Identity resolution summary¶
The Stitch page shows the outcome of identity resolution, including:
A summary of changes within an identity graph over time
A collection of benchmarks against which you can measure the quality of an identity graph
A data explorer for deduplicated records organized by data source
Summary of identity resolution¶
Identity resolution is the process of connecting and matching data points that exist in many sources to build a unified view of a single customer.
The Summary tab on the Stitch page shows the results of identity resolution and how it adapts and changes over time.
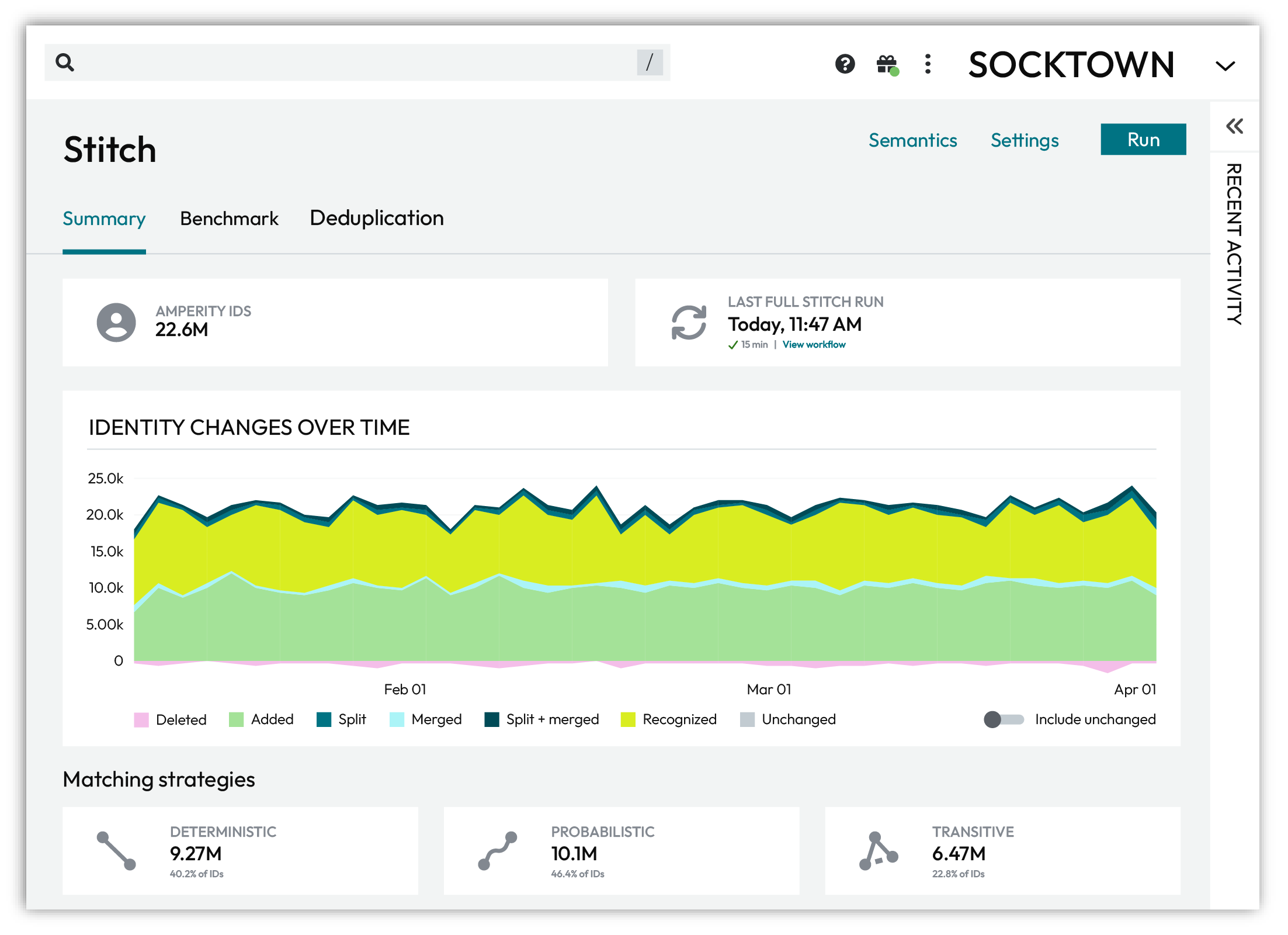
The Summary tab shows:
The number of unique customer profiles assigned an Amperity ID.
An Amperity ID is a unique identifier assigned to a cluster of records within an identity graph. Each Amperity ID represents all of the records within a customer profile.
The last time a full Stitch run completed.
A graph for viewing how identity changes over time.
The percentage of profiles associated with deterministic, probabilistic, and transitive matching strategies.
The complexity of customer profiles based on the number of records in profiles, sorted by 1, 2, 3, 4, 5-10, 11-15, 16-20, 21-25, and 26+ records.
Identity changes over time¶
Adaptive identity is the process of building an identity graph that forms the foundation of customer profiles and defines a keychain of identifiers. Activate customer profiles for marketing campaigns and journeys. Integrate these profiles with other operational systems. Identity recognition uses a keychain to associate real-time events to known customer profiles.
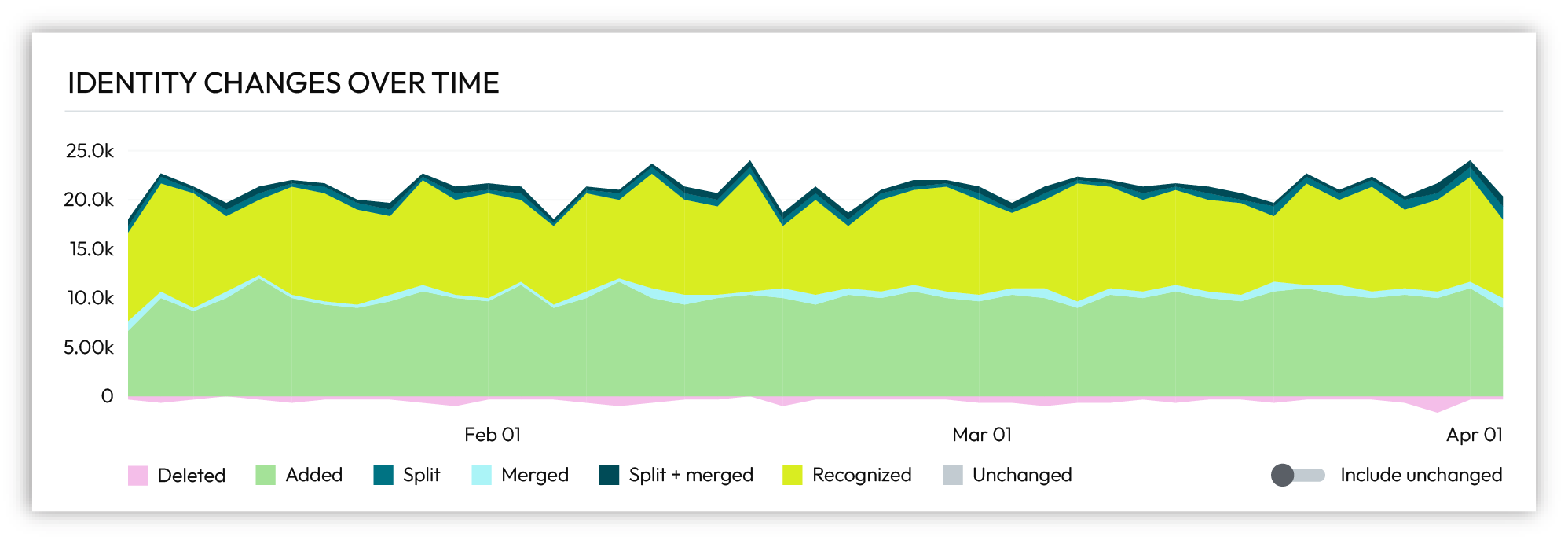
Changes, such as Added, Merged, or Recognized, are tracked for each identity graph over a 90-day time period.
Action |
Description |
|---|---|
Added |
A new Amperity ID was created and added to an identity graph. This type of change occurs when new customer records are added to Amperity. |
Deleted |
An Amperity ID was deleted. This type of change occurs when records are removed from source data, such as after responding to a compliance processing request. |
Merged |
Amperity IDs assigned to two or more profiles in the previous identity graph were combined into a single customer profile and assigned to an Amperity ID that existed in the previous identity graph. This type of change occurs when data clarifies connections between accounts that were not previously known to be related. Stitch rules define criteria for when records are separated or clustered during identity resolution. |
Recognized |
Additional records were appended to a customer profile in an identity graph that was assigned an Amperity ID without a Merge, Split, or Split + Merge operation. This type of change occurs during real-time workflows. Identity recognition relies only on whatever is known about a customer at an exact moment to try to associate that information to a known customer profile. Sometimes what is known is an app or website login that uses an email address or a phone number. Sometimes what is known is a durable identifier, such as a loyalty account ID. Sometimes what is known is a machine-issued digital identifier for Google Ads ID, a mobile device ID, or an advertising-related temporal identifier, such as a pixel ID. |
Split |
Am Amperity ID assigned to a customer profile from the previous identity graph was split into two or more new customer profiles. New Amperity IDs were assigned to the new customer profiles. This type of change occurs when new data clarifies ownership of a shared source identifier, such as a device ID, email address, or phone number. Stitch rules define criteria for when records are separated or clustered during identity resolution. |
Split + merged |
Multiple Amperity IDs from the previous identity graph were split from existing profiles, and then merged into new customer profiles and assigned new Amperity IDs. This type of change occurs when new data provides clarity to sparse records. Stitch rules define criteria for when records are separated or clustered during identity resolution. |
Unchanged |
An Amperity ID did not change. |
Identity resolution analyzes source tables, extracts customer profiles and interactions, and then compares pairs of records using machine learning models to build an identity graph. Each record pair is scored and all records connected using deterministic, probabilistic, or transitive matches represent a unique customer profile.
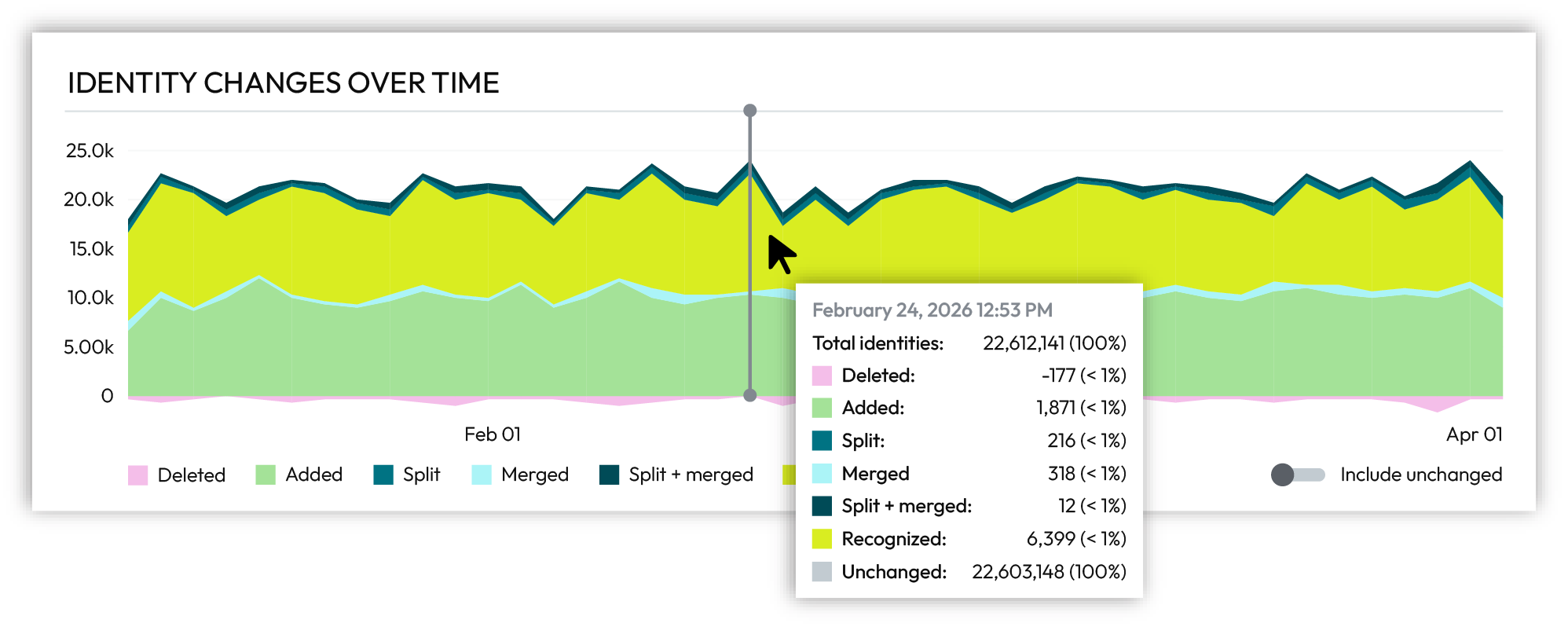
Hover over individual days in the chart to show identity changes for specific days.
Identity changes are a very small percentage of total customer profiles.
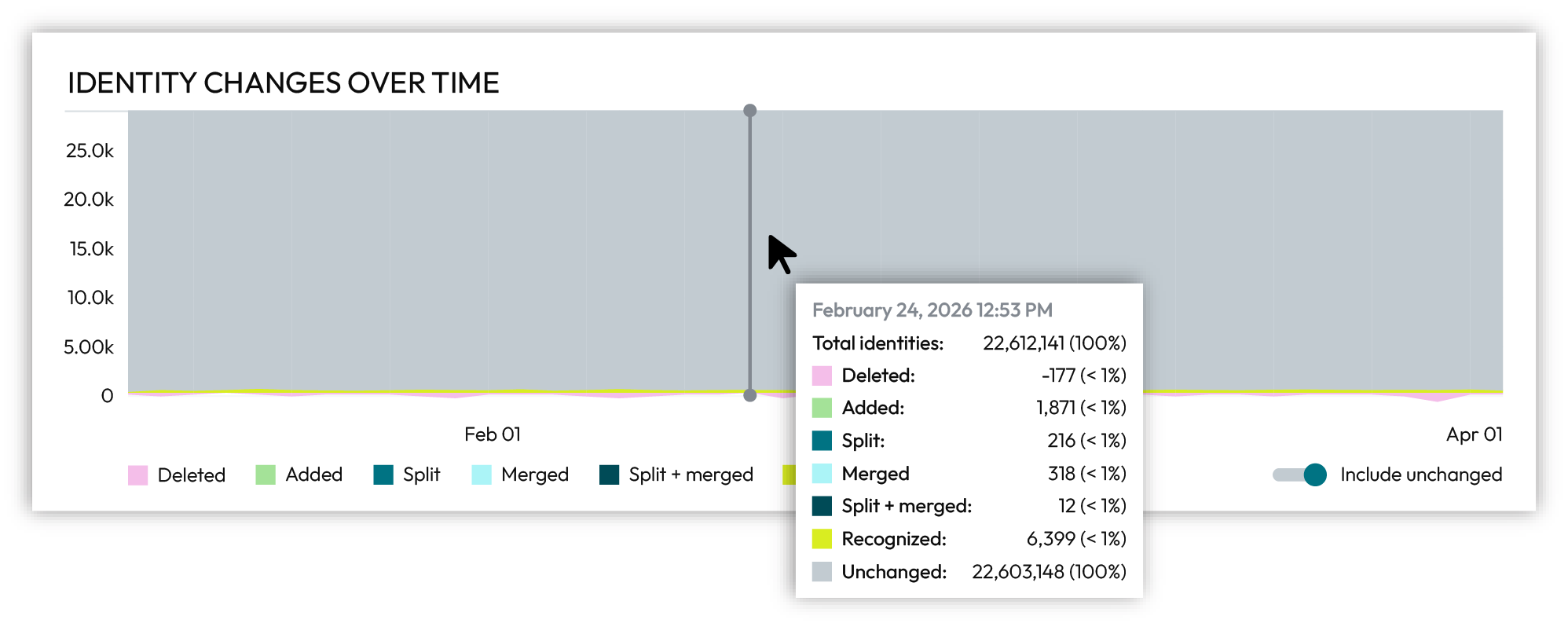
Enable the Include unchanged slider on the right side below the chart to view unchanged customer profiles. Unchanged customer profiles are shown in grey.
Matching strategies¶
An identity graph is the foundation for unified customer profiles. Each customer profile represents a unique customer. Records are connected using a combination of deterministic, probabilistic, and transitive matching. A keychain of identifiers links records in each profile back to source data.
An identity graph is built by comparing records, such as those with personally identifiable information (PII), transaction histories, shopping preferences, and loyalty account information, and clustering matching records into individual customer profiles. Each customer profile in an identity graph is assigned an Amperity ID.
Each identity graph is created from a combination of deterministic and probabilistic matching rules that define conditions for when records should be clustered or separated. The Rules Editor defines a heirarchy of deterministic and probabilistic matching strategies for each identity graph. Identity resolution attempts to match on a rule starting at the top of the list of rules in the rules heirarchy. The first rule that matches is scored.
Why does Amperity “try” to match records?
Amperity does not force record assignment to an identity.
Amperity uses deterministic and probabilistic matching strategies to define conditions that determine when records should or should not match. All record pairs are scored. The scores represent the strength or weakness of the relationship between two records.
Exact matches are assigned minimum or maximum scores.
Fuzzy matches are assigned similarity scores.
It may not be possible to satisfy all of the rules-based scoring conditions:
Default scoring model may assign a score
A transitive connection may be discovered
Edge analysis identifies records that should or should not cluster together
For example, it is possible for a customer profile within an identity graph to have more than one email address because other records within the customer profile scored high enough to match or additional email addresses were discovered transitively.
As the data your brand collects changes over time the data your brand makes available to Amperity changes. Amperity adapts and updates the identity graph to reflect the current state of your customer data.
The Summary tab, under Matching strategies, shows the percentage of total profiles in the identity graph that were discovered using deterministic, probabilistic, and transitive matching.

Identity graphs can be configured to be more deterministic or less deterministic. Most often an identity graph uses a combination of deterministic and probabilistic rules for identity resolution. In addition to deterministic matching and probabilistic matching, identity resolution discovers transitive connections that lead to more accurate and more complete customer profiles.
Deterministic matching¶
Deterministic record matching uses rules that define exact matching for customer keys and semantic tags. Records that do not match exactly to a rule are not scored.
Deterministic matching strategies try to cluster records together when conditions are met. For example, a deterministic strategy for loyalty IDs tries to match records with the same loyalty ID.
Probabilistic matching¶
Probabilistic record matching uses rules that define approximate matching for customer keys and semantic tags. Records that approximately match are evaluated by Stitch and scored.
Probabilistic matching strategies try to separate records when conditions are met. For example, a probabilistic strategy for email addresses tries to separate records with different email addresses.
Transitive matching¶
A transitive connection exists when any two records share a strong match to an intermediate record, but do not have a strong match to each other. For example: record 1 matches record 2, record 3 matches record 2, and records 1 and 3 do not match. A transitive connection exists between records 1 and 3 because both records match record 2.
Transitive connections are discovered during identity resolution.
About match categories¶
A match category is applied to individual record-pair comparisons discovered by deterministic and probabilistic matching strategies during identity resolution.
Match Category |
Description |
|---|---|
Exact |
Amperity has the highest confidence. Records represent the same person because all profile data exactly matches. |
Excellent |
Amperity has near perfect confidence that records belong to the same person, despite some profile data not matching. |
High |
Amperity has high confidence that records match, despite some profile data not matching. |
Moderate |
Amperity has moderate confidence that records match, due to weak or fuzzy matches between unique customer attributes, such as email, phone, or address. |
Weak |
Amperity lacks confidence, but if asked to guess, Amperity would assert these records do belong to the same individual, because they match on non-unique customer attributes, such as name, state, or ZIP code. |
Non-match |
Amperity has high confidence that these records do NOT match, because core profile data is in conflict. |
The score assigned to matched records is the match type. Possible values: “scored”, “scored_transitive”, and “trivial_duplicate”. Records assigned a “scored” value are directly connected by deterministic or probabilistic matching. Records assigned a “scored_transitive” value are transitively connected.
About scoring record pairs¶
Stitch uses the following scoring systems to determine how strongly two records are matched:
Rules-based scoring¶
Rules-based scoring relies on an ordered list of rules. Each rule defines a condition and an action to take when that condition is met. A condition is a set of criteria that determines if two records can match.
For example, rules for clustering records are similar to:
cluster records
when values match for loyalty-id
cluster records
when values approximately match for given-name
and values approximately match for surname
and rules for separating records are similar to:
separate records
when values differ for phone
separate records
when values significantly differ for email
Identity resolution compares two records by starting at the top of the list of rules, and then stepping through the list of rules until a condition is met. When a condition is met the corresponding action is taken. Identity resolution stops comparing two records after the first action is taken, even if additional conditions could be met.
For example, two records with different names, addresses, and phone numbers. Both records have the exact same loyalty ID.
If the first rule with a matching condition is:
cluster records when values match for loyalty-id
both records cluster together because of the exact match on loyalty ID.
If the first rule with a matching condition is:
separate records when values differ for phone
and the second rule is:
cluster records when values match for loyalty-id
both records are separated because the phone numbers are different, even if the loyalty IDs are identical.
The order of rules for rules-based scoring is important and should be carefully considered to ensure the identity graph built from these rules matches the desired business use cases for the identity graph.
Every record that meets the conditiona for rules-based scoring is assigned a pairwise connection score.
A pairwise connection has a score with two parts separated by a period.
The first part–the record pair score–correlates to the match category, which is a machine learning classifier applied during identity resolution to individual record pairs:
5 for exact matches
4 for excellent matches
3 for high matches
2 for moderate matches
1 for weak matches
0 for non-matches
Identity resolution uses the second part–the record pair strength–to show the quality of the record pair score. This value appears in the Stitch report as a two decimal number. A record pair strength by itself is not a direct indicator of the quality of a pairwise connection score.
Tip
Review pairwise connection scoring for an identity graph from
THe Unified Scores table
The Pairwise connections tab in the Data Explorer
Default model scoring¶
Default model scoring is applied to all records that did not match a rules-based condition. Default model scoring has the following options:
Amperity AI¶
Stitch uses patented algorithms to process massive volumes of data and discovers the hidden connections in your customer profiles that identify unique individuals. Stitch analyzes customer data, applies the rules you define, and then builds an identity graph with accurate and actionable customer profiles. Each customer profile is assigned an Amperity ID.
Use Amperity AI model scoring to build an identity graph with deterministic and probabilistic matches, along with opportunities to discover transitive connections that lead to more accurate and more complete customer profiles.
A hybrid model–the most common approach–uses a mixture of exact matching and fuzzy matching with cluster and separation rules to precisely tune scoring for an identity graph. Records are matched deterministically and probabilistically. Transitive connections are discovered. The identity graph has accurate and complete customer profiles.
All records that did not meet the conditiona for rules-based scoring are assigned a pairwise connection score by the Amperity AI model.
No matching model¶
Records are matched only on clustering rules. All records unable to match on a clustering rule are not included in a cluster.
Use No matching model to build a purely deterministic identity graph that builds customer profiles when cluster rules match. Pairwise connection scores are assigned only to records matching on a cluster rule during rules-based scoring.
Identity complexity¶
Each identity graph is a combination of deterministic, probabilistic, and transitive connections. As the data your brand collects changes the data your brand makes available to Amperity changes. Amperity adapts and updates the customer profiles and keychains within in the identity graph to relect the current state of your customer data.
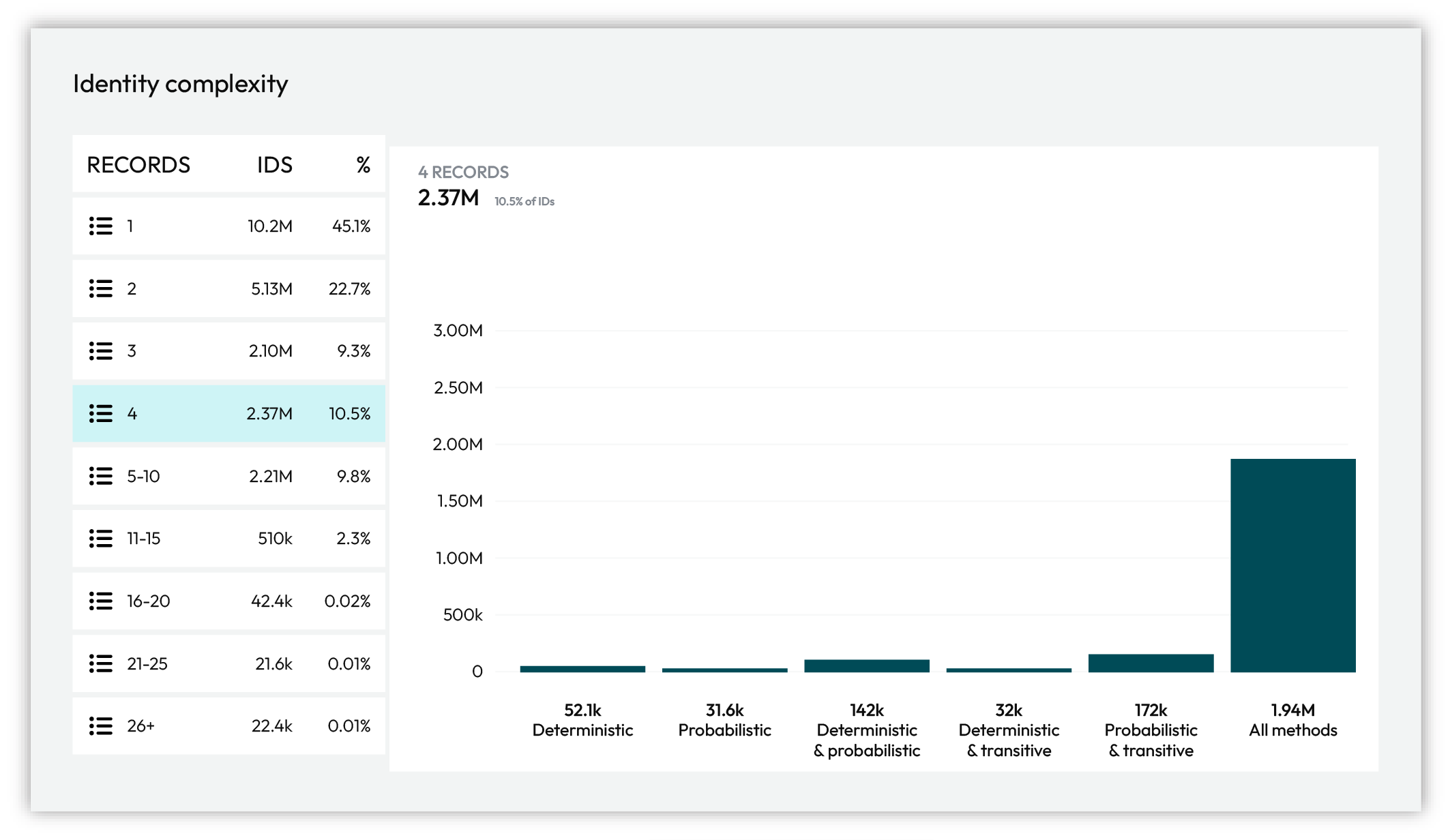
Your best and most valuable customers are often within the mid-range of the identity complexity story. They have transaction histories, exist within many data sources, and have more complete and contactable PII.
The chart under Identity complexity breaks down cluster size by the types of matches found within the clusters.
Action |
Description |
|---|---|
Deterministic only |
Customer profiles built using only deterministic matching. |
Probabilistic only |
Customer profiles built using only probabilistic matching. |
Deterministic and probabilistic |
Customer profiles built using a combination of deterministic and probabilistic matching. |
Deterministic and transitive |
Customer profiles built using a combination of deterministic and transitive matching. |
Probabilistic and transitive |
Customer profiles built using a combination of probabilistic and transitive matching. |
All strategies |
Customer profiles built using a combination of deterministic, probabilistic, and transitive matching |