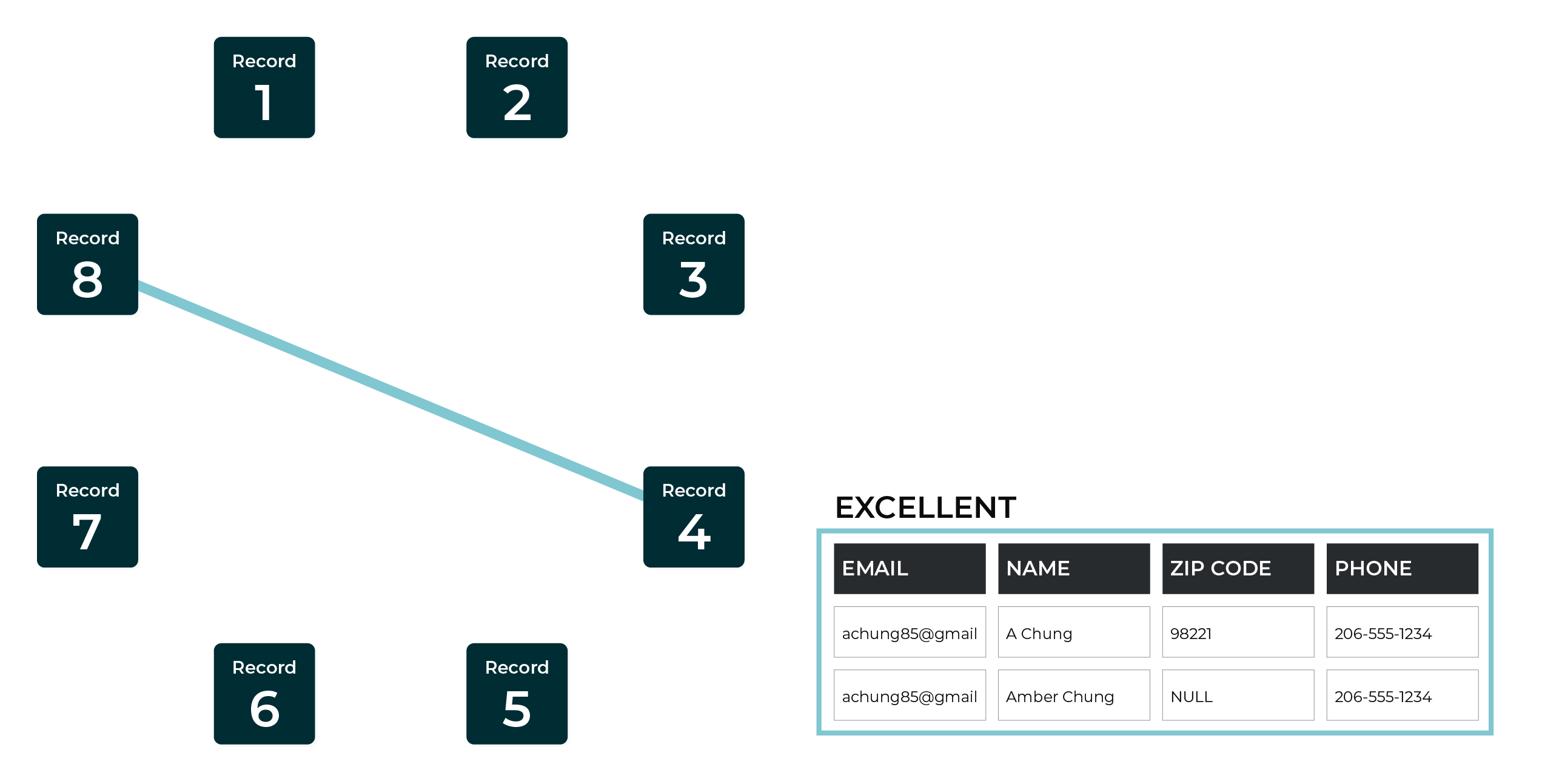
This example shows an excellent match between two records.
High matches¶
A high match score is applied to records that, even with some profile data not matching, after some deductive reasoning, appear to be records that match.
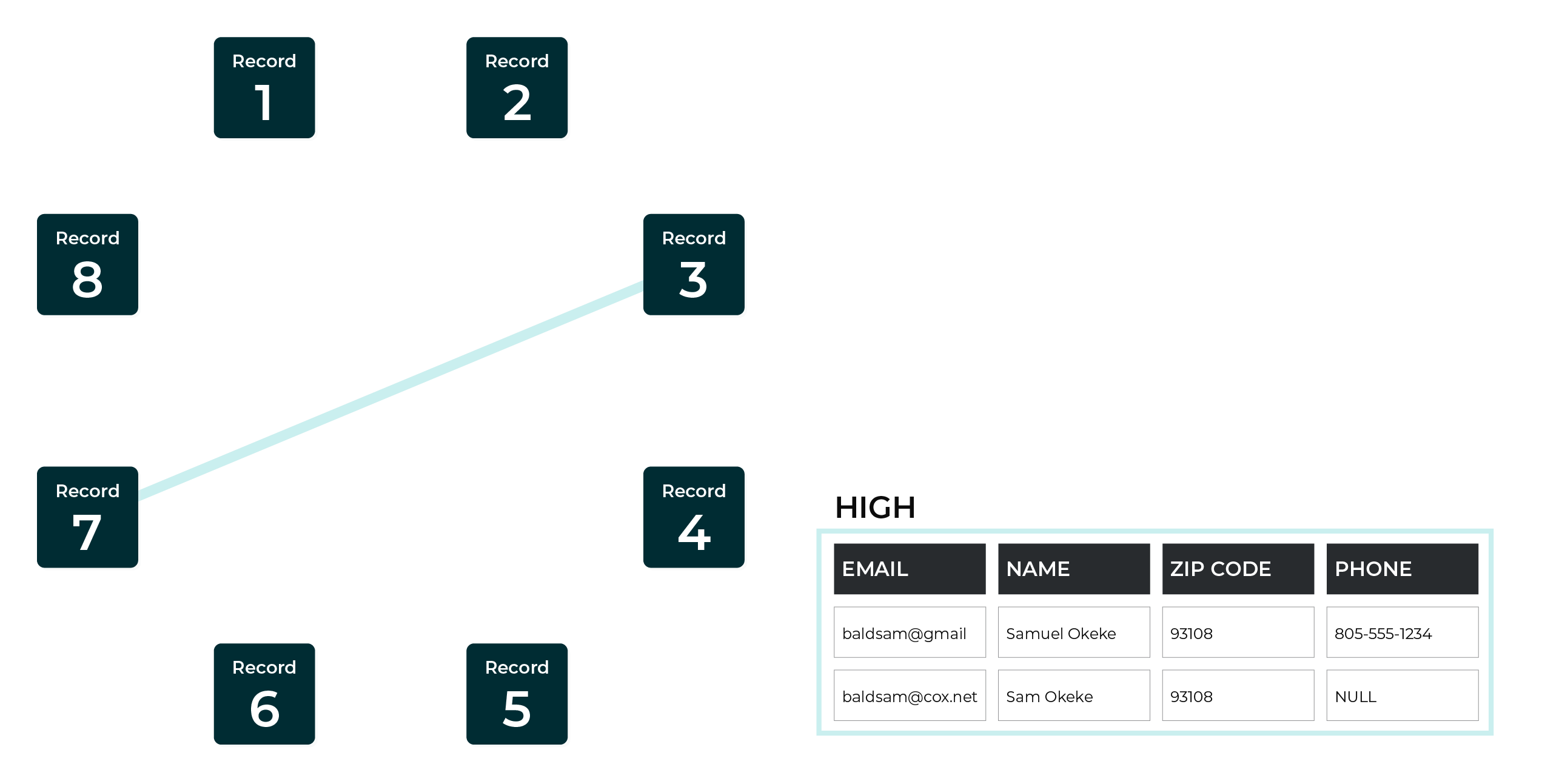
This example shows a high match between two records. The last names and ZIP codes are exact matches. The first names do not match, but do share a common nickname. The email addresses do not match, but are identical before the @ symbol.
Moderate matches¶
A moderate match score is applied to records that have weak or fuzzy matches between highly unique customer attributes, such as email, phone, and address.
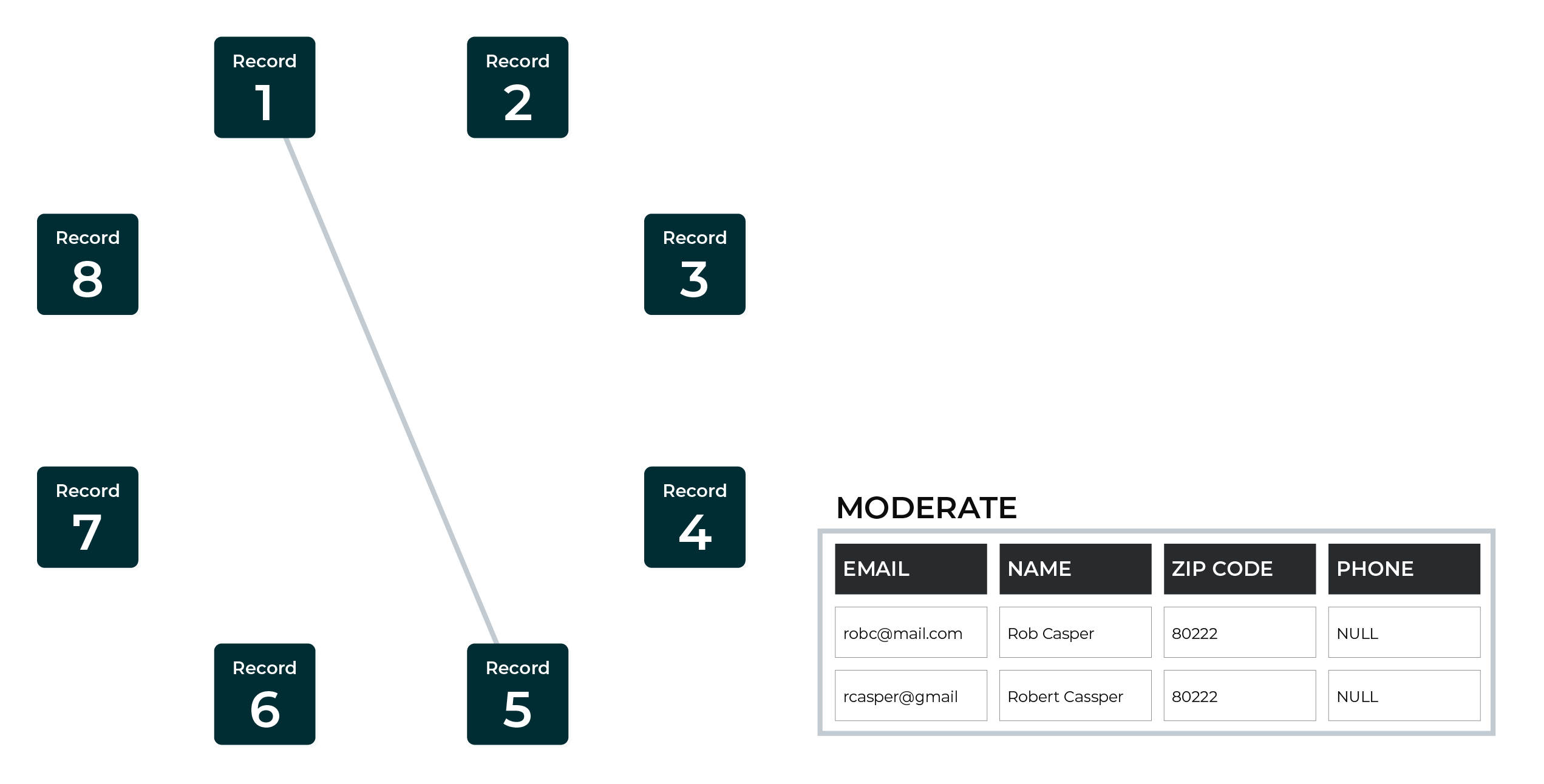
This example shows a moderate match between two records.
Weak matches¶
A weak match score is applied to records that match on non-unique customer attributes, such as name, state, and ZIP code, but cannot be easily associated with the same unique individual.
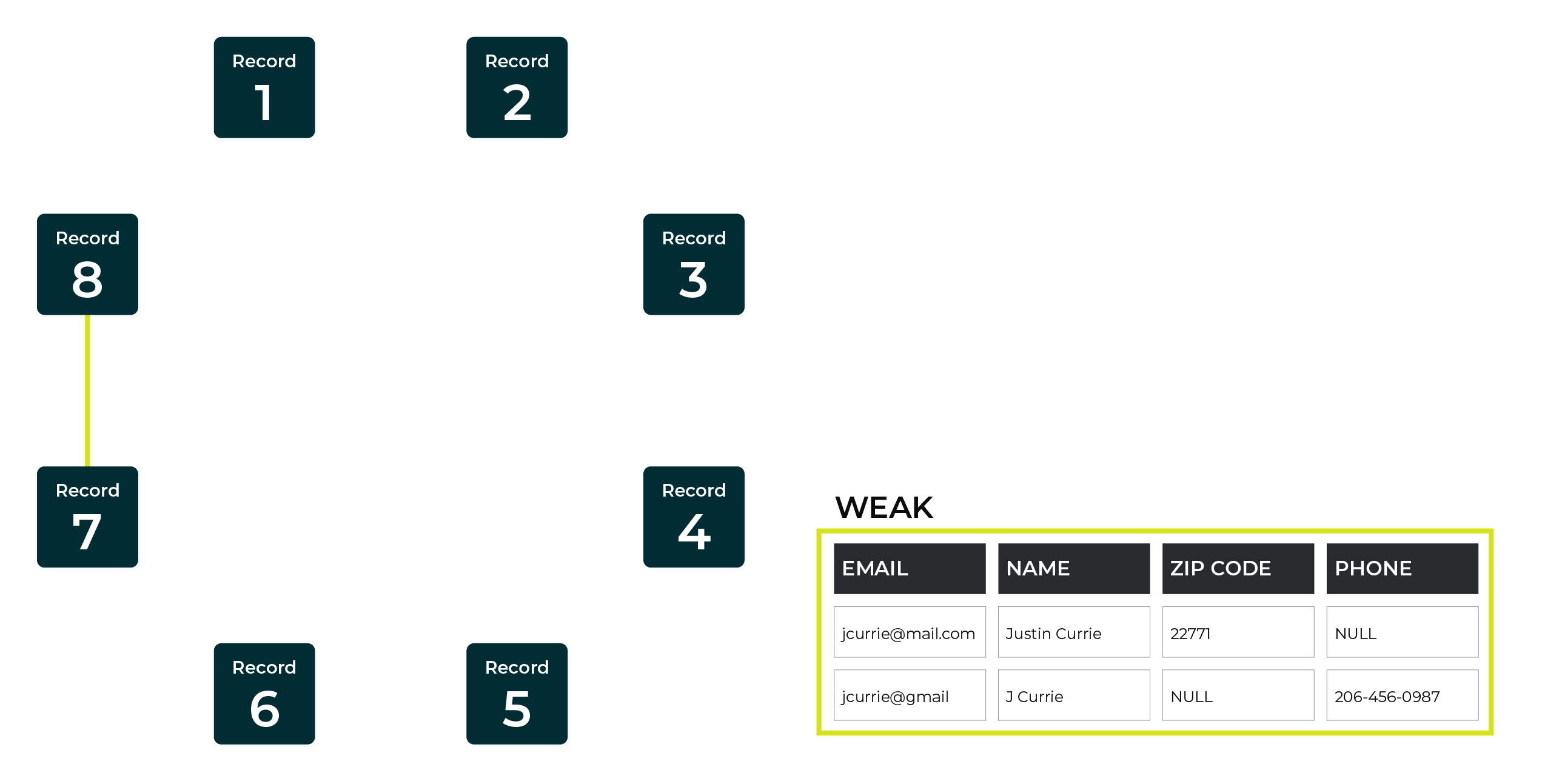
This example shows a weak match between two records.
Non-match¶
A non-matching score is applied to records in which core profile data between records does not match or when a separation key is present for both pairs and the associated values are conflicting.
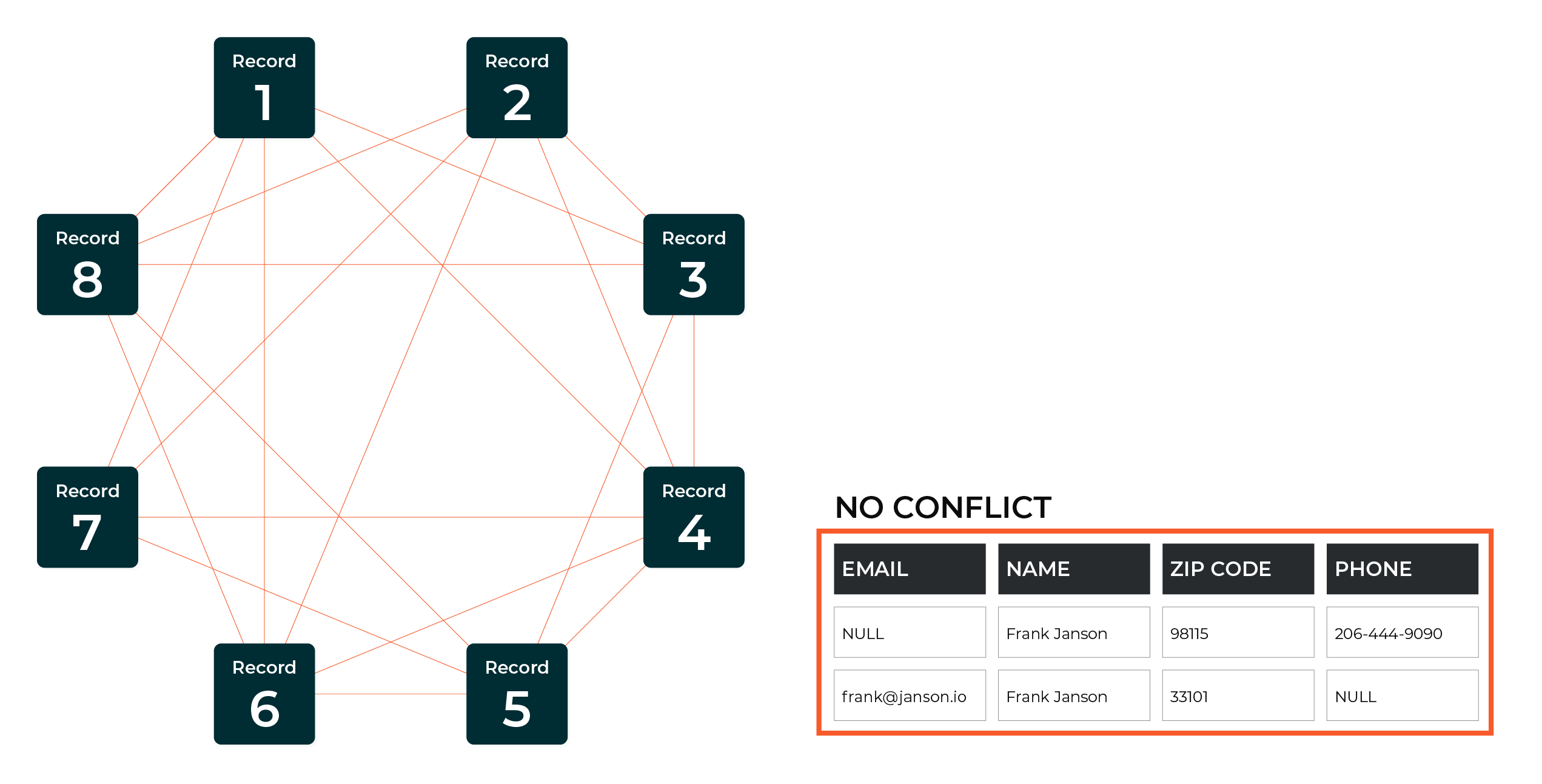
This example shows non-matching scores between two records.
All connections¶
After pairwise comparisons are completed and scored, the connections that scored below threshold (moderate, weak, and non-matching) are dropped. What remains is a group of records that identifies a unique person and to which an Amperity ID is assigned.
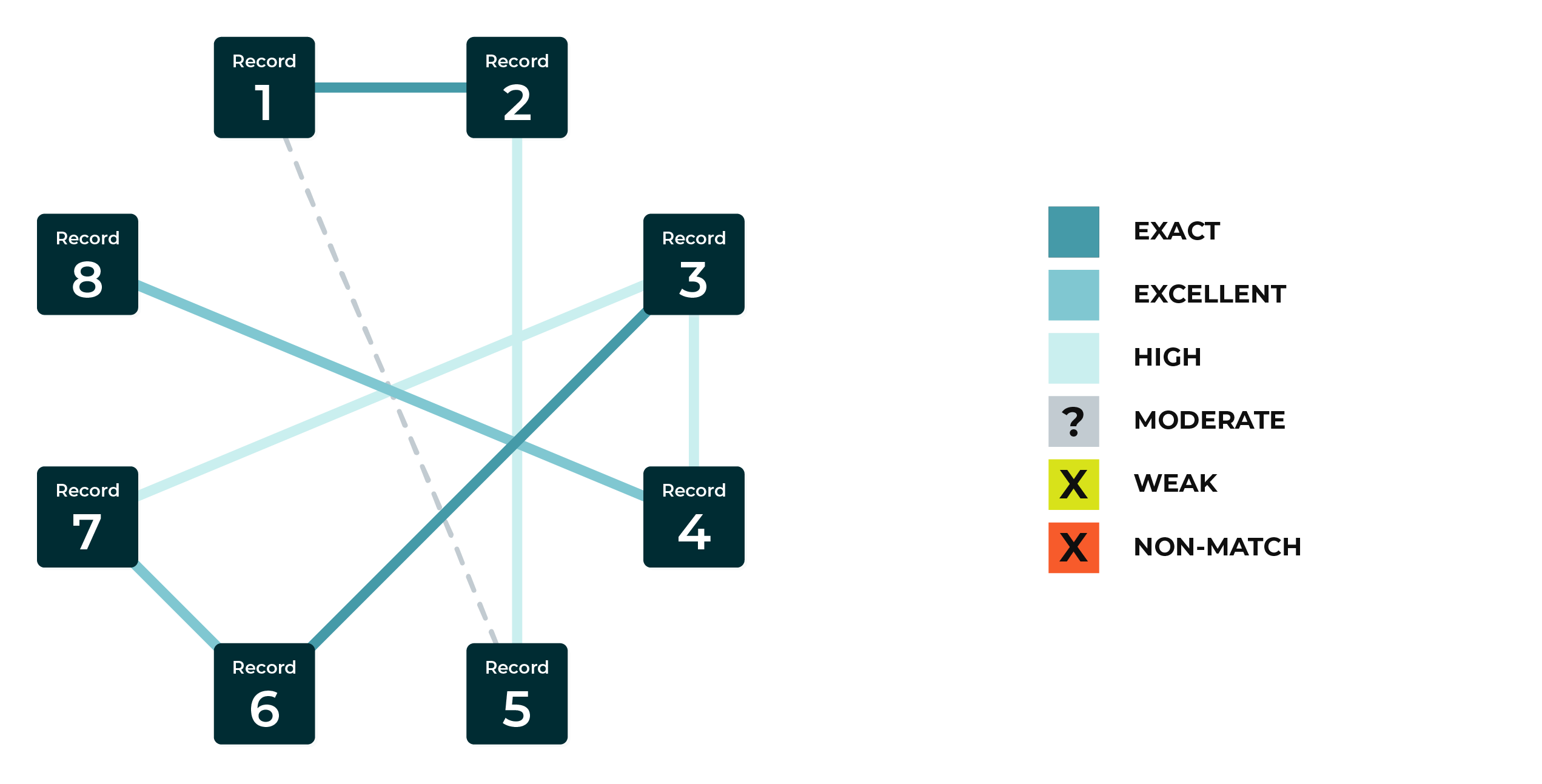
This example shows all of the pairwise comparisons that scored above threshold (exact, excellent, and high). The score at which record pairs fall below threshold is configurable. Moderate is the default threshold at which record pairs are dropped.
Hierarchical comparison¶
Hierarchical comparison is a step during identity resolution that occurs after scoring. Hierarchical comparison examines each group of records and tries to identify potential conflicts. For example, married couples with overlapping profile (PII) data or children with the same name as a parent who live at the same address.
A hierarchical comparison that identifies enough conflicting data allows Amperity to assert that a group of records should be split into two or more groups of records.
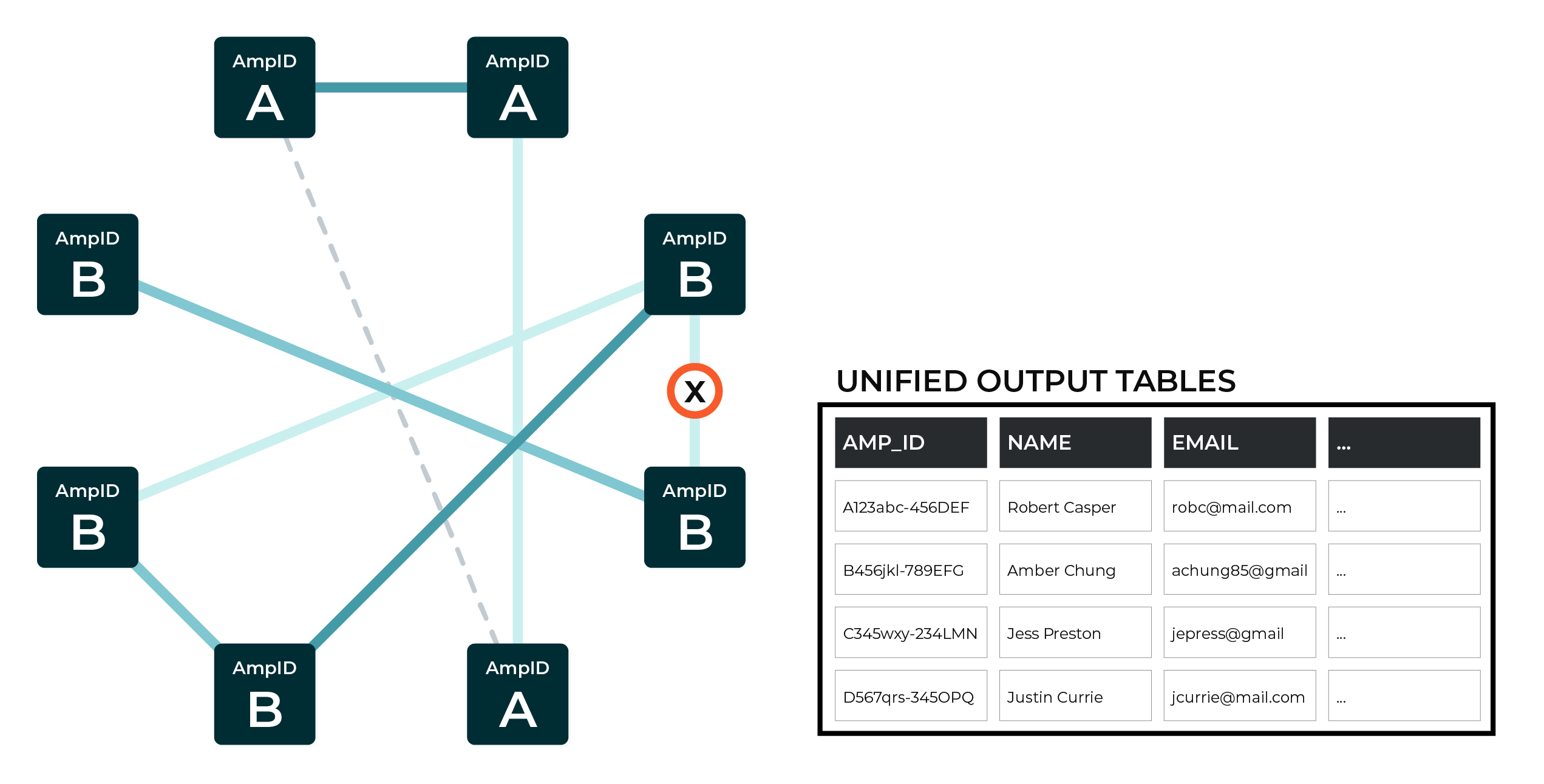
This example shows a group of records (shown in the diagram as record set B) that has been identified by hierarchical comparison to represent two individuals, after which they are split into two groups of records (shown in the diagram as record sets B1 and B2).
Stable ID assignment¶
An Amperity ID is a patented unique identifier that is assigned to clusters of customer records. A single Amperity ID represents a single individual. Unlike other systems, the Amperity ID is reassessed every day for the most comprehensive view of your customers.
Important
Stable ID assignment is about minimizing unnecessary changes in Amperity ID assignment to customer records over time.
As new data is input to Amperity, the Stitch process identifies when new or changed data applies to existing clusters of customer records, and then updates those records, maintains the cluster, and retains a stable Amperity ID assignment. A new Amperity ID is only created when new individuals are identified.
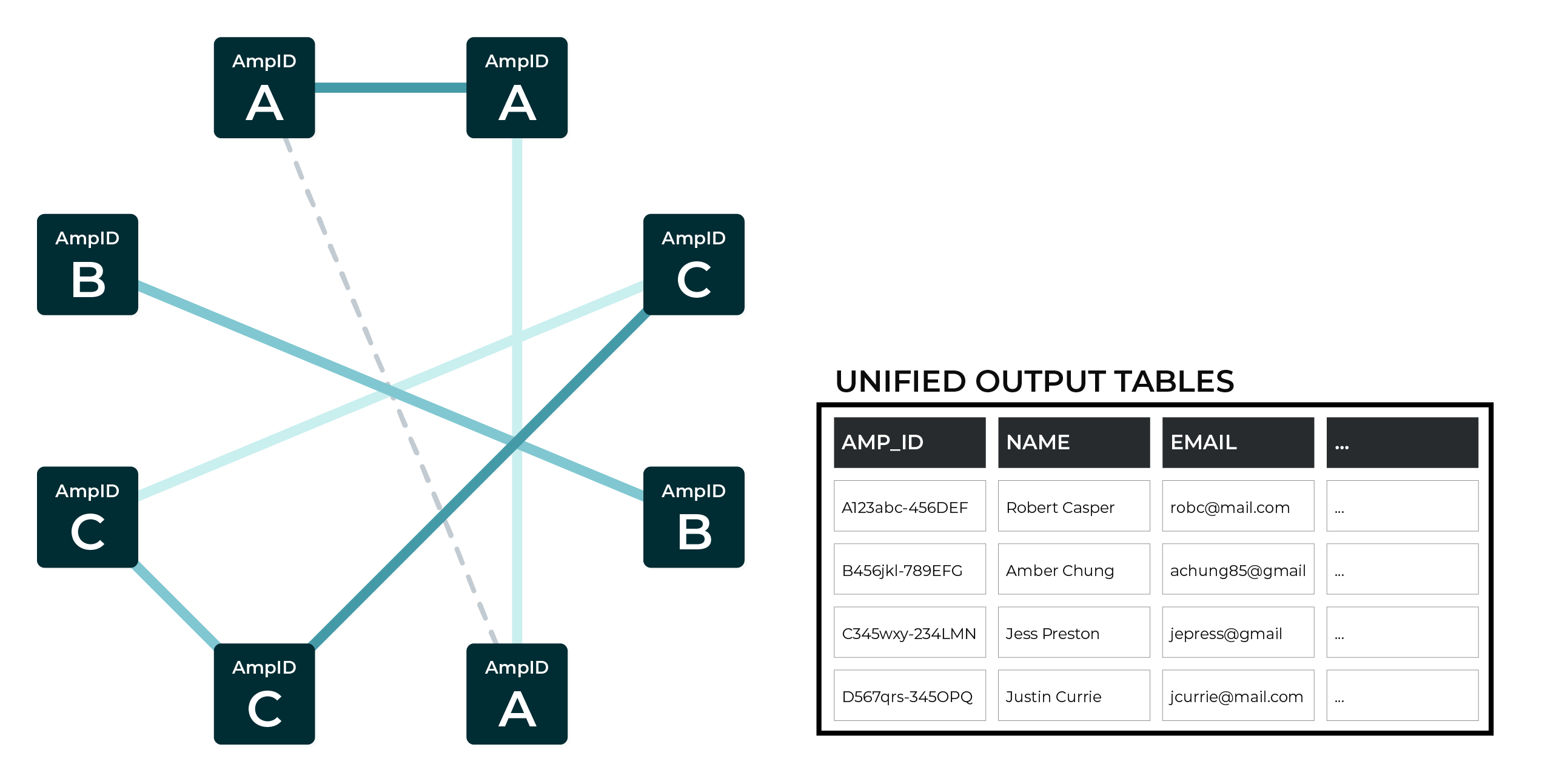
This example shows three unique clusters of records, each of which were assigned an Amperity ID.
Note
In some cases, the Amperity ID that is assigned to a cluster does change. This is referred to as jitter and it occurs when new data forces the reassignment of the Amperity ID. For example, a single cluster of records for a customer named Frank Janson. Amperity is provided new data that allows Stitch to identify that there are two Frank Jansons. One is Frank Janson Sr. and the other is Frank Janson Jr. Stitch results shows jitter when the Amperity ID assignment is updated to reflect the correct association of customer records.
Your data, your customers¶
Amperity accurately identifies all of your unique customers in your data. All of your unique customers are assigned an Amperity ID.
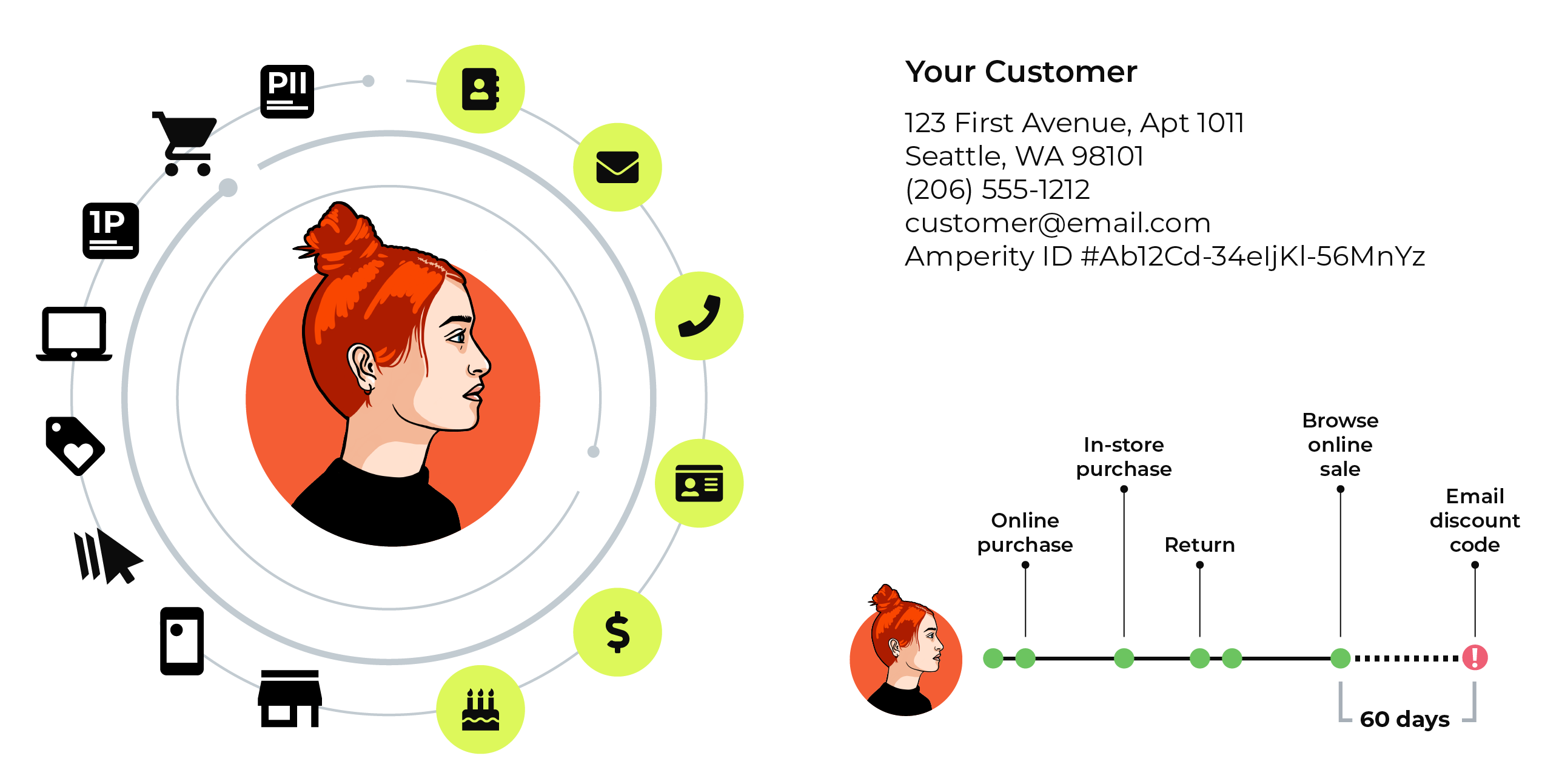
Use the Amperity ID to understand how your customers have interacted with your brands and to determine the best ways your company can identify your best and most valuable customers and continue to engage with them.