About feeds¶
A feed defines how to load data into a domain table, including specifying required columns and columns with semantic tags for customer profile (PII) or transactions data.
What a feed does:
Associates columns in customer data with semantics in Amperity.
Assigns column renames, when necessary.
Assigns the data source types Amperity needs for data consistency during the Stitch process.
Are grouped by data source when more than one feed exists for a data source category
What a feed needs:
An input data source, typically (but not always) managed by a courier.
A 1:1 relationship with a courier for large data sources. Couriers are run in parallel whereas feeds run sequentially.
Correctly tagged foreign keys, especially if the field associated with that key is shared across feeds. This is because most tenants deterministically match on foreign keys.
Tip
You can have any number of feeds populated in a courier. However, it is recommended to keep one feed per courier if possible, because couriers can be parallelized, but feeds within a courier are run sequentially.
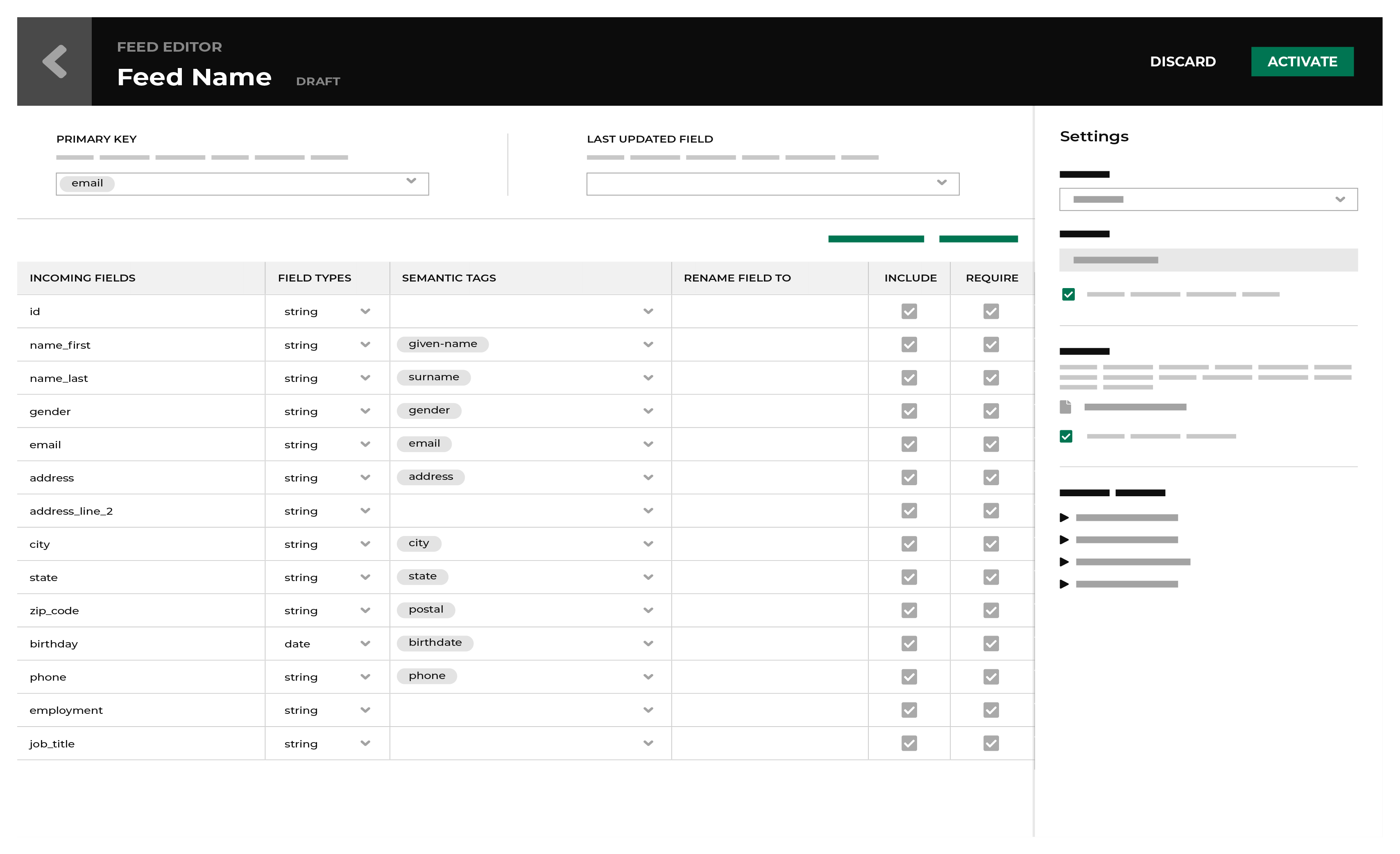
Feed Editor¶
The Feed Editor is the second step adds a new data source to Amperity. The Feed Editor is the interface in which you assign field types, apply semantic tags and primary keys, and then make the data source available to Stitch.
Field types¶
All columns from all data sources that are loaded to Amperity must be aligned to the following field types:
Boolean¶
Use the Boolean field type for incoming fields that contain either/or values, such as “true” or “false”, “yes” or “no”, “0” or “1”, or NULL.
Date¶
Use the date field type for incoming fields that contain ISO-8601 compliant date values, such as a birthdate. For example: “January 18, 1972” or “1972-01-18”.
Note
The date field uses the same formatting options as the datetime field.
Datetime¶
Use the datetime field type for incoming fields that contain ISO-8601 compliant date and time values, such as a purchase or transaction, the time at which data was last updated, or a campaign launch date.
For example, a datetime of “1970-01-15T08:00:00-08:00” is represented as “yyyy-MM-ddThh:mmzzzz”.
Datetime formats¶
The datetime format should be configured to match the pattern for datetimes are formatted in the raw data. This pattern is often similar to “yyyy-MM-dd-HH-mm-ss”, but these patterns do vary. Amperity uses Joda-Time pattern-based formatting to configure the exact datetime pattern that is present in your data.
It is recommended to configure datetime values using Joda-Time pattern-based formatting for all datetime fields for all of your data sources.
You can configure Amperity to apply the same pattern for all datetime fields in a feed or you can configure each datetime field individually.
You may allow Amperity to infer the correct datetime, and then apply pattern-based formatting, but this is not the recommended approach.
Tip
This approach can help speed up initial implementations because Amperity will often infer the correct pattern.
It is recommended to revisit all datetime fields for which automatic patterns are enabled, and then configure them for the correct Joda-Time pattern.
Recommended datetime format patterns
Datetime formats in Amperity use a combination of symbols that are described in the following table:
Symbol |
Description |
|---|---|
y |
The year. Numeric presentation for year fields displays single-character outputs as a zero-based year:
|
D |
The day of the year. For example, the eighteenth day of January is 18 and the first day of February is 32. |
M |
The month of the year. For example: August, Aug, or 8. Use text when three or more pattern characters are present, otherwise use numbers:
|
d |
The day of the month. For example, the eighteenth day of January is 18. |
H |
The hour of the day, 0-23. 1:00 PM is 13.
|
h |
The clock hour of halfday, 1-12. 1:00 PM is 1. |
m |
The minute of the hour. For example, 6:10 PM is 10. |
s |
The second of the minute. |
S |
The fraction of the second. |
z |
The time zone. For example: Pacific Standard Time or PST. Note Time zone names cannot be parsed. |
Z |
The time zone and offset.
|
Note
An apostrophe (’) is an escape character in Joda time. To use a single quote you must use a double apostrophe (‘’).
Any characters in a pattern that are not in the ranges of [a-z] and [A-Z] will be treated as quoted text. For example, the following characters
: (colon)
. (period)
, (comma)
(space)
# (number sign or hash)
? (question mark)
appears as if they are not contained within single quotes.
Other symbols may be available. Refer to Joda-Time documentation for more information about symbols that are not described in the previous table.
Decimal¶
Use the decimal field type for fields that require precision, such as prices or message sizes. Decimal type precision is automatically set to 38. Scale is the number of digits following the decimal point and is configurable from 0 to 37.
You may configure a field for a specific precision scale. You may apply that scale to all decimal field types in the same feed. For example:
1.50 (prices)
1874.38 (message sizes)
141.48 (order subtotals)
Note
Fields in which every value has trailing zeroes, such as quantities and totals, are automatically converted to an integer field type.
Fields that end in non-zero decimals cannot be set to the integer field type.
Float¶
Use the float field type for fields that contain fractional parts, but do not require precision. For example:
3.14
3.14159
Important
Use decimal for fields that contain prices.
Integer¶
Use the integer field type for fields that contain numeral values, such as the number of items purchased. For example:
1
12345
Important
Fields that end in non-zero decimals, such as prices, should use the decimal field type.
String¶
Use the string field type for incoming fields that contain strings and that do not contain obvious matches with other field types, such as all identifiers (account IDs, loyalty IDs, customer IDs), first and last names, email addresses, physical addresses, UUIDs and other IDs, phone numbers, ZIP codes, product names, and descriptions. For example:
John
Smith
John Smith
johnsmith @ domain.com
123 Main Street
206-555-1111
00002ac0-0915-3cb4-b7c7-5ee192b3bd49
ACME
pants
“ “ (may be empty)
“A data source that pulls from an Amazon S3 bucket.” (may contain punctuation)
Troubleshoot ingest errors¶
When a file shows an error on ingest you can troubleshoot those errors by downloading CSV files that contain error logs from the Ingest Details page.
The Ingest Details page is accessible from the Recent activity pane in the Sources page. Error logs are only available for download when errors are present.
Error log files have the following types:
A feed-level log file that describes the types and frequency of errors.
From the Ingest Details page, open the actions menu– –for the feed, and then click Download feed error log.
A file-level log that describes each error.
From the Ingest Details page, expand the table row to show the file, open the actions menu– –for the file, and then click Download file error log.
How-tos¶
The Sources page shows the status of all feeds, including when they last ran or updated, how many records were added, and their current status.
Tasks that are related to managing feeds:
Activate feed¶
A feed must be activated before it can be used to populate domain tables and be associated with a courier. The Activate button is located in the upper right of the Feed Editor. Click the Activate button as the final step when adding or editing a feed.
Add feeds¶
Use the Add Feed button to add a feed to Amperity. A feed must be created for each individual data source that is processed by Amperity. A feed may be based on a sample data file (recommended), be based on an existing file or be defined by hand.
Tip
Group feeds by source, where “source” represents a category more than the actual location from which data is made available to Amperity. Use the source as a folder name, under which any number of feeds that support individual data sources may be grouped.
For example:
A source named “Online” can be a category that represents all customer records for all online transactions. For example, a tenant could pull data from Shopify for Brand A and from Adobe Commerce for Brand B, but group both of them together under the “Online” source.
A source named “Mobile” can categorize customer records for more than one mobile application, such as Attentive or Listrak.
A source named “Purchases” can categorize all transaction records for all store brands, all catalogs, and all mobile applications.
A source named “Klaviyo” can categorize the variety of records that are provided to Amperity from Klaviyo.
Common scenarios for adding feeds to Amperity include:
Add a source grouping¶
If a source category does not exist at the time a feed is added, you can add a new source at the same time you add the feed.
When adding a feed and a source, the sample file for the feed may be:
New sample file¶
Every feed requires a schema. Apply semantic tags to individual fields in the schema. Use one or more individual fields in the schema to define the primary key.
To add a feed using a new sample file
From the Sources page, click Add Feed. This opens the Add Feed dialog box.
Under Data Source select Create new source, and then enter the name for the source.
Under Sample File select Upload new file, and then choose a file.
Information that shows the file type, compression type, and header rows is shown.
Click Continue. This opens the Feed Editor page.
Existing sample file¶
Files that are used as sample files for feeds are uploaded to Amperity and persist in a location that is accessible to the Add Feed dialog box. You may use these files as sample files when adding feeds.
To add a feed using an existing sample file
From the Sources page, click Add Feed. This opens the Add Feed dialog box.
Under Data Source select Create new source, and then enter the name for the source.
Under Sample File select Select existing file, and then choose a file.
Information that shows the date and time at which the existing file was uploaded to Amperity is shown, along with the file ID.
Click Continue. This opens the Feed Editor page.
No sample file¶
A sample file is not required to define a feed. You can add fields directly in the Feed Editor as if they were loaded from a sample file, and then apply semantic tags, field renames, and all of the rest of the possible feed configuration options.
To add a feed with no sample file
From the Sources page, click Add Feed. This opens the Add Feed dialog box.
Under Data Source select Create new source, and then enter the name for the source.
Under Sample File select Don’t use sample file, and then choose a file.
Click Continue. This opens the Feed Editor page.
Use existing source grouping¶
In many cases, a useful source category already exists at the time a feed is added. You should try to group feeds under an existing source category whenever possible.
When adding a feed to an existing source, the sample file for the feed may be:
New sample file¶
Every feed requires a schema to which semantic tags are applied, primary keys are selected, and other configuration details can be specified. Often this requires adding a source and a feed.
To add a feed using a new sample file
From the Sources page, click Add Feed. This opens the Add Feed dialog box.
Under Data Source select Select existing source, and then choose a source.
Under Sample File select Upload new file, and then choose a file.
Information that shows the file type, compression type, and header rows is shown.
Click Continue. This opens the Feed Editor page.
Existing sample file¶
Files that are used as sample files for feeds are uploaded to Amperity and persist in a location that is accessible to the Add Feed dialog box. You may use these files as sample files when adding feeds.
To add a feed using an existing sample file
From the Sources page, click Add Feed. This opens the Add Feed dialog box.
Under Data Source select Select existing source, and then choose a source.
Under Sample File select Select existing file, and then choose a file.
Information that shows the date and time at which the existing file was uploaded to Amperity is shown, along with the file ID.
Click Continue. This opens the Feed Editor page.
No sample file¶
A sample file is not required to define a feed. You can add fields directly in the Feed Editor as if they were loaded from a sample file, and then apply semantic tags, field renames, and all of the rest of the possible feed configuration options.
To add a feed without a sample file
From the Sources page, click Add Feed. This opens the Add Feed dialog box.
Under Data Source select Select existing source, and then choose a source.
Under Sample File select Don’t use sample file, and then choose a file.
Click Continue. This opens the Feed Editor page.
Copy feeds¶
Copy a feed on the Sources page.
To copy a feed
From the Sources page, open the menu for a feed, and then select Make a copy. The Copy Feed page opens.
Select the data source from the Data Source dropdown menu.
Enter the feed name in the Feed Name field.
Click Submit.
The copied feed appears in the Feeds section of the Sources page.
Configure feed schema¶
A feed defines the schema for that data source, associates semantic tags with specific columns in the data, and assigns a primary key. A feed must be activated, after which the feed loads the data to a domain table. A feed that has customer records for PII data must be made available to the Stitch process.
If changes are made to a feed or the data schema in the data source itself changes, the feed must reload the data. In some cases, this also requires the domain table itself be purged, and then rebuilt upon feed reactivation.
The Feed Editor is the second step adds a new data source to Amperity. The Feed Editor is the interface in which you assign field types, apply semantic tags and primary keys, and then make the data source available to Stitch.
Add fields¶
You may add fields to a feed even when they are not present in a sample file.
To add a field to a feed
From the Sources page, open the menu for a feed, and then select Edit.
Click + Add New Field. A field is added to the bottom of the list of fields for the feed.
Add the name of the field, select its field type, associate semantic tags, and apply any renames.
Deselect Required.
Click Activate.
Delete fields¶
A field that is deleted may also be deleted everywhere else it appears in Amperity. The process that updates the domain table occurs automatically. Additional steps may be required to remove the field from a database table, query, or segment that uses the field. A field may not be deleted when it is a dependency for a primary key.
To delete a field
From the Sources page, open the menu for a feed, and then select Edit. The Feed Editor page opens.
Click the trash can icon to delete the field.
Warning
Amperity does not ask for confirmation.
Edit domain table name¶
You may edit the name of the domain table from the Feed Editor.
Warning
Changing the table name will reference the newly specified table for later data ingestion. This table will be created if it does not exist. All data previously ingested is in the prior table.
To edit the name of a domain table from the Feed Editor
From the Sources page, open the menu for a feed, and then select Edit. The Feed Editor page opens.
Under Domain Table select Edit. This allows the text box that has the name of the domain table to be editable.
Enter the new name for the domain table with the pattern <source-name>:<feed-name>. For example: “Customers:Online”.
Click Activate.
Incoming field names¶
The Incoming Field column matches the column name in the source data file.
Amperity will apply the casing in the sample file to the values of the Incoming Field column when a sample file is used to define a feed schema. Changes to the casing of column names have no effect when loading updates to Amperity.
For example, a customer_id column name in the sample file is added to the Incoming Field column as customer_id. A column name change to CUSTOMER_ID or Customer_ID will not affect how the feed loads data or updates to the domain table.
Rename fields¶
A field name may contain only letters, numbers, and underscores. If an incoming field has unsupported characters, such as hyphens or spaces, use the Rename To column to replace the unsupported characters with letters, numbers, or underscores.
For example, a sample CSV file:
name,email,first-name,last-name,phone_home,phone_mobile
Justin Currie,justincurrie@mail.com,Justin,Currie,222-555-1212,505-404-1234
David Zearfoss,davidzearfoss@mail.com,David,Zearfoss,222-555-1313,505-606-8765
will display an alert in the Feed Editor similar to:
Field names may only contain letters, numbers, and underscores. If an
incoming field name has unsupported characters, add a rename.
This is because hyphens are present in two fields. Use the Rename to column to rename first-name to first_name and last-name to last_name.
Set primary key¶
A primary key is a column in a data table that uniquely identifies each row the table.
At least one field must be set as a primary key. Any feed that has customer records or interaction records must have a field that can be associated with a primary key. This is typically an obvious field, like a customer ID or transaction ID, but some data sources are not as clear. You may tag more than one field as the primary key.
To set the primary key
From the Sources page, open the menu for a feed, and then select Edit. The Feed Editor page opens.
From the Primary Key dropdown, select a field from the list.
Click Activate.
Tip
The number of records in a domain table may not match the number of records loaded by Amperity after loading data. Amperity uses an UPSERT process when loading data and determines priority based on the Last Updated Field. If a large difference exists take a close look at the primary key and determine if the primary key is the cause.
Delete feeds¶
Use the Delete option to remove a feed from Amperity. Verify that both upstream and downstream processes no longer depend on this feed before deleting it. This action will not delete the associated data file.
To delete a feed
From the Sources page, open the menu for a feed, and then select Delete. The Delete Feed dialog box opens.
Click Delete.
Edit feeds¶
Use the Edit option in the row for a specific feed to make changes, including to feed details, column names, column types, semantics, or required columns. A very common scenario for editing a feed is to apply foreign key assignments to tables with customer records so that they may be associated to tables with interaction records.
Add columns¶
Warning
Adding columns to a feed should be done after considering the downstream effects of those changes. Changes may have unintended consequences, such as semantics, column names, pick-lists, and other changes may not be immediately available to a downstream process, which may cause that downstream process to fail.
A column may be added to a feed. Before adding columns, be sure to also add the column to any customer 360 database tables that are using the domain table associated with this feed. Columns on passthrough database tables are opt-in, which means you need to update the passthrough table to ensure all columns are loaded. However, this should only be done after the feed has successfully loaded this data to its domain table.
Warning
Editing column types, column semantics, and column names without considering the downstream effects of those changes may have unintended consequences.
It is not always possible to update downstream processes in advance. For example, a query cannot be updated for changes until the data tables against which that query runs have been updated. Because of the additional complexity related to editing column types, column semantics, and column names, it is recommended to take steps to ensure that downstream processes will not run while making these changes, and then:
Update the feed.
Update the domain table, if necessary.
Update Stitch configuration, if necessary.
Update customer 360 database tables, if necessary.
Update queries, if necessary.
Update destinations, if necessary.
Add foreign keys¶
To associate interaction records that are identified by transactions and transaction items semantic tagging with an Amperity ID, you need to add a foreign key that associates primary keys in tables with customer records to the primary key in tables with interaction records.
Caution
You must apply the same foreign key to customer records and interaction records.
To add a foreign key
From the Sources page, open the menu for a feed, and then select Edit. The Edit Feed page opens.
For the field identified as the primary key, add a custom semantic that start with fk-, such as fk-customer.
Click Activate.
Change primary keys¶
Warning
Be careful when making changes to columns in a feed to ensure that all keys–primary, foreign, and customer–are maintained correctly. In general, changing a key can have downstream implications for Stitch, including affecting stable Amperity IDs that depend on this primary key.
A primary key is a column in a data table that uniquely identifies each row the table.
A primary key may be updated in situations that allow for better associations with other data sources or situations that result in improvements to the quality of the identity resolution process.
Changes to the primary key requires truncating data from the domain table upon feed reactivation.
You may edit the primary key. Pick a new one or add more fields to be primary keys.
Important
Changes to primary keys may have unintended downstream effects. If you change the primary key for data that has already been processed by Stitch, a mismatch may be created in the domain model definition and existing domain tables.
To edit the primary key
From the Sources page, open the menu for a feed, and then select Edit. The Edit Feed page opens.
From the Primary Key dropdown, select a field from the list.
If prompted, select Yes, purge the data from my domain table when I activate.
Click Activate.
Delete columns¶
Warning
Deleting columns in a feed should not be done without considering the downstream effects of those changes. Changes may have unintended consequences: semantics, column names, or pick-lists, may not be immediately available to a downstream process, which may cause that downstream process to fail.
A column may be deleted from a feed. The timing of this deletion is important. If a column is deleted during feed creation, that column is not loaded to a domain table, be part of any Stitch processes, be a column in a customer 360 database table, be part of a SQL query that defines a query, or be a data point sent to an external destination.
However, a column that is deleted from a feed that has been loaded to a domain table and has been part of the Stitch process, is a column in a customer 360 table, is part of a SQL query that defines a query, and is a data point that is sent to an external destination.
Before deleting any column that has been loaded to a domain table, be sure to identify if that column is part of any downstream workflows. Every reference to that column need to be removed from Amperity. This is especially important for customer 360 database tables and for queries.
Edit columns¶
Warning
Editing columns in a feed should not be done without considering the downstream effects of those changes. Changes may have unintended consequences: semantics, column names, or pick-lists, may not be immediately available to a downstream process, which may cause that downstream process to fail.
Depending on the type and scope of changes to be made:
Remove references to the column, re-load the data via the feed, and then re-add the column with the updated metadata.
Remove any databases and queries that reference the column, re-load the data via the feed, and then recreate the databases and queries.
Load new data¶
Use the Load new data option in the row for a specific feed to upload a new data file. The file must have the same schema, but may contain new data. The domain table is updated automatically.
To load new data to an existing feed
From the Sources page, open the menu for a feed, and then select Load new data. The Load New Data dialog box opens.
Select a data source.
Important
The selected file must have a schema that matches the schema already defined for the feed.
Click Load.
Make available to Stitch¶
A domain table with semantic tags applied to records that contain PII data should be made available to Stitch. A domain table that is made available to Stitch is used by Stitch for customer identity resolution.
Domain table data is made available to Stitch in two steps:
Selecting the Make this table available for Stitch option when configuring a feed.
When selected, the name of the feed is added to a list of feeds and custom domain tables available for selection in Stitch configuration settings.
The feed must be selected on the Stitched tables tab in the Stitch settings dialog.
Tip
Only tables that contain PII data should be made available to Stitch. Tables that are later associated with Amperity IDs, but do not contain PII data, such as those that contain transactions, should use a foreign key to associate those records with an Amperity ID.
To make data available to Stitch
From the Sources page, open the menu for a feed, and then select Edit. The Feed Editor page opens.
Under Domain Table select Make this table available for Stitch.
Click Activate.
Replace data source¶
In certain cases a data source needs to be replaced in a way that allows a new schema to be added to Amperity, while limiting the amount of changes that must be applied to downstream workflows.
A data source may need to be replaced when there are minor schema changes or when an upstream workflow changes the manner in which that data source is provided to Amperity.
To replace a data source
Add it as a second version of the original. For example:
source_dataandsource_data_v2.Add a foreign key that is shared only by the original and second version.
Tip
Examine the data sources.
If the primary key field is identical in both data sources, assign the foreign key to the primary key fields, otherwise identify a field in each source that can be assigned a shared foreign key.
Make both tables available to Stitch when the data source has PII data.
-
Note
Be sure that the second version is added to the Stitch configuration before running Stitch.
Step through the Stitch QA process, and then examine both versions for foreign key validation.
Important
The foreign key that is shared by the original and second version should not show many Amperity IDs within either the original or second versions. The same individual across both versions should not show different Amperity IDs.
Resolve name conflicts¶
A domain table requires each column name to be unique. However, a sample file may contain duplicate field names. If this occurs, use the Incoming Field column to apply a namespace, an ordinal, or some other naming convention to ensure that column names in the domain table will be unique.
For example, a sample CSV file:
name,email,fname,lname,phone,phone
Justin Currie,justincurrie@mail.com,Justin,Currie,222-555-1212,505-404-1234
David Zearfoss,davidzearfoss@mail.com,David,Zearfoss,222-555-1313,505-606-8765
will display an alert in the Feed Editor similar to:
There is a name conflict in the resulting fields of this feed. Make sure
that none of the field names are duplicated (including any generated fields).
This is because the phone field appears twice. Use the Incoming Field column to rename the first instance of phone to phone_home and the second instance of phone to phone_mobile.
Set error thresholds¶
Amperity processes and checks all rows. The error limit is the percentage of rows that may contain errors when compared to the total number of rows. Data is not ingested when the error limit is exceeded. Adjust the error limit higher or lower to match acceptable percentages for various types of data and data quality.
To set the error threshold
From the Sources page, open a feed.
In the Feed Editor, expand Error Thresholds.
Under MAX, enter an integer between 0 and 100. (The default limit is 1%.)
Click Activate.
Set last updated field¶
Amperity requires each feed to specify a field that describes when each record was last updated. If many records in the incoming data or the existing domain table have the same primary key, the record with the most recent “last updated” field will be retained. This may be associated with a field that has a datetime field type, or an integer (such as for unix timestamps).
Note
Amperity does not use a field with a date data type because that value is not granular enough to determine priority.
If you have no such updated field, you can choose to autogenerate a field, in which case the following logic is used to determine which record to keep in the case a primary key appears more than once:
Records from newly ingested data will always overwrite records that already exist in the domain table.
If couriers are run over a date range, records from files associated with later dates will be retained.
If many files are loaded for the same date, records for the latest-loaded file are retained. File loading order depends on the behavior of the source system, but is deterministic.
If the same primary key appears on many records on the same text-based file, the latest row on the file is retained.
Note
When using ingest queries, the above tiebreakers are unavailable, so upserting behavior can be nondeterministic. Ensure that you either specify a “last updated” field, or that your ingest query only returns a single record for each primary key, to ensure deterministic results.
To set the last updated field
From the Sources page, open the menu for a feed, and then select Edit. The Feed Editor page opens.
The last updated field is above the field list in the center of the page.
Under Last Updated Field, choose how Amperity will determine priority: automatically generated, a field with an integer data type, or a field with a datetime data type (often the same field to which the update-dt merge rules semantic tag is applied).
Click Activate
Tip
The number of records in a domain table may not match the number of records loaded by Amperity after loading data. Amperity uses an UPSERT process when loading data and determines priority based on the Last Updated Field. If a large difference exists take a close look at the primary key and determine if the primary key is the cause.
Truncate feed¶
You can empty the contents of a feed directly from the Sources page.
To truncate a feed
From the Sources page, open the menu for a feed, and then select Truncate. The Truncate Feed dialog box opens.
Click Truncate.
View sample data¶
You can view sample data while building a feed. Click the View sample file link to open the View Sample Page. This page shows up to 200 rows of data based on the current state of the feed schema.