About domain tables¶
A source domain table exists for each data source loaded to Amperity. Apply semantic tags to fields in source domain tables for customer profiles, transactions, loyalty programs, and customer events.
The Domain Tables section of the Sources page lists the domain tables that have been generated by feeds. Each row shows the name of the domain table, the type of record contained within that domain table (customer or interaction), and the number of columns.
Column types¶
Type |
Description |
|---|---|
Boolean |
A value that represents an either/or, such as true or false, yes or no, 0 or 1, true or NULL. |
date |
An ISO-8601 compliant date values, such as a birthdate. For example:
|
datetime |
An ISO-8601 compliant date and time values, such as a purchase or transaction, the time at which data was last updated, or a campaign launch date. For example:
Important Some fields that store datetime values are set to the string data type. |
decimal |
A fixed point number, such as for prices or message sizes. (The number of characters in the decimal value is configurable during feed setup.). For example:
|
float |
A floating point number. (Use decimal for prices.) For example:
|
integer |
A numeric value, such as the quantity of items purchased. (Use decimal for prices.) For example:
|
string |
A sequence of characters, such as first and last names, email addresses, physical addresses, UUIDs and other IDs, phone numbers, ZIP codes, product names, and descriptions. May be empty. For example:
|
Record types¶
The following types of data are often present in domain table data:
Note
An individual table may contain both customer and interaction records. As part of the Stitch process, customer records and interaction records are split into dedicated tables for use within the customer 360 database.
Customer records¶
A customer record is a row in a customer data table that has information about the customer. Who they are, where they live, and how much they spend. For example, a email list table has names, email addresses, or phone numbers.
Customer records are defined by the presence of data that can be assigned semantic tags for customer profile data, specifically to fields that contain personally identifiable information (PII).
Interaction records¶
An interaction record is a row in a customer data table that has information about customer behavior. For example:
Purchases, such as items bought, items returned, or costs of items
Preferences, such as brands, products, or cart adds
Interaction records are defined by the presence of data that can be assigned semantic tags for transactions, product catalogs, and other behavior data, such as custom semantic tags for loyalty programs.
Interaction records often require data to be reshaped using domain SQL and custom domain tables to ensure that the right combination of fields are present in the data to support components and workflows within Amperity, including functionality that is available from the Segment Brief (a component within the Segments page), predicted customer lifetime value models, and the Campaigns page.
Custom domain tables¶
Some customer data sources are only available in a state that requires the use of SQL to construct a complete record that can be made available to the Stitch process. This is often true with interaction records, which typically require some data shaping to map the data that is available in the data source to the semantic tags that are required by Amperity for transactions.
These semantic tags generate the Unified Itemized Transactions table, which is then used as the underlying reference for the Unified Transactions, Transaction Attributes, and Transaction Attributes Extended tables.
A custom domain table is built directly using Spark SQL to define a schema for that data source, after which semantic tags are applied and the primary key is identified. A custom domain table may reference other custom domain tables.
Note
When a database is run, any custom domain table that has changed is run first, and then Stitch runs. If there are no changes to custom domain tables or if custom domain tables have changed that are not configured for Stitch, Stitch will not run.
Domain SQL¶
Domain SQL reshapes data before loading it to Amperity and making that data available to downstream process, such as Stitch or customer profiles. Domain SQL uses Spark SQL to support use cases, such as building new tables from existing domain tables or reshaping data to allow correctly apply semantic tags for transactions.
Use cases¶
The following examples describe some of the more common uses cases for domain SQL:
Note
These examples are not meant to be copied and pasted, but they should work for most tenants as a good starting point.
Combine day, month, year as birthdate¶
Some data sources do not contain fields for complete birthdates and instead contain values by day, month, and year in separate fields. These individual fields must be combined to use the birthdate semantic tag.
The following example shows an IF statement within a SELECT statement that finds the values in day, month, and year fields, and then combines them into a field that captures the birthdate value as DD/MM/YYYY:
1SELECT
2 *
3 ,IF(birth_day != '0' AND birth_month != '0' AND birth_year != '0',
4 birth_month||'/'||birth_day||'/'||birth_year, NULL) AS birthdate
5FROM table
Combine five and four digit postal codes¶
Some data sources do not contain fields for complete postal codes and instead contain fields that separate the five and four digit codes. Some use cases require a single field for postal codes that includes both components, after which the postal semantic tag is applied.
The following example shows how to use a CASE statement to do the following:
Find situations where the five and four digit codes are both present, and then combine them.
Find situations where only the five-digit code is present, and then use only the five-digit code.
Uses the CONCAT_WS function to return “zip_code” and “zip_code_plus_four” separated by “-“.
Use NULL for situations where the five-digit code is not present.
Return as the postal field, to which the postal semantic tag may be applied.
1,CASE
2 WHEN zip_code != '(NULL)'
3 AND zip_code_plus_four != '(NULL)'
4 THEN CONCAT_WS('-',zip_code, zip_code_plus_four)
5
6 WHEN zip_code != '(NULL)'
7 THEN zip_code
8
9 ELSE NULL
10END AS postal
Extract first and last names¶
Some data sources do not contain fields that can be directly assigned the given-name and surname semantic tags. These tags are important to downstream Stitch processes. When a field is present in the data source that has data that can be tagged with the full-name semantic tag, you can use domain SQL to extract the first and last name details from that field, add them as new columns, and then apply the correct semantic tags.
Use the REGEXP_EXTRACT() function to:
Trim whitespace from before (or after) the first and last names.
Individually extract the first and last names from the field that has the full name.
Add columns for the first and last names.
The following example shows part of a SELECT statement that extracts first and last names from the BILLING_NAME field, and then adds columns for first and last names:
1,REGEXP_EXTRACT(TRIM(BILLING_NAME),'(^\\S*)',1) AS GIVEN_NAME
2,REGEXP_EXTRACT(TRIM(BILLING_NAME),'((?<=\\s).*)',1) AS SURNAME
3,TRIM(BILLING_NAME) AS `BILLING_NAME`
Fixed-width fields¶
Some data sources contain fixed-width fields. Use a combination of the TRIM() and SUBSTR() functions within a custom domain table to define the length of each field in the file.
For example:
1SELECT
2 TRIM(SUBSTR(col_1, 2, 35)) AS NAME_LINE1,
3 TRIM(SUBSTR(col_1, 416, 20)) AS FIRST_NAME,
4 TRIM(SUBSTR(col_1, 436, 15)) AS MID_NAME,
5 TRIM(SUBSTR(col_1, 451, 20)) AS LAST_NAME,
6 TRIM(SUBSTR(col_1, 37, 35)) AS ADDR_LINE1,
7 TRIM(SUBSTR(col_1, 109, 35)) AS ADDR_LINE2,
8 TRIM(SUBSTR(col_1, 72, 30)) AS CITY,
9 TRIM(SUBSTR(col_1, 102, 2)) AS STATE,
10 TRIM(SUBSTR(col_1, 104, 5)) AS ZIP,
11 TRIM(SUBSTR(col_1, 280, 10)) AS PHONE,
12 TRIM(SUBSTR(col_1, 621, 60)) AS EMAIL_ADDRESS,
13 TRIM(SUBSTR(col_1, 1, 1)) AS GENDER
14FROM custom-domain-table-name
Hash PII data that has been resent to Amperity¶
Some segments send results downstream to support CCPA and GDPR workflows. Some CCPA and GDPR workflows send this data back to Amperity, which typically requires the data to be hashed using a domain table.
For example, to hash the name, email, and phone fields in a table named “tohash_ccpa”:
1SELECT
2 *
3 ,SHA2(UPPER(TRIM(firstname))) AS Hash_firstname
4 ,SHA2(UPPER(TRIM(lastname))) AS Hash_lastname
5 ,SHA2(UPPER(TRIM(email))) AS Hash_email
6 ,SHA2(UPPER(TRIM(phone_number))) AS Hash_phone
7FROM tohash_ccpa
Parse fields with many separators¶
Sometimes incoming data has data that should be tagged with more than one semantic tag, but also contain different separators within the incoming field. For example:
----------- ---------- ------------------- ------- ---------------------- -------
firstName lastName street poBox location zip
----------- ---------- ------------------- ------- ---------------------- -------
John Smith 123 Main #101 US - Yelm , WA 98597
Andy Jones 456 South Avenue US - Bellingham, WA 98115
Anne Andersen 999 S. Bergen Way US - Seattle ,WA 98104
----------- ---------- ------------------- ------- ---------------------- -------
where “location” represents country, city, and state, always separated with a dash ( - ) between the country and city, and then a comma ( , ) between the city and the state. Some fields contain extra white space between and around the strings.
The “location” field needs to be split into individual city, state, and country fields, the two delimiters can be removed, along with the extra whitespace.
Use domain SQL similar to the following:
1SELECT
2 location
3 ,TRIM(SPLIT(location, '-')[0]) AS country
4 ,TRIM(SPLIT(SPLIT(location, '-')[1],',')[0]) AS city
5 ,TRIM(SPLIT(location, ',')[1]) AS state
6FROM domain_table
and then tag the city, state, and country fields with the appropriate semantic tags.
Reference custom domain tables¶
A custom domain table may reference another custom domain table. For example:
1SELECT
2 order_id
3 ,two.order_id
4FROM custom_domain_table1 one
5LEFT JOIN custom_domain_table2 two ON one.order_id = two.order_id
Set non-US-ASCII email addresses to NULL¶
The following CASE statement decodes customer emails, identifies customer emails that are not encoded using the US-ASCII character set, and then sets them to NULL.
1CASE
2 WHEN UPPER(DECODE(UNBASE64(customer_email),'US-ASCII')) = 'UNDEFINED'
3 THEN NULL
4 ELSE UPPER(DECODE(UNBASE64(customer_email),'US-ASCII'))
5END AS email,
Standardize values for USA states¶
The following example standardizes values for all fifty states in the United States to only a two-character value, such as AK, AL, and AR. The CASE statement uses the following strings to determine:
The correct two-character value
The correct spelled out value
Other variations that appear in the data, which may be common (or known) abbreviations, misspellings, slang, or shortcuts
1CASE
2 WHEN UPPER(TRIM(COALESCE(state))) IN ('AL','ALABAMA', 'BAMA') THEN 'AL'
3 WHEN UPPER(TRIM(COALESCE(state))) IN ('AK','ALASKA') THEN 'AK'
4 WHEN UPPER(TRIM(COALESCE(state))) IN ('AZ','ARIZONA') THEN 'AZ'
5 WHEN UPPER(TRIM(COALESCE(state))) IN ('AR','ARKANSAS') THEN 'AR'
6 WHEN UPPER(TRIM(COALESCE(state))) IN ('CA','CALIF','CALIFORNIA','CALIFORNIZ','CALIFRONIA') THEN 'CA'
7 WHEN UPPER(TRIM(COALESCE(state))) IN ('CO','COLORADO') THEN 'CO'
8 WHEN UPPER(TRIM(COALESCE(state))) IN ('CT','CONNECTICUT', 'CONNETICUT') THEN 'CT'
9 WHEN UPPER(TRIM(COALESCE(state))) IN ('DE','DELAWARE', 'DELWARE') THEN 'DE'
10 WHEN UPPER(TRIM(COALESCE(state))) IN ('FL','FLORIDA') THEN 'FL'
11 WHEN UPPER(TRIM(COALESCE(state))) IN ('GA','GEORGIA') THEN 'GA'
12 WHEN UPPER(TRIM(COALESCE(state))) IN ('HI','HAWAII', 'HAWAI\'I') THEN 'HI'
13 WHEN UPPER(TRIM(COALESCE(state))) IN ('ID','IDAHO') THEN 'ID'
14 WHEN UPPER(TRIM(COALESCE(state))) IN ('IL','ILLINOIS') THEN 'IL'
15 WHEN UPPER(TRIM(COALESCE(state))) IN ('IN','INDIANA') THEN 'IN'
16 WHEN UPPER(TRIM(COALESCE(state))) IN ('IA','IOWA') THEN 'IA'
17 WHEN UPPER(TRIM(COALESCE(state))) IN ('KS','KANSAS') THEN 'KS'
18 WHEN UPPER(TRIM(COALESCE(state))) IN ('KY','KENTUCKY') THEN 'KY'
19 WHEN UPPER(TRIM(COALESCE(state))) IN ('LA','LOUISIANA', 'LOUSIANA') THEN 'LA'
20 WHEN UPPER(TRIM(COALESCE(state))) IN ('ME','MAINE') THEN 'ME'
21 WHEN UPPER(TRIM(COALESCE(state))) IN ('MD','MARYLAND') THEN 'MD'
22 WHEN UPPER(TRIM(COALESCE(state))) IN ('MA','MASS','MASSACHUSETES','MASSACHUSETTS','MASSACHUSETTES') THEN 'MA'
23 WHEN UPPER(TRIM(COALESCE(state))) IN ('MI','MICHIGAN') THEN 'MI'
24 WHEN UPPER(TRIM(COALESCE(state))) IN ('MN','MINNESOTA') THEN 'MN'
25 WHEN UPPER(TRIM(COALESCE(state))) IN ('MS','MISSISSIPPI') THEN 'MS'
26 WHEN UPPER(TRIM(COALESCE(state))) IN ('MO','MISSOURI') THEN 'MO'
27 WHEN UPPER(TRIM(COALESCE(state))) IN ('MT','MONTANA') THEN 'MT'
28 WHEN UPPER(TRIM(COALESCE(state))) IN ('NE','NEBRASKA') THEN 'NE'
29 WHEN UPPER(TRIM(COALESCE(state))) IN ('NV','NEVADA') THEN 'NV'
30 WHEN UPPER(TRIM(COALESCE(state))) IN ('NH','NEW HAMPSHIRE') THEN 'NH'
31 WHEN UPPER(TRIM(COALESCE(state))) IN ('NJ','NEW JERSEY', 'JERSEY') THEN 'NJ'
32 WHEN UPPER(TRIM(COALESCE(state))) IN ('NM','NEW MEXICO') THEN 'NM'
33 WHEN UPPER(TRIM(COALESCE(state))) IN ('NY','NEW YORK') THEN 'NY'
34 WHEN UPPER(TRIM(COALESCE(state))) IN ('NC','NORTH CAROLINA') THEN 'NC'
35 WHEN UPPER(TRIM(COALESCE(state))) IN ('ND','NORTH DAKOTA') THEN 'ND'
36 WHEN UPPER(TRIM(COALESCE(state))) IN ('OH','OHIO') THEN 'OH'
37 WHEN UPPER(TRIM(COALESCE(state))) IN ('OK','OKLAHOMA') THEN 'OK'
38 WHEN UPPER(TRIM(COALESCE(state))) IN ('OR','ORE','OREGON','OREGONE') THEN 'OR'
39 WHEN UPPER(TRIM(COALESCE(state))) IN ('PA','PENNSYLVANIA') THEN 'PA'
40 WHEN UPPER(TRIM(COALESCE(state))) IN ('RI','RHODE ISLAND') THEN 'RI'
41 WHEN UPPER(TRIM(COALESCE(state))) IN ('SC','SOUTH CAROLINA') THEN 'SC'
42 WHEN UPPER(TRIM(COALESCE(state))) IN ('SD','SOUTH DAKOTA') THEN 'SD'
43 WHEN UPPER(TRIM(COALESCE(state))) IN ('TN','TENNESSEE') THEN 'TN'
44 WHEN UPPER(TRIM(COALESCE(state))) IN ('TX','TEXAS') THEN 'TX'
45 WHEN UPPER(TRIM(COALESCE(state))) IN ('UT','UTAH') THEN 'UT'
46 WHEN UPPER(TRIM(COALESCE(state))) IN ('VT','VERMONT') THEN 'VT'
47 WHEN UPPER(TRIM(COALESCE(state))) IN ('VA','VIRGINIA') THEN 'VA'
48 WHEN UPPER(TRIM(COALESCE(state))) IN ('WA','WASHINGTON') THEN 'WA'
49 WHEN UPPER(TRIM(COALESCE(state))) IN ('WV','WEST VIRGINIA') THEN 'WV'
50 WHEN UPPER(TRIM(COALESCE(state))) IN ('WI','WISCONSIN') THEN 'WI'
51 WHEN UPPER(TRIM(COALESCE(state))) IN ('WY','WYOMING') THEN 'WY'
52ELSE NULL
Update blocklists¶
The bad-values blocklist uses a regular expression to identify domain tables. Domain tables are built using a source:feed pattern, whereas custom domain tables use a SQL-safe pattern that uses underscores (_) instead of a colon (:) as a delimiter. When custom domain table names are present, the default regular expression will not identify the underscores and any related custom domain tables, and may return NULL values.
If a blocklist returns NULL values and if custom domain tables are present, update the regular expression in the SELECT statements for the following sections:
bad_addresses
bad_emails
bad_phones
For each SELECT statement, change:
REGEXP_EXTRACT(datasource, '.+?(?=:)') AS datasource,
to:
COALESCE(REGEXP_EXTRACT(datasource, '.+?(?=:)'), '*') AS datasource,
This update allows these SELECT statements to continue using a regular expression to find domain tables, and then use * to find custom domain tables and prevents NULL values from being returned.
Added columns¶
Amperity adds the following columns to all domain tables. The added columns start with underscores (_) and are used by Amperity during Stitch processing.
The _pk column is an identifier that is generated based on the all of the columns in the feed that were associated to the primary key.
The _uuid_pk column has a system-generated UUID. This UUID helps Amperity distribute workers during Stitch processing.
The _updated column has details about the last update. It is a system-generated 64-bit integer that combines a timestamp with file/line information.
Amperity uses the value in the _updated column to ensure that the newest record is preferred over older records when both records have the same primary key. This preference is maintained between loads, between records in the same file, and between files and days in the same load.
These columns will be available in the customer 360 database when a domain table is configured as a passthrough table.
Stitched domain tables¶
All domain tables to which semantic tags are added or to which a foreign key is added that can be used to associate records in a domain table to an Amperity ID are processed by Stitch. This is in addition to all domain tables to which customer profile semantic tags were applied, and then were made available to Stitch.
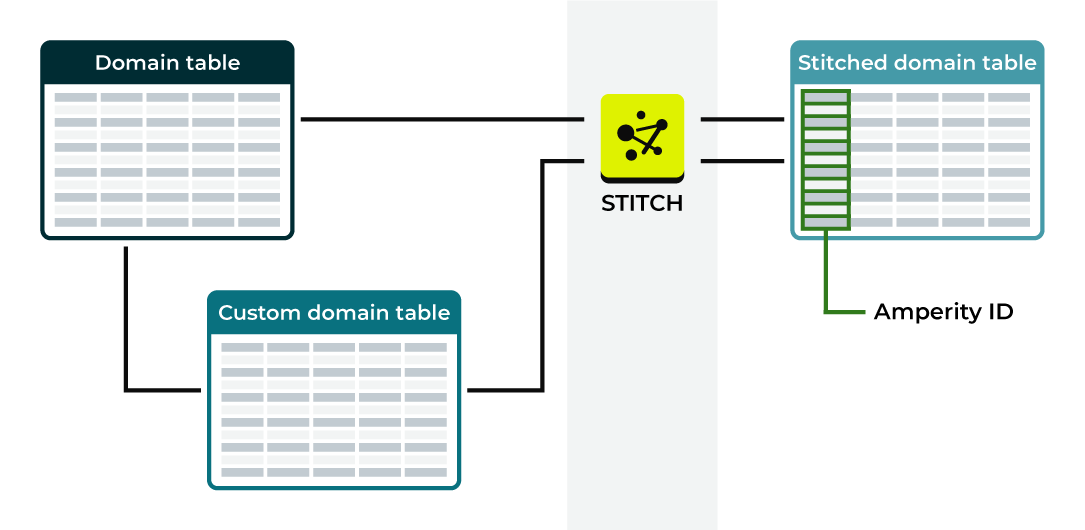
A stitched domain table exists for each domain table with:
Applied semantic tags
An applied foreign key that allows Amperity to link records in the domain table to an Amperity ID that exists in a standard core table
Stitched versions of domain tables have an added column for the Amperity ID and replace the source domain table within Amperity for all downstream use cases, but are otherwise identical to the source domain table.
How-tos¶
Tasks related to managing domain tables in Amperity:
Add domain table¶
A domain table is created by a feed. The domain table name is a combination of the <source-name>:<feed-name>.
Add custom domain table¶
A custom domain table is table that is created from a Spark SQL query built from one or more source domain tables to build a table with reshaped data. The custom domain table is made available to downstream processes, such as Stitch or the customer 360 database, in the same manner as source domain tables.
Feeds load data and apply a standard schema to customer data. Use a custom domain table to load this data in its raw form, and then reshape it to support any downstream workflow. For example:
Enabling privacy rights workflows to help remove data based on individual requests from customers, as required by CCPA and GDPR.
Applying semantic tags to data that has transactions details, including extending the schema and adding new fields.
Supporting workflows that require filtered sets of raw clickstream data.
To add a custom domain table
From the Sources page, under Custom Domain Tables, click Add Table. The Create Custom Table dialog box opens.
Add the name of the custom domain table, and then click Save. The Custom Domain Table page opens.
Important
All custom domain table names must be unique within the same tenant.
Note
The specific purpose of any custom domain table varies by tenant and by use case. That said, a very common use case for custom domain tables is to reshape data that has already been loaded by a feed into the structure required by Amperity for tagging data sources that contain interaction records with transaction and itemized transaction semantics.
Add SQL using Spark SQL to define the custom domain table. This is typically in the form of a
SELECTstatement that returns fields from a feed, but may be more complex if necessary.Tip
Do any required data shaping to support interaction records, in particular for transactions and itemized transactions. Refer to the semantics reference for all requirements for all semantic tags. Refer to the data_tables reference for what types of fields you should expect to be available.
Click Validate to verify that the SQL query runs correctly.
On the Configure and save page, update for interaction records.
Apply Transactions to any column in the data schema that can be matched with transactions semantics.
Note
Other semantic tags may be applied, including for customer records and product catalogs. Tables that contain only transactions, itemized transactions, or product catalog semantic tags are not made available to Stitch.
Click Activate.
Example: Unified transactions¶
1WITH uit_rollup AS (
2 SELECT
3 order_id
4 ,MIN(order_datetime) AS order_datetime
5 ,SUM(IF(is_return IS NULL AND is_cancellation IS NULL COALESCE(item_quantity, 1), 0)) AS order_quantity
6 ,SUM(IF(is_return IS NULL AND is_cancellation IS NULL, item_revenue, 0)) AS sum_item_revenue
7 ,SUM(IF(is_return = TRUE, COALESCE(item_quantity, -1), 0)) AS order_returned_quantity
8 ,SUM(IF(is_return = TRUE, item_revenue, 0)) AS order_returned_revenue
9 ,SUM(IF(is_cancellation = TRUE, COALESCE(item_quantity, -1), 0)) AS order_canceled_quantity
10 ,SUM(IF(is_cancellation = TRUE, item_revenue, 0)) AS order_canceled_revenue
11 FROM Unified_Itemized_Transactions
12 GROUP BY 1
13)
14
15SELECT
16 ut.amperity_id
17 ,fk_onlinecustid AS customer_id
18 ,ut.order_id
19 ,ut.datasource
20 ,ut.store_id
21 ,ut.digital_channel
22 ,ut.purchase_channel
23 ,ut.purchase_brand
24 ,uitr.order_datetime
25 -- If order_revenue is not provided, replace with this:
26 -- ,uitr.sum_item_revenue - ut.{order_discount_amount_field} AS order_revenue
27 -- or this:
28 -- ,uitr.sum_item_revenue AS order_revenue
29 ,ut.order_revenue
30 ,uitr.order_quantity
31 ,uitr.order_returned_quantity
32 ,uitr.order_canceled_quantity
33 ,uitr.order_returned_revenue
34 ,uitr.order_canceled_revenue
35 -- Add in custom semantics as necessary. For example:
36 --,ut.currency
37 --,ut.order_shipping_amount
38FROM uit_rollup uitr
39JOIN Unified_Transactions ut
40ON uitr.order_id = ut.order_id
Example: Loyalty programs¶
1WITH Loyalty_cte AS (
2 SELECT
3 amperity_id
4 ,row_number() OVER w AS row_number
5 ,first(lm_id) OVER w AS Loyalty_Member_id
6 ,first(lmProgramName) OVER w AS Loyalty_Program_Name
7 ,first(current_tier) OVER w AS Loyalty_Tier
8 ,SUM(points) OVER w AS Loyalty_Points
9 ,MIN(created) OVER w AS Loyalty_Program_Join_Date
10 FROM Loyalty_Members
11 WINDOW w AS (PARTITION BY amperity_id ORDER BY created DESC)
12)
13SELECT
14 amperity_id
15 ,Loyalty_Member_id
16 ,Loyalty_Program_Name
17 ,Loyalty_Tier
18 ,Loyalty_Points
19 ,Loyalty_Program_Join_Date
20FROM Loyalty_cte
21WHERE row_number = 1
– and –
1WITH info_from_last_update AS (
2 SELECT
3 amperity_id
4 ,sort_array(collect_list(struct(
5 created
6 ,lm_id
7 ,lmProgramName
8 ,current_tier
9 ,name_first
10 ,name_last
11 ,email
12 ,gender
13 ,address1
14 ,city
15 ,state
16 ,postal_code
17 ,birthdate
18 )), false)[0] AS rep_row
19 FROM Loyalty_Members
20 WHERE amperity_id IS NOT NULL
21 AND created IS NOT NULL
22 GROUP BY amperity_id
23),
24
25other_info AS (
26 SELECT
27 amperity_id
28 ,SUM(points) AS Loyalty_Points
29 ,MIN(created) AS Loyalty_Program_Join_Date
30 FROM Loyalty_Members
31 WHERE amperity_id IS NOT NULL
32 GROUP BY amperity_id
33)
34
35SELECT
36 t1.amperity_id
37 ,t1.rep_row.lm_id AS Loyalty_Member_id
38 ,t1.rep_row.lmProgramName AS Loyalty_Program_Name
39 ,t1.rep_row.current_tier AS Loyalty_Tier
40 ,t2.Loyalty_Points
41 ,t2.Loyalty_Program_Join_Date
42FROM info_from_last_update AS t1
43LEFT JOIN other_info AS t2 ON t1.amperity_id = t2.amperity_id
Add linkage table¶
A linkage table defines how source tables and custom domain tables are linked by primary keys.
To add a linkage table
Open the Sources page.
Under Custom domain tables click Add table.
Write SQL to specify which custom domain table records link to which source records. This will be four columns: a column for the source table name, a column for the primary key in the source table, a column for the custom table name, and a column for the primary key in the custom domain table.
Click Next.
Apply the
compliance/source-dssemantic tag to the source table name.Apply the
compliance/source-pksemantic tag to the primary key for the source table.Apply the
compliance/cdt-dssemantic tag to the custom domain table name.Apply the
compliance/cdt-pksemantic tag to the primary key for the custom domain table.Click Activate.
Delete domain table¶
Use the Delete option to remove a domain table from Amperity. Verify that both upstream and downstream processes no longer depend on this domain table before deleting it. This action will not delete the feeds associated with the domain table.
To delete a domain table
From the Sources page, open the menu for a domain table, and then select Delete. The Delete Domain Table dialog box opens.
Click Delete.
Delete records¶
Users who are assigned the Allow source data deletion policy option can delete records from a domain table.
Use one of the following options to find the records to be deleted:
Records that match will be deleted from the domain table.
Older than a date¶
You can delete all records in a domain table that are older than a date.
To delete records older than a date
From the Sources page, open the menu for a domain table, and then select Delete records. The Delete records dialog box opens.
Under Record criteria, select “Older than a set date”.
Select a field in the domain table with a datetime data type, and then select a date. You may use relative dates. A relative date is always in Coordinated Universal Time (UTC).
Click Preview deletion, and then review the list of records that are returned.
Click Delete records. In the Remove records dialog box, confirm that you want to delete the list of records by clicking Remove records.
Within a timeframe¶
You can delete all records in a domain table that exist between two dates.
To delete records using a timeframe
From the Sources page, open the menu for a domain table, and then select Delete records. The Delete records dialog box opens.
Under Record criteria, select “Within a set timeframe”.
Select a field in the domain table with a datetime data type, and then select the start and end dates for the timeframe. You may use relative dates.
Note
End dates are exclusive.
Click Preview deletion, and then review the list of records that are returned.
Click Delete records. In the Remove records dialog box, confirm that you want to delete the list of records by clicking Remove records.
With a matching value¶
You can delete records in a domain table that meet specific conditions. For example, records that match the domain in an email address or records that match a specific email address.
To delete records with a set value
From the Sources page, open the menu for a domain table, and then select Delete records. The Delete records dialog box opens.
Under Record criteria, select “With a set value”.
Select a field in the domain table, choose a condition, and then specify a value.
Click Preview deletion, and then review the list of records that are returned.
Click Delete records. In the Remove records dialog box, confirm that you want to delete the list of records by clicking Remove records.
Edit domain table¶
A domain table cannot be edited directly. The data within the domain table is updated based on feed and courier settings. The name of the domain table is directly associated with the feed and its schema. Changes made to a feed updates the data in the domain table automatically.
Explore domain table¶
The Data Explorer offers a detailed way to navigate through data tables in Amperity. The Data Explorer displays each column in the data table as a row, with the column name, data type, associated semantic, and a data example. A sample of real table data is available on another tab.
Click the name of the domain table to open the data explorer. The data explorer opens to provide a view of the schema for a domain table, the data that is in the table, and example rows of data.
To explore a domain table
From the Sources page, under Domain Tables, click the name of a domain table. The Data Explorer page opens.
Browse the columns and rows. Click Schema to view the schema and Samples to view sample data.
Click Close when finished.
View sample data¶
Sample data is a representation of about 100 rows of data appear in the domain table.
To view sample data in a domain table
From the Sources page, under Domain Tables, click the name of a domain table. The Data Explorer page opens.
Click Samples to view sample data.
Click Close when finished.
View schema¶
The schema shows how data in the domain table maps to the semantic tagging applied by the feed.
To view the schema for a domain table
From the Sources page, under Domain Tables, click the name of a domain table. The Data Explorer page opens.
Click Schema to view the schema.
Click Close when finished.
Tip
The number of records in a domain table may not match the number of records loaded by Amperity after loading data. Amperity uses an UPSERT process when loading data and determines priority based on the Last Updated Field. If a large difference exists take a close look at the primary key and determine if the primary key is the cause.
Find primary key¶
A custom domain table must have a primary key. The field to which the PK semantic tag is applied must have a unique value for every record in the table.
Warning
Duplicate primary key values will cause database failures. A primary key must be stable over time and should never be transformed or overwritten by updates to source tables.
To find primary key
Open a custom domain table in edit mode.
Click the Start session link to start a Spark SQL session. This may take a few minutes.
After the Spark SQL session is started, click the Find primary key link. This opens the Explore primary keys dialog box.
From the Primary key field dropdown, select one or more fields, and then click the Validate button.
Amperity will evaluate the selected fields and then report on the uniqueness of values in the selected fields. Only fields with unique values should be used as a primary key. For example:
Primary key is only < 5.471% unique There are duplicate values in the selected field.
Click the View duplicates link to view a list of records with duplicate values.
When a single field does not contain unique values you must concatenate two or more fields with values that are stable over time into a single field. Use the concatenated field as the primary key. Hash the value for the concatenated primary key when any of input fields contain personally identifiable information (PII), such as an email address or phone number.
Make available to Stitch¶
A custom domain table with semantic tags applied to records that contain PII data should be made available to Stitch. A custom domain table that is made available to Stitch is used by Stitch for customer identity resolution.
Custom domain table data is made available to Stitch in two steps:
Selecting the Make this table available for Stitch option when configuring a custom domain table.
When selected, the name of the custom domain table is added to a list of feeds and custom domain tables available for selection in Stitch configuration settings.
The custom domain tables must be selected on the Stitched tables tab in the Stitch settings dialog.
Tip
Only tables that contain PII data should be made available to Stitch. Tables that are later associated with Amperity IDs, but do not contain PII data, such as those that contain transactions, should use a foreign key to associate those records with an Amperity ID.
To make data available to Stitch
From the Sources page, open the menu for a custom domain table, and then select Edit. The Custom Domain Table editor page opens.
Click Next.
Under Settings select Make this table available for Stitch.
Click Activate.
Publish to Queries page¶
Domain tables are automatically published and made available to the Queries page in a “database” named Domain tables even when these domain tables are not part of your customer 360 database.
Custom domain tables may be made available to the same database. To publish custom domain tables to the Queries page, from the Sources page, next to Custom Domain Tables, click Publish to queries.
All custom domain tables will be published. Allow for this process to complete before writing queries against published domain tables.
Purge domain table¶
When primary keys for a table are updated the data in the existing domain table must be purged, and then reloaded upon feed reactivation.
Note
Purging a domain table removes all data from the existing table, and then stops. The data is reloaded the next time a courier pulls data to Amperity for that feed or after the feed is run manually. Downstream workflows, such as Stitch or database generation, are not run automatically after data is purged from a domain table.
A domain table cannot be purged directly, though it may be deleted. Operations that may cause a purge of domain table data are initiated when a feed is edited. For example, when the primary key is changed. Purging data ensures the Stitch process does not have to deal with both new and old data.
Rename domain table¶
You cannot rename a domain table directly because of their dependency on feeds. If you need to rename a domain table you must recreate the source and feed pair by adding a new feed, and then deleting the old feed to remove the old domain table from Amperity.
Search domain tables¶
You can search for the presence of fields and semantic tags that are present in domain tables.
To search domain tables
From the Sources page, next to Domain Tables, enter the search term.
The search results are displayed automatically, grouped by domain table, then by column name, and then by semantic tag.
Select a column name to open the data explorer for that domain table.
View domain table¶
Domain tables are visible from the Sources page under Domain Tables.
Note
An individual table may contain both customer and interaction records. As part of the Stitch process, customer records and interaction records are split into dedicated tables for use within the customer 360 database.
View domain table history¶
Domain table history shows accurate row counts a domain table, along with the ability to view a history of updates that were made to that domain table.
Use domain table histories to:
Identifying issues that may arise with the data in the table
View the types of changes that occur over time
To view domain table history
From the Sources page, open the menu for a domain table, and then select History. The Table History dialog box opens.
Select Filter unchanged transactions to remove transactions that did not change the data within the domain table.
Click Load more to load additional rows to the table history.
When finished, click Close.