About courier groups¶
A courier group is a list of one or more couriers that run as a group. A courier group can act as a constraint on downstream workflows and can run automatically as part of a scheduled workflow.
A courier group is typically configured to run automatically on a recurring schedule. All couriers within a courier group run as a unit. Couriers with required files must complete before any downstream processes, such as Stitch or database generation, can be started.
For each courier with required files, Amperity determines if those files have updates, and then pulls updated files to Amperity. Depending on the run type, Amperity may then run Stitch and generate or refresh a customer 360 database. Orchestrations, recurring campaigns, and Profile API indexes may be configured to run as part of a courier group after the customer 360 database is refreshed.
What a courier group does:
Logically organizes a list of couriers and bridges into a group that shares the same schedule and workflow.
Allows for each courier to be assigned schedule variance via wait times and offsets.
Enables both automatic and ad hoc runs.
Polls each data source associated with a courier in the group to determine if data is ready to be pulled to Amperity.
Pulls source data into Amperity.
Runs Stitch and generates a customer 360 database.
Runs downstream activations, which includes orchestrations, recurring campaigns, and refreshing Profile API endpoints.
What a courier group needs:
At least one courier or bridge.
A schedule.
A run type.
Configuration for courier wait times and offsets to help ensure that all couriers assigned to the courier group have a time window that is large enough to complete data collection.
The Configured tab in the Workflows page shows the status of all courier group workflows that are configured to run automatically, including when they last ran, and its current status. The Sources page also shows the status of all courier groups.
Add a courier group¶
Use the Add courier group button to add a courier group to Amperity. A courier group should be created to consolidate individual couriers into a scheduled courier group.
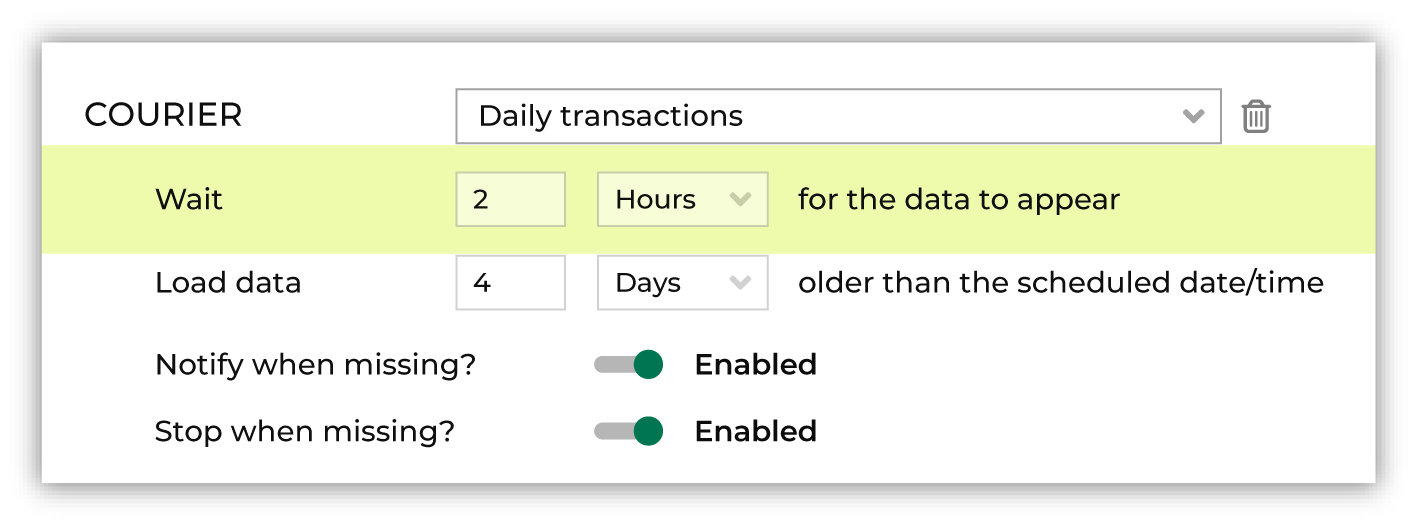
For each courier added to a courier group, define a wait time and the number of days to look for data. This is used to help determine how much time the courier group should wait for the files associated with a courier to be ready for processing.
In some cases, if the files are not ready, the courier workflow fails, but in other cases, if the files in the courier are not flagged as required, the courier group may continue processing the rest of the files.
To add a courier group

|
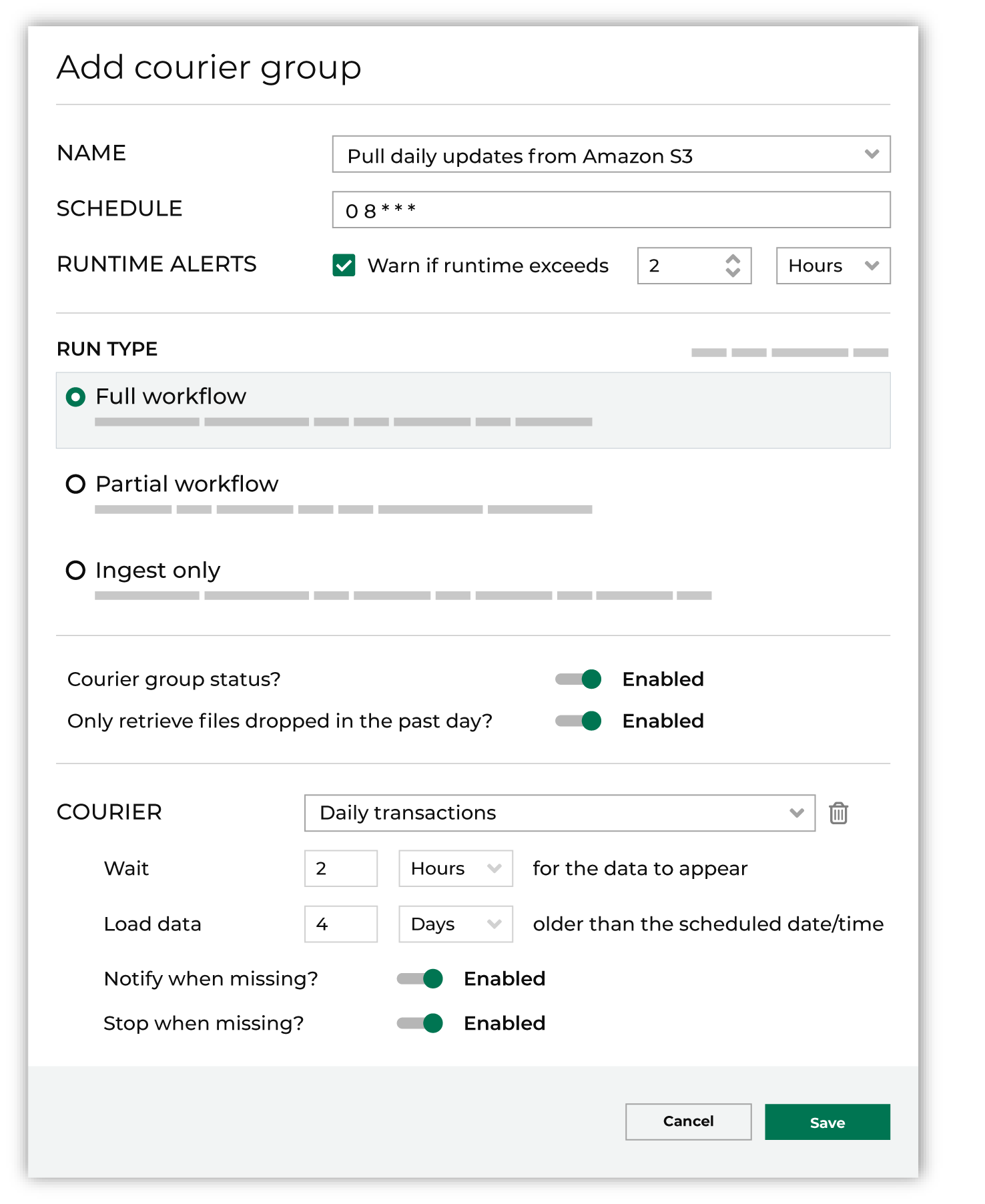
From the Sources page, click Add courier group. This opens the Edit courier group dialog box. Add a name for the courier group. 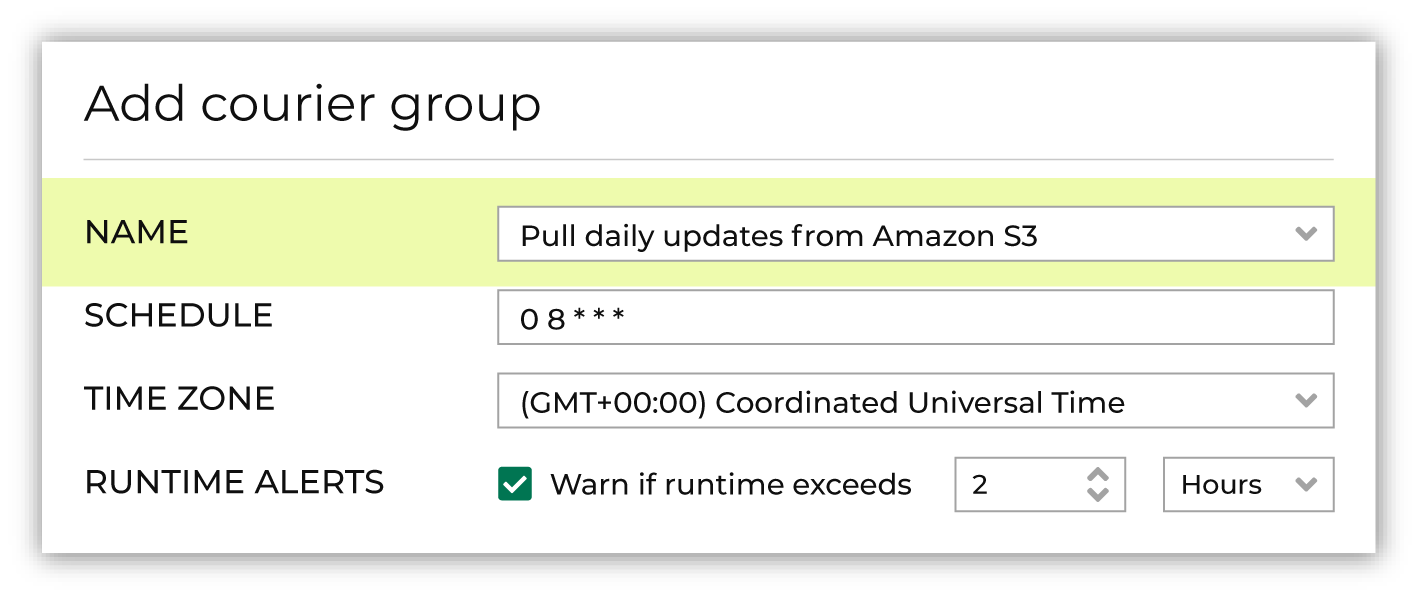
|

|
A schedule defines the frequency at which a courier group runs. All couriers in the same courier group run as a unit and all tasks must complete before a downstream process starts. Define a schedule using cron. 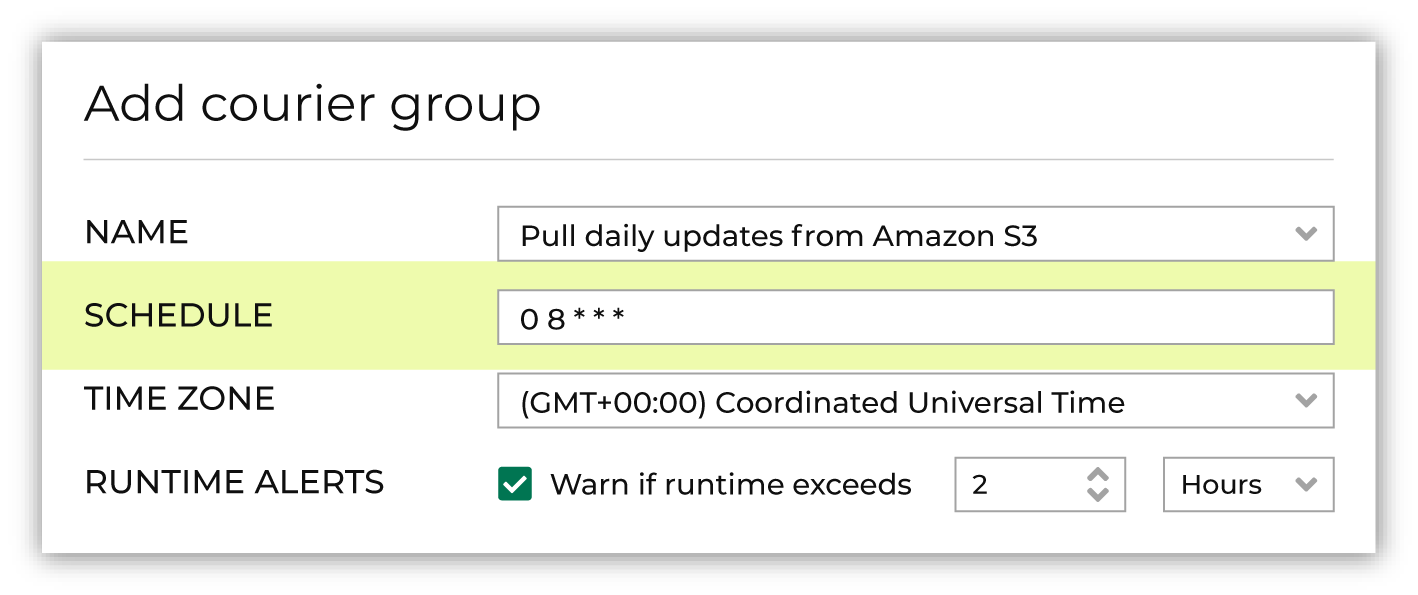
Use a cron string to define a schedule for the courier group. Tip Daylight savings time can affect a schedule. Be sure to set the schedule to be stable and not require changes over time. For example: if a schedule is set to 12:30 AM, and then you fall back, the schedule may become 11:30 PM (fall back) or 1:30 AM (spring forward). |

|
Select a time zone. 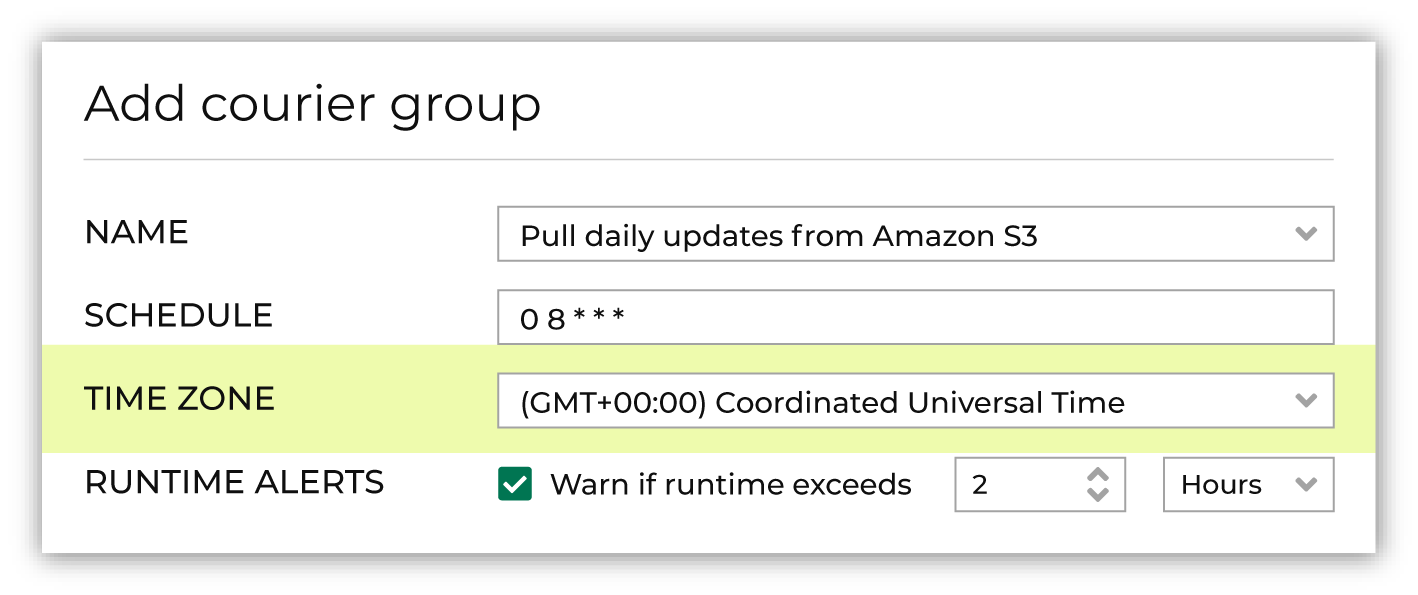
|

|
Optional. Enable runtime alerts. Enable the Alert when runtime exceeds checkbox, and then set the number of hours or minutes at which, when the configured amount of time is exceeded, an alert is sent. 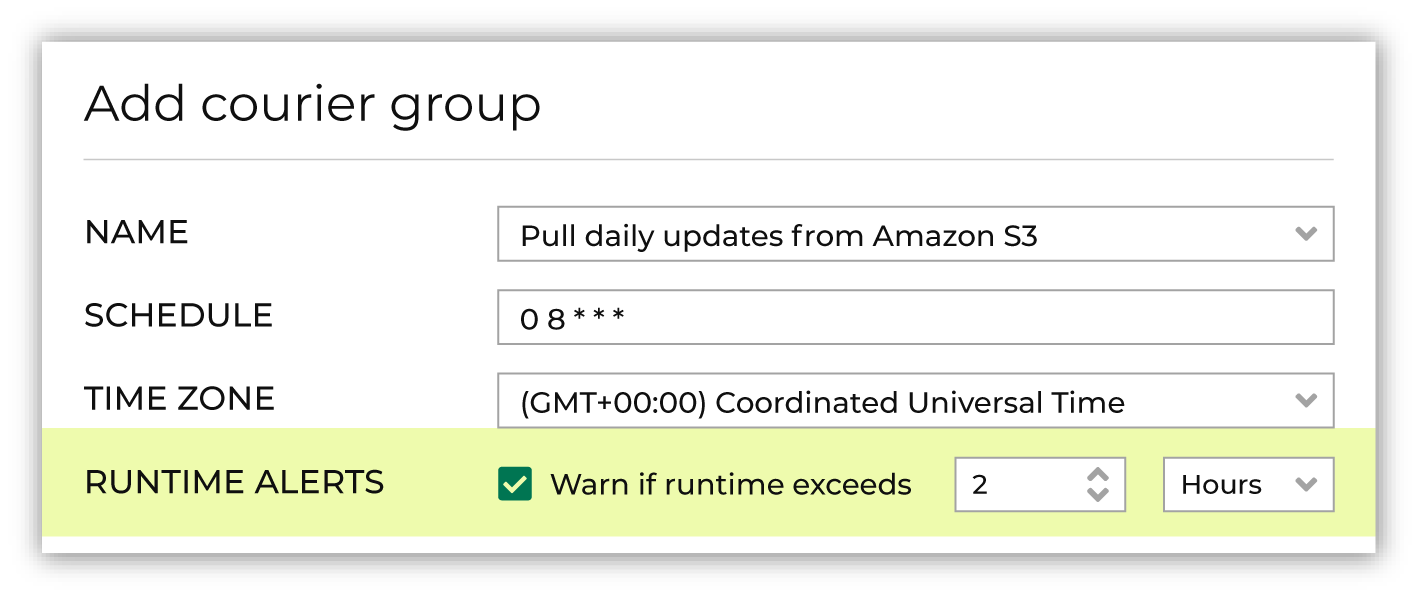
|

|
Define how the courier group runs: a Full, a Refresh, or an Source workflow. 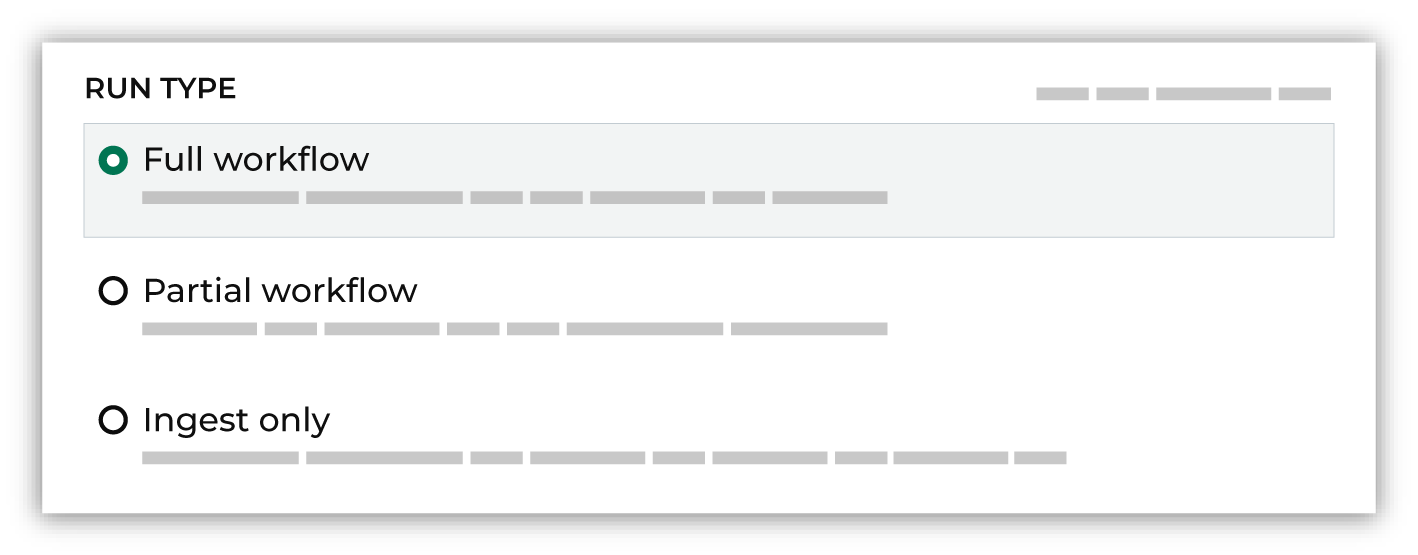
A Full workflow refreshes domain tables, runs Stitch, refreshes your customer 360 database, and then runs every activation that is configured to run as part of this courier group workflow. A Refresh workflow refreshes domain tables, runs Stitch, refreshes your customer 360 database, but does not run any activations. Important Use partial workflows in sandboxes to ensure that data in your sandbox is not inadvertently sent to downstream destinations. A Source workflow refreshes domain tables, but does not run Stitch. |

|
To enable the courier group and have it run on the configured schedule, set the courier group to Active. If this setting is set to Inactive the courier group will not run on a schedule, but may be run manually. Many courier groups are scheduled to run on a daily basis. Some courier groups are scheduled to run less frequently, such as bi-weekly, monthly, or even quarterly. Use the Only retrieve files dropped in the past day? setting to configure a courier group that runs less frequently to only look for files dropped yesterday. 
Tip A courier group that runs less frequently, such as weekly, bi-weekly, monthly, or quarterly, will look for files on each day that has passed since the last time the courier group ran. When a courier group is configured to run less frequently, you can also configure that courier group to only look for files on a specific day. To use this approach, it is recommended to configure your upstream systems to make their files available to the courier group on a schedule that ensures they will be available to the courier group within a 24-hour window. This window is based on the schedule that is defined for the courier group. Configure the courier group to run at the end of that 24-hour window, and then enable the Only retrieve files dropped in the past day? option, which forces the courier group to only look for files that were made available within the previous 24 hours. |

|
Add one or more couriers to the courier group. For each courier in the courier group, select a courier, configure the wait time and offset, and then enable alerts. 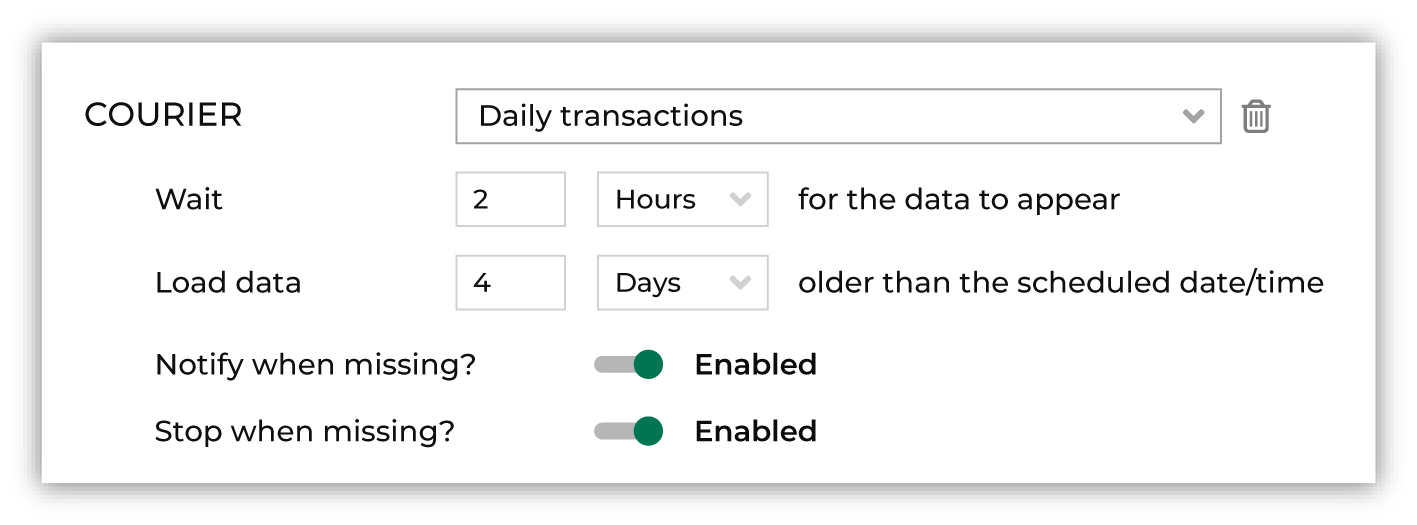
About wait times A wait time is a constraint placed on a courier group that defines an extended time window for data to be made available at the source location. Important A wait time is not required for a bridge. A courier group typically runs on an automated schedule that expects customer data to be available at the source location within a defined time window. However, in some cases, the customer data may be delayed and is not made available within that time window. Use a wait time to extend the time window for data to be made available. This can help reduce the number of alerts that may be generated for data sources that cannot be picked up by a courier group. |

|
Click Save to save the courier group. |
Courier group settings¶
A courier group can be configured for specific run types, schedules, time zones, and alerts.
Activate courier group¶
A courier group must be activated in order for it to run on an end-to-end schedule that pulls data to Amperity using couriers, syncs data using bridges, runs Stitch, refreshes databases, and then runs any orchestration, orchestration group, campaign, or profile API endpoint that is associated with the courier group.
A courier group that is deactivated may be run manually.
Courier group alerts¶
Courier groups may be configured for the following types of alerts:
Run types¶
A courier group can be configured with any of the following run types:
- Full
A full workflow refreshes domain tables, runs Stitch, refreshes your customer 360 database, and then runs every activation that is configured to run as part of this courier group workflow.
- Refresh
A refresh workflow refreshes domain tables, runs Stitch, refreshes your customer 360 database, but does not run any activations.
Important
Use partial workflows in sandboxes to ensure that data in your sandbox is not inadvertently sent to downstream destinations.
- Source
A source workflow refreshes domain tables, but does not run Stitch.
Schedules¶
A schedule defines the frequency at which a courier group runs. All couriers in the same courier group run as a unit and all tasks must complete before a downstream process starts. Define a schedule using cron.
Cron is a time-based job scheduler that uses cron syntax to automate scheduled jobs to run periodically at fixed times, dates, or intervals.
Cron syntax specifies the fixed time, date, or interval at which cron runs. Each line represents a job. 30 8 * * * represents “run at 8:30 AM every day” and 30 8 * * 0 represents “run at 8:30 AM every Sunday”.
For example:
┌───────── minute (0 - 59)
│ ┌─────────── hour (0 - 23)
│ │ ┌───────────── day of the month (1 - 31)
│ │ │ ┌────────────── month (1 - 12)
│ │ │ │ ┌─────────────── day of the week (0 - 6) (Sunday to Saturday)
│ │ │ │ │
│ │ │ │ │
│ │ │ │ │
* * * * * command to execute
Amperity validates the cron syntax and shows you the results. You may also use crontab guru to validate cron syntax.
Amperity uses cron syntax to schedule the time at which a courier group is available for transferring files from a customer data source location to Amperity. A courier group that is scheduled runs automatically. Schedules are in UTC.
Example cron schedules
columnName |
columnName |
|---|---|
0 17 * * * |
Daily at 17:00 UTC |
0 17 * * 1,3 |
Monday and Wednesday at 17:00 UTC |
0 17 * * 1-5 |
Weekly on Monday through Friday at 17:00 UTC |
0 17 * * 0 |
Weekly on Sunday at 17:00 UTC |
0 22 * * 0 |
Weekly on Sunday at 22:00 UTC |
30 15 * * 1,2,5 |
Monday, Tuesday, and Friday 15:30 PM UTC |
Note
Scheduling a courier group is optional. When a courier group is not assigned a schedule, it may be run manually on an ad hoc basis.
A courier group that is scheduled to run on a daily basis will check for files on a daily basis.
A courier group that runs less frequently, such as weekly, bi-weekly, monthly, or quarterly, will look for files on each day that has passed since the last time the courier group ran.
When a courier group is configured to run less frequently, you can also configure that courier group to only look for files on a specific day.
To use this approach, it is recommended to configure your upstream systems to make their files available to the courier group on a schedule that ensures they will be available to the courier group within a 24-hour window. This window is based on the schedule that is defined for the courier group.
Configure the courier group to run at the end of that 24-hour window, and then enable the Only retrieve files dropped in the past day? option, which forces the courier group to only look for files that were made available within the previous 24 hours.
Tip
Daylight savings time can affect a schedule. Be sure to set the schedule to be stable and not require changes over time. For example: if a schedule is set to 12:30 AM, and then you fall back, the schedule may become 11:30 PM (fall back) or 1:30 AM (spring forward).
Time zones¶
A courier group schedule is associated with a time zone. The time zone determines the point at which a courier group’s scheduled start time begins. A time zone should be aligned with the time zone of system from which the data is being pulled.
Use the Use this time zone for file date ranges checkbox to use the selected time zone to look for files. If unchecked, the courier group uses the current time in UTC to look for files to pick up.
The time zones that are available for selection in Amperity are modeled after the Google Calendar and are similar to:
(GMT-08:00) Pacific Time
(GMT-07:00) Mountain Time
(GMT-06:00) Central Time
(GMT-05:00) Eastern Time
The time zone that is chosen for an courier group schedule should consider every downstream business processes that requires the data and also the time zones in which the consumers of that data will operate.
Tip
Do not create courier group schedules that may occur during a daylight savings time transition.
For example, an courier group schedule with the cron string of 30 2 * * * and the time zone of “(GMT-08:00) Pacific Time” runs once a day most at 2:30 AM, except for one day in the spring when it will not run at all and one day in the fall when it runs twice.
This is because American daylight savings time transitions at 2:00 AM, meaning the 2:00 AM hour occurs twice when transitioning out of daylight savings time (Fall) and is skipped altogether when transitioning into daylight savings time (Spring).
Add sources¶
The following data sources may be configured to run as part of a courier group workflow:
Bridge syncs¶
Amperity Bridge enables data sharing between Amperity and data lakehouses. Each bridge can be configured for inbound and outbound shares to give you access to shared tables without replication.
Couriers¶
A courier brings data from an external system to Amperity.
Settings for couriers in a courier group workflow include:
Courier alerts¶
Files can be missing for any number of reasons, including by delays that may have occurred in upstream workflows that exist outside of Amperity. In many situations a file is late, not missing.
Individual couriers within a courier group may be configured for the following types of file-specific alerts:
Number of days¶
A courier can be configured to look for files within range of time that is older than the scheduled time. The scheduled time is in Coordinated Universal Time (UTC), unless the “Use this time zone for file date ranges” checkbox is enabled for the courier group.
This range is typically 24 hours, but may be configured for longer ranges. For example, it is possible for a data file to be generated with a correct file name and datestamp appended to it, but for that datestamp to represent the previous day because of how an upstream workflow is configured. A wait time helps ensure that the data at the source location is recognized correctly by the courier.
Warning
This range of time may affect couriers in a courier group whether or not they run on a schedule. A manually run courier group may not take its schedule into consideration when determining the date range. Only the provided input days to load data from are used as inputs.
Important
The schedule defines the frequency at which the courier group runs.
The timezone is the time at which the courier group runs. This may be set to your local time zone.
Individual courier wait times are calculated using Coordinated Universal Time (UTC), even when a non-UTC time zone is specified for the courier group. This means that when a courier group runs, the current time in UTC is used to calculate the wait time.
When a courier group is set to your local time zone, you must consider the offset for your local time zone when defining the wait time for each courier in the courier group.
Wait times¶
A wait time is a constraint placed on a courier group that defines an extended time window for data to be made available at the source location.
Important
A wait time is not required for a bridge.
A courier group typically runs on an automated schedule that expects customer data to be available at the source location within a defined time window. However, in some cases, the customer data may be delayed and is not made available within that time window.
Use a wait time to extend the time window for data to be made available. This can help reduce the number of alerts that may be generated for data sources that cannot be picked up by a courier group.
Note
For couriers associated with a filedrop location the default wait time is 0. A polling operation only checks for a data source before declaring success or failure. For couriers associated with REST APIs and data warehouses, the polling operation is always considered to be successful.
A downstream process begins after each load operation is completed for each data source associated with each courier in the courier group and each domain table has been updated.
Review activations¶
An activation represents a part of a workflow that is run after databases have been updated. Any number of activations may be assigned to a workflow, after which all activations are run automatically on the schedule that is defined by the workflow.
Individual queries and data exports, orchestration group, Profile API endpoints, and recurring campaign may all be assigned to a workflow as an activation.
How-tos¶
Tasks related to managing courier groups in Amperity:
Activate courier group¶
An activated courier group is run automatically on a defined schedule. All couriers and bridges that are configured for the courier group run as a unit and are used to run Stitch and refresh the customer 360 database. All orchestrations, orchestration groups, recurring campaigns, and profile API endpoints that are configured for the courier group are run automaticaly after the database is refreshed.
To activate a courier group
From the Sources page, open the menu for a courier group, and then select Edit.
On the General tab, change Inactive to Active.
Click Save.
Add bridge to workflow¶
Any inbound share that has been configured and activated in your tenant may be added as a bridge within a courier group.
To add a bridge to a courier group
From the Sources page, open the menu for a courier group, and then select Edit.
On the Bridges tab, click the Add bridge link, and then select a bridge from the dropdown list.
Click Save.
Add courier to workflow¶
For each courier that is added to a courier group, do the following:
Add courier¶
A courier brings data from an external system to Amperity.
To add a courier to a courier group
From the Sources page, open the menu for a courier group, and then select Edit.
On the Couriers tab, click the Add courier link.
Select the name of a courier from the dropdown list, set the wait time and range for which data is loaded. Enable alerts for when files are missing.
Click Save.
Set wait time¶
A wait time is a constraint placed on a courier group that defines an extended time window for data to be made available at the source location.
To set the wait time for a courier
From the Sources page, open the menu for a courier group, and then select Edit.
On the Couriers tab, click the Add courier link.
Select the name of a courier from the dropdown list.
Next to Wait add an integer value and then select Seconds, Minutes, Hours, or Days to represent the amount of time a courier should wait for data.
Click Save.
Set the number of days¶
Each courier in a courier group may be configured to look for data during a time window. This is typically in “days” but may be “minutes”, “hours”, or “weeks”. For example: “Load data 2 days older than the scheduled date and time.”
To set the number of days for which data is pulled
From the Sources page, open the menu for a courier group, and then select Edit.
On the Couriers tab, click the Add courier link.
Select the name of a courier from the dropdown list.
Next to Load data add an integer value and then select Minutes, Hours, Days, or Weeks to represent the amount of time older than the scheduled date and time for which the courier will look for data.
Click Save.
Alert when data is missing?¶
A courier group can be configured to send workflow alerts when one or more files are missing, and then continue processing if files are missing.
Tip
Some files are not considered essential to the daily Amperity run. The reasons why a particular file may be considered non-essential varies from tenant to tenant, but they may include situations like:
A data source is static
A data source does not contain PII that will affect the quality of the Amperity ID.
A data source is associated with a workflow that often misses the configured Amperity wait time period.
To alert when data is missing?
From the Sources page, open the menu for a courier group, and then select Edit.
On the Couriers tab, under the name of a courier group, set Notify when missing? to enabled, and then set Stop when missing? to disabled.
Click Save.
Stop when data is missing?¶
A courier group can be configured to send workflow alerts when one or more files are missing, and then stop processing if files are missing.
To stop when data is missing?
From the Sources page, open the menu for a courier group, and then select Edit.
On the Couriers tab, under the name of a courier group, set Notify when missing? to enabled, and then set Stop when missing? to enabled.
Click Save.
Add data export to courier group¶
A data export that is added to an orchestration group that has been configured to run automatically may be configured to run as part of a courier group workflow.
Add orchestration to courier group¶
An orchestration that is added to an orchestration group that has been configured to run automatically may be configured to run as part of a courier group workflow.
Add orchestration group to courier group¶
An orchestration group may be configured to run as part of a courier group workflow.
Add Profile API endpoint to courier group¶
A Profile API endpoint that is configured to run after a courier group may be configured to run as part of a courier group workflow.
Add query to workflow¶
A query that is added to an orchestration group that has been configured to run automatically may be configured to run as part of a courier group workflow.
Add recurring campaign to workflow¶
A campaign that is configured as a recurring campaign may be configured to run as part of a courier group workflow.
Copy courier group¶
Use the Copy option to copy a courier group to Amperity.
To copy a courier group
From the Sources page, open the menu for a courier group, and then select Make a copy.
On the Copy courier group window, enter the courier group name into the Courier group name field.
Click Save.
The copied courier group appears in the list of courier groups on the Sources page.
Deactivate workflow¶
A deactivated workgroup does not run automatically or on a schedule. It may be run manually.
To deactivate a courier group
From the Sources page, open the menu for a courier group, and then select Edit.
On the General tab, change Active to Inactive.
Click Save.
Define schedule¶
Amperity uses cron syntax to schedule the time at which a courier group is available for transferring files from a customer data source location to Amperity. A courier group that is scheduled runs automatically. Schedules are in UTC.
Note
Scheduling a courier group is optional. When a courier group is not assigned a schedule, it may only be run manually on an ad hoc basis.
To define a schedule for a courier group
From the Sources page, open the menu for a courier group, and then select Edit.
On the General tab, use the Schedule field to configure a schedule using cron syntax.
Optional. Choose a time zone and indicate of the selected time zone should be used as the time from which the number of days to look back is determined.
Click Save.
Delete courier group¶
Use the Delete option to remove a courier group from Amperity. Verify that both upstream and downstream processes no longer depend on this courier group before deleting it.
Important
This action will not delete couriers that are associated with the courier group.
To delete a courier group
From the Sources page, open the menu for a courier group, and then select Delete.
Click Delete to confirm.
Edit courier group¶
You can change the configuration settings for any courier group.
To edit a courier group
From the Sources page, open the menu for a courier group, and then select Edit.
Make your changes.
Click Save.
Notify when courier group runs slowly¶
A runtime alert is a type of workflow alert that is sent when a courier group has run longer than a configured amount of time. A runtime alert is sent to any email address or Slack channel that is configured for the Courier group workflow type.
To notify when a courier group runs slowly
From the Sources page, open the menu for a courier group, and then select Edit.
Enable the Alert when runtime exceeds checkbox, and then set the number of hours or minutes at which, when this amount of time is exceeded, a workflow alert is sent.
Click Save.
Pull files for previous 24 hours?¶
A courier group that runs less frequently, such as weekly, bi-weekly, monthly, or quarterly, will look for files on each day that has passed since the last time the courier group ran.
When a courier group is configured to run less frequently, you can also configure that courier group to only look for files on a specific day.
To use this approach, it is recommended to configure your upstream systems to make their files available to the courier group on a schedule that ensures they will be available to the courier group within a 24-hour window. This window is based on the schedule that is defined for the courier group.
Configure the courier group to run at the end of that 24-hour window, and then enable the Only retrieve files dropped in the past day? option, which forces the courier group to only look for files that were made available within the previous 24 hours.
To pull files only for the previous 24 hours?
From the Sources page, open the menu for a courier group, and then select Edit.
On the Couriers tab, enable the Only retrieve files dropped in the past day? option.
Click Save.
Remove bridge from courier group¶
Any inbound share that has been configured and activated in your tenant and has been configured as a bridge in a courier group may be removed.
To remove a bridge from a courier group
From the Sources page, open the menu for a courier group, and then select Edit.
On the Bridges tab, find the bridge that is to be removed, and then click the trashcan icon.
Click Save.
Remove courier from courier group¶
A courier may be removed from a courier group.
To remove a courier from a courier group
From the Sources page, open the menu for a courier group, and then select Edit.
On the Couriers tab, find the courier that is to be removed, and then click the trashcan icon.
Click Save.
Run courier groups¶
A courier group may be run in the following ways:
Automatically¶
A courier group with a schedule runs automatically when the courier group is activated.
For a date range¶
A courier group can be configured to load all data for a specific date range.
To run a courier group for a date range
From the Sources page, open the menu for a courier group, and then select Run. The Run courier group page opens.
Select Load data from a specific time period.
Select a start date and an end date.
To prevent downstream processing, select Load only.
Click Run.
For a specific day¶
A courier group can be configured to load all data for a single day.
To run a courier group for a specific day
From the Sources page, open the menu for a courier group, and then select Run. The Run courier group page opens.
Select Load data from a specific day, and then select a day.
To prevent downstream processing, select Load only.
Click Run.
For all data¶
A courier group can be configured to load all data that is available. This can be a large amount of data if the courier group is running for the first time.
To run a courier group for all data
From the Sources page, open the menu for a courier group, and then select Run. The Run courier group page opens.
Select Load all data.
To prevent downstream processing, select Load only.
Click Run.
Manually¶
Use the Run option to run a courier group manually.
To run a courier group manually
From the Sources page, open the menu for a courier group, and then select Run. The Run courier group page opens.
Select the time period for which data is loaded and indicate if downstream processes should be started automatically.
Click Run.
Wait for missing files¶
When files are missing or late, in addition to sending an email alert and either continuing or stopping the workflow, Amperity will continue to attempt to find these files. Use the Wait setting to configure amount of time Amperity should wait: