About the Data Explorer¶
The Data Explorer offers a detailed way to navigate through data tables in Amperity. The Data Explorer displays each column in the data table as a row, with the column name, data type, associated semantic, and a data example. A sample of real table data is available on another tab.
A full-screen mode for the data explorer is available from most areas within Amperity that show data tables in the database. This mode enables detailed exploration of each table, including an overview, the data table schema, examples of data, and source table details.
Tip
You can search for databases and columns in the database from the search bar in the Data Explorer. Search results are filtered automatically, grouped by database table, then by column name, and then by database property.
To open the Data Explorer
From the Customer 360 page, open the Databases tab.
Choose a database, and then click Explore.
This opens the Data Explorer.
Amperity Learning Lab
Use the Data Explorer to explore databases, tables, schemas, and example data.
Open Learning Lab to learn more about understanding and exploring your data . Registration is required.
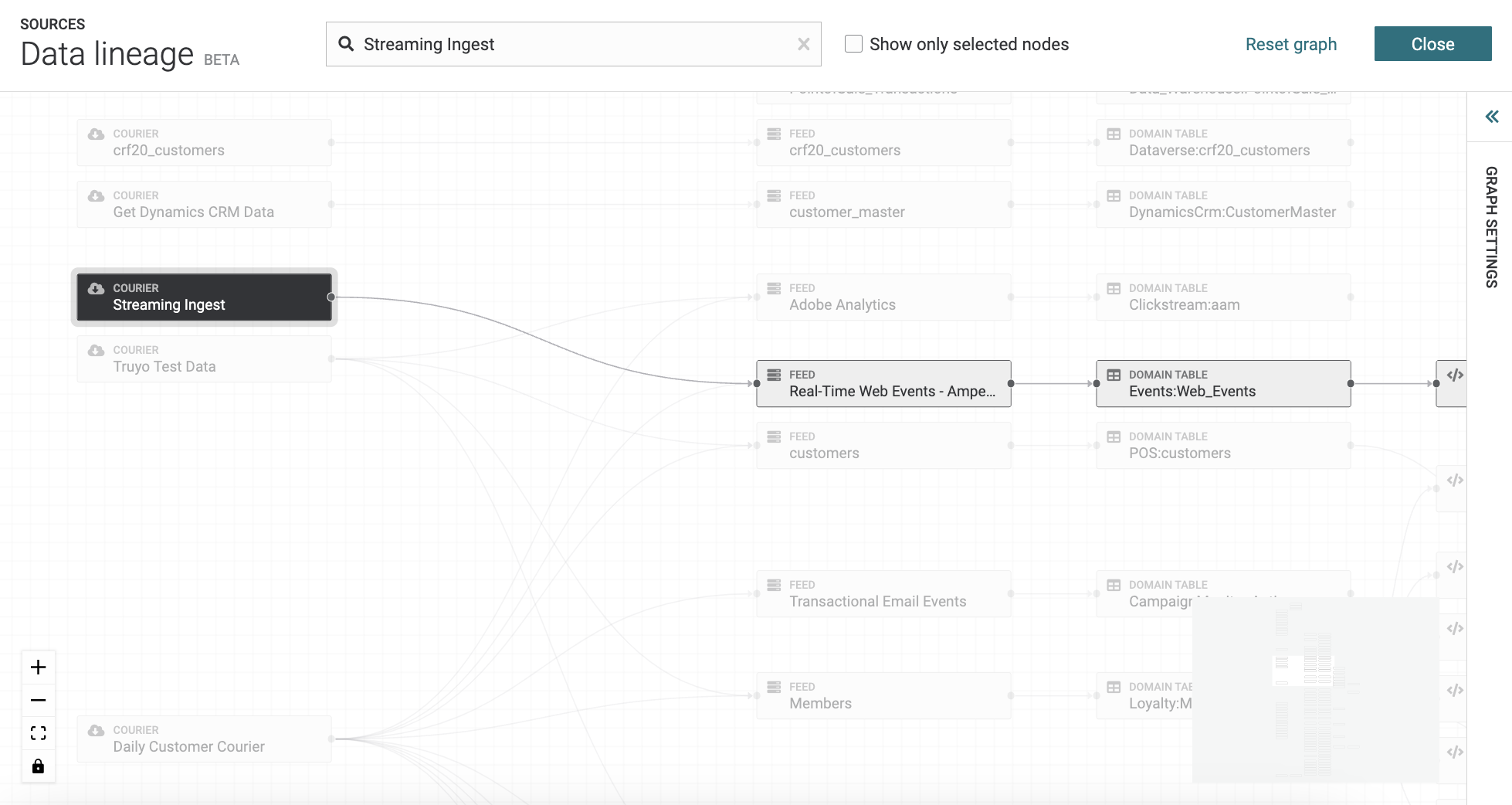
Explore data lineage¶
Data lineage is a graph visualization that shows how all of the data within your tenant connects. The graph visualization is refreshed each time a user loads the Data lineage page.
You can access the data lineage view the following ways:
On the top of the Sources page click Data lineage. On screens with lower resolutions click the Tools menu, and then click Data lineage.
On the top of the Customer 360 page, click Data lineage.
From the Actions menu for courier groups, couriers, custom domain tables, feeds, inbound shares, and source domain tables.
From the Data Explorer.
This opens the full graph and all data sources (nodes) are visible as starting nodes in the graph. Click any data source to explore how data moves from that data source into domain and database tables. Click any table to see its relationship to other tables and the sources from which rows in that table originate.
Search for data sources (nodes), by entering search criteria in to the search field at the top of the page. You can see hide tables from the graph by selecting the Show only selected nodes checkbox.
Note
To reset the graph, click Reset graph on the top of the page.
Change the graph settings by clicking on the Graph Settings panel to open it on the right-side of the page. Use the layout options to change the color theme, graph direction, node width, vertical spacing, and horizontal spacing for the graph. You can reset the graph settings by clicking Reset on the Graph Settings panel. To close the panel click on the arrows at the top of the panel.
Tip
Use the view options to zoom in and out on the nodes by clicking the plus sign to zoom in and the minus sign to zoom out. You can also reset the view by clicking the box option and lock and unlock the graph by clicking the lock option.
To explore data lineage
From the Customer 360 page, open the Databases tab.
Choose a database, and then from the menu, select Data lineage.
This opens the Data lineage page.
Explore details¶
The Details view in the Data Explorer shows summary data about the table, along with information about which source tables were used to build it.
To view database details
From the Customer 360 page, open the Databases tab.
Choose a database, and then from the menu, select Data Explorer.
This opens the Data Explorer page.
Click the name of a table.
Click the Details tab at the top of the table.
When finished browsing the table details, click Close.
Explore example data¶
The Examples view in the Data Explorer shows actual data for a randomly selected set of rows in the data table.
Note
Users with restricted access to PII will not see data for PII-restricted columns, but will see data for all other columns.
Cardinality vs. uniqueness
Cardinality is a measure of how many unique values are present in data. A higher cardinality indicates a larger percentage of unique values, whereas a lower cardinality indicates a higher percentage of repeat values.
Uniqueness divides the number of unique values–cardinality–by the number of rows in a table.
Use cardinality and uniqueness to help guide the creation of well-behaved JOIN operations when authoring SQL queries.
Avoid using JOIN operations when columns have lower cardinality. The high frequency of duplicate values will result in a row for every possible match.
Columns with low uniqueness values as keys on both sides of a JOIN operation runs more slowly and is less likely to return the desired results.
Empty fields, including NULL values, are counted as duplicates, that is “not unique”. For example: a field with 90% completion and 90% uniqueness has different values for each of the non-empty rows.
Completion percentages
Completion is the percentage of non-NULL values within a column.
To view example data
From the Customer 360 page, open the Databases tab.
Choose a database, and then from the menu, select Data Explorer.
This opens the Data Explorer page.
Click the name of a table.
Click the Examples tab at the top of the table.
When finished browsing example data, click Close.
Explore table schemas¶
The Schemas view in the Data Explorer displays information about each column in the table, along with an example, and information about completion, uniqueness, and cardinality.
To view database table schemas
From the Customer 360 page, open the Databases tab.
Choose a database, and then from the menu, select Data Explorer.
This opens the Data Explorer page.
Click the name of a table.
Click the Schema tab at the top of the table.
When finished browsing the table schema, click Close.