About data tables¶
A customer 360 database uses standard core tables generated by the Stitch process. These tables offer a unified view of your brand’s customer data, including customer profiles and interaction records, organized, merged, and linked together by the Amperity ID.
About the data model¶
The data model represents the “out-of-the-box” tables that are available to every tenant.
Important
This data model represents the starting point for all tenants. It is common for a tenant to have additional tables that support specific data requirements and workflows.
Data model diagram¶
The following diagram shows the data model for core tables in Amperity. Color coded sections identify which groups of tables are associated with customer profiles, interactions records, Stitch QA, and predictive modeling.
Note
Click this diagram to open it in your full browser window. Click HERE to open this diagram in a new tab or right-click that link to save a copy to your computer.
The data tables diagram has four groups of tables:
Group name |
Description |
|---|---|
Customer records |
A customer profile is a collection of attributes connected to a single unique individual in the customer 360 database. The total number of customer profiles is equal to the total number of rows in the Customer 360 table. This total correlates strongly, but not exactly, with the total number of Amperity IDs assigned to unique individuals in the same dataset. The Customer 360 table represents your primary set of customer profiles and is the most common starting point for building segments. Each customer profile is built using a combination of the Merged Customers, Customer Attributes, Unified Customer, and Unified Coalesced tables. |
Interaction records |
An interaction record is a row in a customer data table that has information about customer behavior. For example:
Interaction records rely on a series of tables: Transaction Attributes Extended, Unified Itemized Transactions, Unified Transactions, and Unified Product Catalog. Each Amperity ID in the Customer 360 table can be associated to many rows in the Unified Transactions table, and then each Amperity ID in the Unified Transactions can be associated to many rows in the Unified Itemized Transactions table. Each Amperity ID in the Customer 360 table is associated to one Amperity ID in the Transaction Attributes Extended table. |
Stitch results |
Stitch QA is a manual process for monitoring the quality of Stitch results. Stitch QA has two parts: a database and a collection of queries. Analyze query results to identify values for labeling and blocklisting, or to discover ways to tune the Stitch process to better match your tenant’s dataset. Stitch QA activities rely on a series of tables: Unified Coalesced, Unified Scores, Detailed Examples, Unified Preprocessed Raw, Unified Changes Clusters, and Unified Changes PKS. These tables are the basis for the Stitch QA process. The use of any specific table will vary from tenant to tenant. Together they provide visibility into how Amperity grouped (or did not group) individual customer records to a single Amperity ID. |
Predictive models |
Predictive modeling tables are the results of the configuration and tuning of Amperity for predictive analytics. These tables rely on the Merged Customers, Unified Itemized Transactions, and Unified Transactions tables for predictions, but there is not a 1-to-1 or 1-to-many relationship between those three tables and predictive modeling tables. The Predicted CLV Attributes table has one row per Amperity ID, whereas the Predicted Affinity table has many rows per Amperity ID. The Campaign Recipients table has a history of all campaigns that have been sent from Amperity. This table is updated on a recurring basis and may be used like any other table in your customer 360 database. |
Data model indicators¶
This diagram uses the following indicators to highlight relationships between tables and to call out fields that are primary keys, establish links between tables, or associate this table back to a domain table in the Sources page:
Name |
Description |
|---|---|
1:1, 1:many 
|
Indicates that this table has a 1:1 or 1:many relationship with another table. For most tables, this relationship is based on the Amperity ID. |
Many:1 
|
Indicates that this table has a many:1 relationship with another table. For most tables, this relationship is based on the Amperity ID. |
Primary key 
|
Indicates this column is the primary key for this table. |
Linking key 
|
Indicates this column links customer records, such as those associated with a customer key or a foreign key that were defined as part of a feed or custom domain table from the Sources page. |
Data source 
|
Indicates this column is associated to an original customer data source in the Sources page, with the value of this field being the name of that data source. |
Activation States¶
Activation States tables are generated by Amperity to track membership and activity for campaigns and journeys.
Activation States tables cannot be accessed from a sandbox, a query, or a database table. Activation States tables are only accessible as a condition from the Segment Editor.
Important
Access to the fields in an Activation States table requires at least one active campaign or journey in your tenant.
For campaigns¶
Activation states for campaigns keep track of customers who are activated by a campaign, including by sub-audience or treatment, by destination, how often and when.
Campaign activation states can be added to any segment.

Field reference
Column name |
Data type |
Description |
|---|---|---|
Campaign |
String |
The name of a campaign. |
Count |
String |
The sum of First Entry and Last Entry. |
Destination |
String |
The name of a destination in the selected campaign. |
First entry |
String |
The date and time at which an audience member was first part of a campaign. |
Last entry |
String |
The date and time at which an audience member was most recently part of a campaign. |
Sub-audience |
String |
The name of a sub-audience in the selected campaign. |
Treatment |
String |
The name of a treatment group in the selected campaign. |
For journeys¶
Activation states for journeys keep track of customers who have entered a journey, along with which customers moved through specific nodes, including their first and last entry.
Journey activation states can be added to any segment.

Field reference
Column name |
Data type |
Description |
|---|---|---|
Entry count |
String |
The number of times an audience member entered the selected node. |
First entry time |
String |
The date and time at which an audience member was first part of a journey. When a node is specified, the date and time at which an audience member first entered the node within the journey. |
Journey |
String |
The name of the journey. |
Last entry time |
String |
The date and time at which an audience member was most recently part of a journey. When a node is specified, the date and time at which an audience member was most recently part of the node within the journey. |
Node |
String |
The name of a node within the selected journey. |
All Opted-In Emails¶
The All Opted-In Emails table has all opted-in email addresses and associated Amperity IDs. Use the Email Opt Status table to build this table, after which you can extend it to support brands, regions, email programs, and language preferences.
Warning
The All Opted-In Emails table is not unique by Amperity ID and should not be used within the Segment Editor.
However, it must be made available to the Segment Editor to send additional emails as attributes on a campaign.
Choose the email attribute from the All Opted-In Emails table on the Edit Attributes menu. This ensures that the email attribute in this table is available to campaigns.
The All Opted-In Emails table has the same columns as the Email Opt Status table. Unlike the Email Opt Status table, the All Opted-In Emails table should not be used in the Segment Editor.
Campaign Recipients¶
The Campaign Recipients table has a list of Amperity IDs associated with campaigns sent from Amperity, along with details about the campaign. These details include control and treatment groups, audience segments, destinations, and launch dates.
The Campaign Recipients table is generated by Amperity, and then made available as a standard database table. Use this table to access campaign attributes, perform historical campaign analysis, and to build segments and multi-stage campaigns that use the results of previous campaigns.
Important
Data in the Campaign Recipients table is updated after the next database run. If your database is configured to run once per day then data in the Campaign Recipients table will be available on a 1-day delayed rolling basis.
Note
See Campaign Recipients for more information about how this table is built and maintained within Amperity.
The Campaign Recipients table has the following columns:
Column name |
Data type |
Description |
|---|---|---|
Amperity ID |
String |
The unique identifier assigned to clusters of customer profiles that all represent the same individual. The Amperity ID does not replace primary, foreign, or other unique customer keys, but exists alongside them within unified profiles. Note The Amperity ID is a universally unique identifier (UUID) that is 36 characters spread across five groups separated by hyphens: 8-4-4-4-12. For example: 123e4567-e89b-12d3-a456-426614174000
|
Campaign ID |
String |
The unique ID for a campaign. |
Campaign Name |
String |
The name of the campaign. |
Campaign Type |
String |
A campaign is a message or offer sent to a specific group of customers or recipients. A campaign may be one of the following types:
A one-time campaign represents a specific campaign message sent only once. A recurring campaign automatically sends an updated or refreshed audience with a predefined campaign message and cadence for a list of recipients. For example, a state change, an accepted return, a change to loyalty status, or an alert based on credit card status. |
Database ID |
String |
The unique ID for the database. |
Database Name |
String |
The name of the database. |
Dataset Version |
String |
A unique ID for the dataset used with this set of campaign recipients. |
Delivery Datetime |
Datetime |
The date and time at which the associated campaign ID was delivered to the destination. |
Destination ID |
String |
The unique ID for a destination. |
Destination Name |
String |
The name of the destination to which the associated campaign ID was sent. |
Is Control |
Boolean |
A flag that indicates if the Treatment ID represents a control group. |
Launch Datetime |
Datetime |
The date and time at which the associated campaign ID was sent from Amperity to its downstream workflow. |
PK |
String |
The combination of data source and primary key allows Amperity to uniquely identify every row in every data table across the entirety of customer data input to Amperity. |
Segment ID |
String |
The unique ID for the segment that generated the list of recipients for the associated campaign ID. |
Segment Name |
String |
The name of the segment used with the associated campaign ID. |
Sub Audience ID |
String |
The unique ID for the sub-audience to which the associated campaign was sent. |
Sub Audience Name |
String |
The name of the sub-audience to which the associated campaign was sent. |
Target ID |
String |
The unique ID for a destination. |
Target Name |
String |
The name of the destination to which the associated campaign ID was sent. |
Treatment ID |
String |
The ID for the treatment group. |
Treatment Name |
String |
The name of the treatment group for a campaign. All treatment groups, along with the control group, combine for measuring campaign quality. |
Workflow ID |
String |
The unique ID for the workflow that managed the associated campaign. |
Customer 360¶
The Customer 360 table is the unified view of the customer across all points of engagement, including attributes that cross systems. This table does not exist by default. Each row represents a complete record for a unique individual, including their Amperity ID, merged PII data, and summary attributes.
Note
See Customer 360 for more information about how this table is built and maintained within the customer 360 database.
Note
The columns that appear in the Customer 360 table varies, depending on the SQL statement used to add columns to the table. The set of columns must include the Amperity ID and should include columns that contain profile (PII) data, along with columns that contain summary attributes for interaction records.
Caution
Amperity does not have built-in semantic tags for credit cards or debit cards. Hash credit card or debit card numbers before making them available to Amperity and use a custom semantic tag, such as credit-card or cc. Do not use unhashed card numbers in Amperity customer profiles.
The following table represents a Customer 360 table with profile data and a few summary attributes based on interaction records for transaction data:
Column Name |
Data type |
PII |
Description |
|---|---|---|---|
Amperity ID |
String |
The unique identifier assigned to clusters of customer profiles that all represent the same individual. The Amperity ID does not replace primary, foreign, or other unique customer keys, but exists alongside them within unified profiles. Note The Amperity ID is a universally unique identifier (UUID) that is 36 characters spread across five groups separated by hyphens: 8-4-4-4-12. For example: 123e4567-e89b-12d3-a456-426614174000
|
|
Given Name |
String |
|
The first name connected with a customer. Also in: Merged Customers, Unified Coalesced, Unified Customer, Unified Preprocessed Raw |
Surname |
String |
|
The last name connected with a customer. Also in: Merged Customers, Unified Coalesced, Unified Customer, Unified Preprocessed Raw |
String |
|
The email address connected with a customer. A customer may have more than one email address. Also in: Merged Customers, Unified Coalesced, Unified Customer, Unified Preprocessed Raw |
|
Phone |
String |
|
The phone number connected with a customer. A customer may have more than one phone number. Also in: Merged Customers, Unified Coalesced, Unified Customer, Unified Preprocessed Raw |
Address |
String |
|
The address connected with the location of a customer, such as “123 Main Street”. Also in: Merged Customers, Unified Coalesced, Unified Customer, Unified Preprocessed Raw |
City |
String |
|
The city connected with the location of a customer. Also in: Merged Customers, Unified Coalesced, Unified Customer, Unified Preprocessed Raw |
State |
String |
|
The state or province connected with the location of a customer. Also in: Merged Customers, Unified Coalesced, Unified Customer, Unified Preprocessed Raw |
Postal |
String |
|
The ZIP code or postal code connected with the location of a customer. Also in: Merged Customers, Unified Coalesced, Unified Customer, Unified Preprocessed Raw |
Birthdate |
Date |
|
The date of birth connected with a customer. Also in: Merged Customers, Unified Coalesced, Unified Customer, Unified Preprocessed Raw |
Gender |
String |
|
The gender connected with a customer. Also in: Merged Customers, Unified Coalesced, Unified Customer, Unified Preprocessed Raw |
Customer Attributes¶
The Customer Attributes table has a series of columns that identify attributes about individuals. For example:
Is an individual contactable?
Is there a marketable email address?
Is the physical address known?
Is there a phone number?
Are they are an employee, reseller, or a test account?
What is the individual’s revenue relationship with the brand?
The Customer Attributes table has the following columns:
Column name |
Data type |
Description |
|---|---|---|
Amperity ID |
String |
The unique identifier assigned to clusters of customer profiles that all represent the same individual. The Amperity ID does not replace primary, foreign, or other unique customer keys, but exists alongside them within unified profiles. Note The Amperity ID is a universally unique identifier (UUID) that is 36 characters spread across five groups separated by hyphens: 8-4-4-4-12. For example: 123e4567-e89b-12d3-a456-426614174000
|
Churn Trigger |
String |
The churn status for a customer. Possible values:
Tip Use these values as part of your churn prevention campaigns. |
Churn Trigger Start Datetime |
Datetime |
The date and time at which the Churn Trigger status begins. |
Contactable Address |
Boolean |
A flag that indicates if a customer can be contacted by a physical mailing address. |
Contactable Email |
Boolean |
A flag that indicates if a customer has an email address with a valid format. |
Contactable Global |
Boolean |
A flag that indicates if a customer can be contacted by phone number, email address, or physical mailing address. |
Contactable Paid Social |
Boolean |
A flag that indicates if a customer has personally identifiable information (PII) that could be used to contact them using paid social media channels. |
Contactable Phone |
Boolean |
A flag that indicates if a customer has a phone number with a valid format. |
Historical Purchaser Lifecycle Status |
String |
The status for a customer, based on their history and recency of interactions a brand. Possible values: “new”, “active”, “lapsed”, “dormant”, and “prospect”. Customer states are “active”, “lapsed”, “dormant”, or “prospect”. Purchase behaviors use a 5 year window. A customer who purchased within the previous 365 days–1 year–is “active” and within the previous 730 days–2 years–is “lapsed”. A customer who has not purchased within 2 years is “dormant”. Note The ranges for this field are customizable. The default ranges represent:
|
Is Business |
Boolean |
A flag that indicates if a customer is a known or likely business. |
Is Employee |
Boolean |
A flag that indicates if a customer is or has been an employee of the brand at any time. |
Is Gift Giver |
Boolean |
A flag that indicates if a customer has purchased items as gifts. |
Is No PII Amperity ID |
Boolean |
A flag that indicates if the customer does not have personally identifiable information (PII) for name (given name, surname, full name), address (street address, city, state, postal code), email address, or phone number. |
Is Opted Into Email |
Boolean |
A flag that indicates if the customer has given consent to receive email communications from your brand. |
Is Opted Into SMS |
Boolean |
A flag that indicates if the customer has given consent to receive SMS messages from your brand. |
Is Outlier |
Boolean |
A flag that indicates if the customer has abnormally high purchase behaviors in comparison to other purchasers. |
Is Primary Buyer Household |
Boolean |
A flag that indicates if a customer is the individual within a household who represents the highest lifetime revenue for that household. Note This attribute requires the Merged Households table. |
Is Prospect |
Boolean |
A flag that indicates if a customer does not have a purchase history with a brand. |
Is Purchaser |
Boolean |
A flag that indicates if the customer has a purchase history with a brand. |
Is Reseller |
Boolean |
A flag that indicates if the customer is a known or likely reseller of a product. Tip A reseller should be defined as an early repeat purchaser with a high lifetime order frequency. Use the following fields from the Transaction Attributes Extended table to define a reseller:
|
Is Test Account |
Boolean |
A flag that indicates if the customer is a known test account for a brand. |
Detailed Examples¶
The Detailed Examples table has detailed examples of Stitch results. Use these examples to help identify which features lead to scores with the biggest effect on Stitch results, including how they associate with various combinations of fields that contain PII data.
Note
The Detailed Examples table is a subset of the Unified Scores table.
The Detailed Examples table has the following columns, as its starting point. This table is typically updated to add more pairs, enable use for blocklisted values, and to support additional tenant-specific use cases.
Column name |
Data type |
Description |
||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
Amperity ID |
String |
The unique identifier assigned to clusters of customer profiles that all represent the same individual. The Amperity ID does not replace primary, foreign, or other unique customer keys, but exists alongside them within unified profiles. Note The Amperity ID is a universally unique identifier (UUID) that is 36 characters spread across five groups separated by hyphens: 8-4-4-4-12. For example: 123e4567-e89b-12d3-a456-426614174000
|
||||||||||||||
Address A Address B |
String |
The address connected with the location of a customer, such as “123 Main Street”. |
||||||||||||||
Birthdate A Birthdate B |
String |
The date of birth connected with a customer. |
||||||||||||||
Case Count |
String |
|||||||||||||||
City A City B |
String |
The city connected with the location of a customer. |
||||||||||||||
Country A Country B |
String |
The country connected with the location of a customer. |
||||||||||||||
Datasource A Datasource B |
String |
The name of the data source from which this customer profile originated. Tip The combination of PK and Datasource uniquely identifies a row in the Unified Coalesced table, which correlates to a single row in a domain table. |
||||||||||||||
Email A Email B |
String |
The email address connected with a customer. A customer may have more than one email address. |
||||||||||||||
Given Name A Given Name B |
String |
The first name connected with a customer. |
||||||||||||||
Match Category |
String |
A match category is applied to individual record-pair comparisons discovered by deterministic and probabilistic matching strategies during identity resolution.
Also in: Unified Scores |
||||||||||||||
Phone A Phone B |
String |
The phone number connected with a customer. A customer may have more than one phone number. |
||||||||||||||
PK A PK B |
String |
The combination of data source and primary key allows Amperity to uniquely identify every row in every data table across the entirety of customer data input to Amperity. Tip The combination of PK and Datasource uniquely identifies a row in the Unified Coalesced table, which correlates to a single row in a domain table. |
||||||||||||||
Postal A Postal B |
String |
The ZIP code or postal code connected with the location of a customer. |
||||||||||||||
Score |
Float |
A score has a value from “0.0” to “5.0” that represents the combined score assigned to the record pair by Stitch. A score has two parts: the score is on the left side and the score’s strength is on the right. The record pair score correlates to the match category, which is a classifier applied by Amperity to individual record pairs. The record pair score corresponds to the classification:
The record pair strength represents the strength of the record pair score assigned by Stitch during identity resolution. It is a two digit number. For example: .31 is a lower strength and .93 is a higher strength. Note Scores are shown for records that end up in the same cluster, including any scores that are below threshold. Scores are not shown for records that do not end up in the same cluster. Also in: Unified Scores |
||||||||||||||
Score Count |
String |
|||||||||||||||
State A State B |
String |
The state or province connected with the location of a customer. |
||||||||||||||
Surname A Surname B |
String |
The last name connected with a customer. |
Email Engagement Attributes¶
The Email Engagement Attributes table has many of the same fields as the Email Engagement Summary table, except for the addition of the Amperity ID field. Whereas the Email Engagement Summary table is unique by email and brand, the Email Engagement Attributes table is unique by the Amperity ID and email for each brand combination.
Note
In the Email Engagement Attributes table, each Amperity ID should only have one email address, per brand.
Tip
The Email Engagement Attributes table pulls the email engagement data, for each Amperity ID, from the Email Engagement Summary table using the email associated with it in the Merged Customers table.
Note
The Email Engagement Attributes table can be selected as a source in the Segment Editor to segment customers based on their email behavior.
The Email Engagement Attributes table has the following columns:
Column name |
Data type |
Description |
|---|---|---|
Amperity ID |
String |
This column is input to predictive modeling. The unique identifier assigned to clusters of customer profiles that all represent the same individual. The Amperity ID does not replace primary, foreign, or other unique customer keys, but exists alongside them within unified profiles. Note The Amperity ID is a universally unique identifier (UUID) that is 36 characters spread across five groups separated by hyphens: 8-4-4-4-12. For example: 123e4567-e89b-12d3-a456-426614174000
|
Brand |
String |
The brand or company from which an email was sent. |
String |
The email address to which an email was sent. |
|
Email Clicks Last X Day |
Integer |
The number of email clicks in the last 1, 3, 5, 7, 14, or 30 days. |
Email Clicks Last X Months |
Integer |
The number of email clicks in the last 3, 6, 9, or 12 months. |
Email Opens Last X Day |
Integer |
The number of email opens in the last 1, 3, 5, 7, 14, or 30 days. |
Email Opens Last X Months |
Integer |
The number of email opens in the last 3, 6, 9, or 12 months. |
Engagement Frequency Last 15 Months |
String |
A classification that measures engagement frequency click rates for email addresses that have received a low volume of emails. Possible values:
Important Send rates must be available. |
Engagement Status Last 15 Months |
String |
A classification that measures click rates for email addresses that have received a low volume of emails. Possible values:
Important Send rates must be available. |
First Email Click Datetime |
Datetime |
The date and time at which an email was first clicked. |
First Email Open Datetime |
Datetime |
The date and time at which an email was first opened. |
First Email Send Datetime |
Datetime |
The date and time at which an email was sent. |
Most Recent Email Bounce Datetime |
Datetime |
The date and time for the most recent bounced email. |
Most Recent Email Click Datetime |
Datetime |
The date and time at which a customer most recently clicked a link or offer within an opened email. |
Most Recent Email Open Datetime |
Datetime |
The date and time at which a customer most recently opened an email. |
Most Recent Email Optin Datetime |
Datetime |
The date and time at which a customer most recently opted-in to receiving email. |
Most Recent Email Optout Datetime |
Datetime |
The date and time at which a customer most recently opted-out from receiving email. |
Most Recent Email Send Datetime |
Datetime |
The date and time at which an email was most recently sent. |
Purchase Before Signup |
Boolean |
This flag indicates whether an Amperity ID is associated with a previous transaction before signing up with this email address. |
Signup To Purchase Days |
Integer |
The number of days between the time this email was used to signup and the next transaction associated with an Amperity ID. Note This field appears null if there is no transactions made after the email signup. |
Email Engagement Summary¶
The Email Engagement Summary table has a summary of email event statistics, such as counts for opens and clicks, the first open, and the most recent click, unique by email address.
Note
The Email Engagement Summary table can be used for analysis and to inform the selection of the best email in the Email Amperity ID Assignment table.
The Email Engagement Summary table has the following columns:
Column name |
Data type |
Description |
|---|---|---|
Brand |
String |
The brand or company from which an email was sent. |
String |
The email address to which an email was sent. |
|
Email Click Rate Lifetime |
Integer |
The click rate for all email messages. |
Email Clicks Last X Day |
Integer |
The number of email clicks in the last 1, 3, 5, 7, 14, or 30 days. |
Email Clicks Last X Months |
Integer |
The number of email clicks in the last 3, 6, 9, or 12 months. |
Email Clicks Lifetime |
Integer |
The number of all email clicks for all email messages. |
Email Opens Last X Day |
Integer |
The number of email opens in the last 1, 3, 5, 7, 14, or 30 days. |
Email Opens Last X Months |
Integer |
The number of email opens in the last 3, 6, 9, or 12 months. |
Email Open Rate Lifetime |
Integer |
The open rate for all email messages. |
Email Opens Lifetime |
Integer |
The number of all email opens for all email messages. |
Engagement Frequency Last 15 Months |
String |
A classification that measures engagement frequency click rates for email addresses that have received a low volume of emails. Possible values:
Important Send rates must be available. |
Engagement Status Last 15 Months |
String |
A classification that measures click rates for email addresses that have received a low volume of emails. Possible values:
Important Send rates must be available. |
First Email Click Datetime |
Datetime |
The date and time at which an email was first clicked. |
First Email Open Datetime |
Datetime |
The date and time at which an email was first opened. |
First Email Send Datetime |
Datetime |
The date and time at which an email was sent. |
Most Recent Email Bounce Datetime |
Datetime |
The date and time for the most recent bounced email. |
Most Recent Email Click Datetime |
Datetime |
The date and time at which a customer most recently clicked a link or offer within an opened email. |
Most Recent Email Open Datetime |
Datetime |
The date and time at which a customer most recently opened an email. |
Most Recent Email Optin Datetime |
Datetime |
The date and time at which a customer most recently opted-in to receiving email. |
Most Recent Email Optout Datetime |
Datetime |
The date and time at which a customer most recently opted-out from receiving email. |
Most Recent Email Send Datetime |
Datetime |
The date and time at which an email was most recently sent. |
Most Recent Email Open Or Click Datetime |
Integer |
The date and time of the most recent email open or click. |
EUID¶
European Union ID (EUID) is an open-source framework that enables deterministic identity for advertising opportunities across the open internet for participants with access to the advertising ecosystem. EUID is a standalone solution with a unique namespace and privacy controls that help participants meet local market requirements.
The EUID table has the results of EUID token generation when enabled for your tenant.
The EUID table has the following columns:
Column name |
Data type |
Description |
|---|---|---|
Bucket ID |
String |
A unique identifier for the salt bucket that is used to ensure that expired EUID tokens are refreshed. This value is returned in the response from the POST /identity/map endpoint. Note Each EUID token is associated with a salt bucket that links that token to a specific point in time. Salt buckets expire. Approximately 1/365th of all salt buckets are rotated daily. Amperity monitors salt buckets on a daily basis to determine which EUID tokens need to be refreshed. |
String |
The email address for the customer. Amperity gets this value from the email field in the Unified Coalesced table. |
|
Normalized Email |
String |
The normalized email address sent from Amperity to the POST /identity/map endpoint for mapping. This value is returned in the response from the POST /identity/map endpoint. |
EUID |
String |
The raw EUID value for the customer. This value, when encrypted, may be used as a EUID token. This value is returned in the response from the POST /identity/map endpoint. |
The EUID History table has the following columns:
Column name |
Data type |
Description |
|---|---|---|
Bucket ID |
String |
The salt bucket ID associated with this version of the EUID token. |
Created At |
Datetime |
The timestamp at which this version of the EUID token was recorded. |
String |
The email address for the customer. Amperity gets this value from the email field in the Unified Coalesced table. |
|
EUID |
String |
The raw EUID token value at the time this record was written. |
Normalized Email |
String |
The normalized email address used when generating the EUID token. |
Event Propensity¶
An Event Propensity table associates individual customers to the events that, depending on the type of event, are most likely to lead to engagement with your brand.
Note
See Event Propensity for more information about how this table is built and maintained within the customer 360 database.
The Event Propensity table has the following columns:
Column name |
Data type |
Description |
|---|---|---|
Amperity ID |
String |
The unique identifier assigned to clusters of customer profiles that all represent the same individual. The Amperity ID does not replace primary, foreign, or other unique customer keys, but exists alongside them within unified profiles. Note The Amperity ID is a universally unique identifier (UUID) that is 36 characters spread across five groups separated by hyphens: 8-4-4-4-12. For example: 123e4567-e89b-12d3-a456-426614174000
|
Audience Size Large |
Boolean |
A flag that indicates the recommended audience size. When this value is A large audience is predicted to include ~90% of customers who are likely to perform the target event. |
Audience Size Medium |
Boolean |
A flag that indicates the recommended audience size. When this value is A medium audience is predicted to include ~70% of customers who are likely to perform the target event. |
Audience Size Small |
Boolean |
A flag that indicates the recommended audience size. When this value is A small audience is predicted to include ~50% of customers who are likely to perform the target event. Use a small audience size to help prevent wasted spend and to reduce opt-outs. |
Ranking |
Integer |
A ranking of customers by score for this event. A rank that is less than or equal to X provides the top N customers with an propensity for this event. |
Score |
Float |
The strength of a customer’s propensity for this event, shown as an uncalibrated probability between 0 and 1. Tip Ranking is derived directly from the score–customers are ranked in descending order of score–so a higher score corresponds to a higher ranking. Because the score is uncalibrated, target customers using Ranking and audience size rather than the raw score. Sort results by Ranking, and then compare those results to audience sizes. Higher rankings within smaller audience sizes correlate with higher propensity. |
Target Event Name |
String |
The name of the target event used with an event propensity model. |
Fiscal Calendar¶
A fiscal calendar is a yearly accounting period that aligns the weeks and months in a calendar year with holidays and a brand calendar. Use a fiscal calendar to align the business for an entire calendar year. A common fiscal calendar brands use is the 4-5-4 fiscal calendar.
A 4-5-4 calendar divides years into months using a 4 weeks–5 weeks–4 weeks pattern. Each week starts on a Sunday and ends on a Saturday. Each quarter has the same number of days. A 4-5-4 calendar can be useful for comparing like days for sales reporting purposes.
The Fiscal Calendar table is generated by Amperity when fiscal calendar semantic tags are applied to source data tables.
The Fiscal Calendar table has the following columns:
Column name |
Data type |
Description |
|---|---|---|
Calendar Date |
Date |
The standard calendar date. Important The field to which this semantic tag is applied must also be the primary key for the table. |
Day Of Week |
String |
The day of the week. |
Fiscal Month |
String |
The fiscal month that is associated with the calendar date. |
Fiscal Quarter |
String |
The fiscal quarter that is associated with the calendar date. |
Fiscal Week End |
Date |
The calendar date on which the fiscal week ends. |
Fiscal Week Number |
Integer |
The number of the week within the fiscal year. This field indicates on which month a fiscal year starts. |
Fiscal Week Start |
Date |
The calendar date on which the fiscal week starts. |
Fiscal Year |
Integer |
The fiscal year that is associated with the calendar date. |
Holiday Sale Name |
String |
The holiday date (or date range) to which this date belongs. |
Merged Customers¶
The Merged Customers table collects rows from the Unified Coalesced table, and then collapses rows into a single row per Amperity ID.
Note
See Merged Customers for more information about how this table is built and maintained within the customer 360 database.
The Merged Customers table has the following columns:
Column name |
Data type |
Description |
|---|---|---|
Amperity ID |
String |
This column is input to predictive modeling. The unique identifier assigned to clusters of customer profiles that all represent the same individual. The Amperity ID does not replace primary, foreign, or other unique customer keys, but exists alongside them within unified profiles. Note The Amperity ID is a universally unique identifier (UUID) that is 36 characters spread across five groups separated by hyphens: 8-4-4-4-12. For example: 123e4567-e89b-12d3-a456-426614174000
|
Address |
String |
The address connected with the location of a customer, such as “123 Main Street”. Also in: Customer 360, Unified Coalesced, Unified Customer, Unified Preprocessed Raw |
Address2 |
String |
Address information, such as an apartment number or a post office box, connected with the location of a customer, such as “Apt #9”. Also in: Unified Coalesced, Unified Customer |
Birthdate |
Date |
This column is input to predictive modeling. The date of birth connected with a customer. Also in: Customer 360, Unified Coalesced, Unified Customer, Unified Preprocessed Raw |
City |
String |
This column is input to predictive modeling. The city connected with the location of a customer. Also in: Customer 360, Unified Coalesced, Unified Customer, Unified Preprocessed Raw |
Company |
String |
The company, typically an employer or small business, connected with a customer. |
Country |
String |
The country connected with the location of a customer. Also in: Unified Coalesced, Unified Customer |
Create DT |
String |
Apply the create-dt semantic tag to columns that identify the creation date or time. The field must be a datetime field type. Also in: Unified Coalesced, Unified Customer |
String |
This column is input to predictive modeling. The email address connected with a customer. A customer may have more than one email address. Also in: Customer 360, Unified Coalesced, Unified Customer, Unified Preprocessed Raw |
|
Full Name |
String |
A combination of given name and surname–or first name and last name–for a customer. Amperity selects the first non-nil value:
Also in: Unified Coalesced, Unified Customer |
Gender |
String |
This column is input to predictive modeling. The gender connected with a customer. Also in: Customer 360, Unified Coalesced, Unified Customer, Unified Preprocessed Raw |
Generational Suffix |
String |
The suffix that identifies to which family generation a customer record belongs. For example: Jr., Sr. II, and III. Also in: Unified Coalesced, Unified Customer |
Given Name |
String |
This column is input to predictive modeling. The first name connected with a customer. Also in: Customer 360, Unified Coalesced, Unified Customer, Unified Preprocessed Raw |
Loyalty ID |
String |
The identifier for a loyalty program connected with a customer. This column is added when the loyalty-id semantic tag is applied to customer profiles. Also in: Unified Coalesced |
Phone |
String |
This column is input to predictive modeling. The phone number connected with a customer. A customer may have more than one phone number. Also in: Customer 360, Unified Coalesced, Unified Customer, Unified Preprocessed Raw |
Postal |
String |
This column is input to predictive modeling. The ZIP code or postal code connected with the location of a customer. Also in: Customer 360, Unified Coalesced, Unified Customer, Unified Preprocessed Raw |
State |
String |
This column is input to predictive modeling. The state or province connected with the location of a customer. Also in: Customer 360, Unified Coalesced, Unified Customer, Unified Preprocessed Raw |
Surname |
String |
This column is input to predictive modeling. The last name connected with a customer. Also in: Customer 360, Unified Coalesced, Unified Customer, Unified Preprocessed Raw |
Title |
String |
The title that precedes a full name connected with a customer, such as “Mr”, “Mrs”, and “Dr”. Also in: Unified Coalesced, Unified Customer |
Update DT |
String |
Apply the update-dt semantic tag to datetime fields in customer profiles that identify the most recent update in the source system. At least one customer profile must have this semantic tag applied to ensure that the update_dt column exists in the Unified Coalesced table. Also in: Unified Coalesced, Unified Customer |
Additional columns in the Merged Customers table
The Merged Customers table has additional columns that help you understand how and why customer profile values are present in the Merged Customers table.
These column names start with one of Name, Address, Email, Phone, Birthday, or Gender, and then are grouped as described in the following table. For example: Name Completion, Name Datasource, Name PK, Name Priority, and Name Update DT.
Column Suffix |
Description |
|---|---|
Completion |
The number of NOT NULL values that are present in a set of data, as defined in Merged Customers. Combine the use of this column with Priority to understand why a record was selected. A name has three possible values: Given Name, Surname, and Full Name. When all three values are NOT NULL, the value in the Name Completion column will be An address has four possible values: Address, City, State, and postal. When all four values are NOT NULL, the value in the Address Completion column will be An email address has one possible value: Email. When this value is NOT NULL, the value in the Email Completion column will be A phone number has one possible value: Phone. When this value is NOT NULL, the value in the Phone Completion column will be A birthdate has one possible value: Birthdate. When this value is NOT NULL, the value in the Birthdate Completion column will be Gender has one possible value: Gender. When this value is NOT NULL, the value in the Gender Completion column will be |
Datasource |
The source data table from which the customer profile value originates. Combine the use of this column with PK to find the record in the source domain table. |
PK |
The primary key for the record in Datasource. Combine the use of this column with Datasource to find the record in the source domain table. |
Priority |
The priority that is assigned to the source domain table in Merged Customers. Combine the use of this column with Completion to understand why a record was selected. |
Update DT |
Opt-in status tables¶
Standard output tables are available that make available your customer’s preferences for email and phone communications from your brand. Use these preferences to determine when and how your brand can use email and SMS to communicate with your customers.
Use the Email Opt Status table when your brand communicates with your customers using their email address.
Use the SMS Opt Status table when your brand communicates with your customers using their phone number.
Email Opt Status¶
The Email Opt Status table has a row for each unique combination of email address, brand, region, and email program.
This table is generated when email-opt/ semantic tags are applied to data sources that contain data that describes your customer’s consent status and gives insight into which customers are available to be used as part of an email-based marketing campaign.
Important
Amperity is not the source of truth for email consent status. Email consent status can change, including between the time of this table’s most recent update and the time at which your brand wants to send your customers an email as part of a campaign.
The source of truth for consent status exists downstream from Amperity, often directly within the marketing tool or application that you are using to configure the email campaign, such as Cordial, Braze, Klaviyo, or Attentive.
Use this table to filter audiences in Amperity to include customers who have consented to receiving email messages, and then build a step within the downstream marketing tool that verifies consent status immediately before sending an email.
Note
The Email Opt Status table represents every email address for which you have provided customer consent data to Amperity. There should be only one consent status by combination of email address, brand, region, or email program.
If you have many brands, regions or email programs, it is possible for the same email address to have more than one customer consent status.
If a brand, region, or email program does not exist, there should be only one customer consent status for each unique email address.
The Email Opt Status table has the following columns:
Semantic Name |
Datatype |
Description |
|---|---|---|
Amperity ID |
String |
The unique identifier assigned to clusters of customer profiles that all represent the same individual. The Amperity ID does not replace primary, foreign, or other unique customer keys, but exists alongside them within unified profiles. |
Brand |
String |
The brand to which the opt-in status applies. |
String |
The email address connected with a customer. A customer may have more than one email address. |
|
Email Frequency |
String |
The preferred frequency for email messages. |
Email Program |
String |
The email program to which the customer has opted-in. |
Is Email Opted In |
Boolean |
Indicates whether a customer has given consent to being contacted by your brand using the customer’s email address. |
Language Preference |
String |
The customer’s preferred language for email messages. |
Region |
String |
The region to which the opt-in status applies. |
SMS Opt Status¶
The SMS Opt Status table has a row for each unique combination of phone number, brand, region, and SMS program.
This table is generated when sms-opt/ semantic tags are applied to data sources that contain data that describes your customer’s consent status and gives insight into which customers are available to be used as part of an SMS-based marketing campaign.
Important
Amperity is not the source of truth for SMS consent status. SMS consent status can change, including between the time of this table’s most recent update and the time at which your brand wants to send your customers an SMS message as part of a campaign.
The source of truth for consent status exists downstream from Amperity, often directly within the marketing tool or application that you are using to configure the SMS campaign, such as Cordial, Braze, Klaviyo, or Attentive.
Use this table to filter audiences in Amperity to include customers who have consented to receiving SMS messages, and then build a step within the downstream marketing tool that verifies consent status immediately before sending an SMS message.
Note
The SMS Opt Status table represents every phone number for which you have provided customer consent data to Amperity. There should be only one consent status by combination of phone number, brand, region, or SMS program.
If you have many brands, regions or SMS programs, it is possible for the same phone number to have more than one customer consent status.
If a brand, region, or SMS program does not exist, there should be only one customer consent status for each unique phone number.
The SMS Opt Status table has the following columns:
Semantic Name |
Datatype |
Description |
|---|---|---|
Amperity ID |
String |
The unique identifier assigned to clusters of customer profiles that all represent the same individual. The Amperity ID does not replace primary, foreign, or other unique customer keys, but exists alongside them within unified profiles. |
Brand |
String |
The brand to which the opt-in status applies. |
Is SMS Opted In |
Boolean |
Indicates whether a customer has opted-in to being contacted by your brand using the customer’s phone number. |
Language Preference |
String |
The customer’s preferred language for SMS messages. |
Phone |
String |
The phone number connected with a customer. A customer may have more than one phone number. |
Region |
String |
The region to which the opt-in status applies. |
SMS Frequency |
String |
The preferred frequency for SMS communications. |
SMS Program |
String |
The SMS program to which the customer has opted-in. |
Predicted Affinity¶
An Affinity table associates individual customers to the products they are most likely to purchase. Use an Affinity table to help deliver personalized experiences to your customers.
Note
See Predicted Affinity for more information about how this table is built and maintained within the customer 360 database.
A Predicted Affinity table has the following columns:
Column name |
Data type |
Description |
|---|---|---|
Amperity ID |
String |
The unique identifier assigned to clusters of customer profiles that all represent the same individual. The Amperity ID does not replace primary, foreign, or other unique customer keys, but exists alongside them within unified profiles. Note The Amperity ID is a universally unique identifier (UUID) that is 36 characters spread across five groups separated by hyphens: 8-4-4-4-12. For example: 123e4567-e89b-12d3-a456-426614174000
|
Audience Size Large |
Boolean |
A flag that indicates the recommended audience size. When this value is A large audience size is predicted to include ~90% of future purchasers and to include a high number of non-purchasers. |
Audience Size Medium |
Boolean |
A flag that indicates the recommended audience size. When this value is A medium audience size is predicted to include ~70% of future purchasers and to include a moderate number of non-purchasers. |
Audience Size Small |
Boolean |
A flag that indicates the recommended audience size. When this value is A small audience size is predicted to include ~50% of future purchasers and to include the fewest number of non-purchasers. |
Product Attribute |
String |
The field against which product affinity is measured. For example: a category, a subcategory, or a brand. Values must have at least 100 purchases during the previous 30 days and at least 250 purchases during the previous 365 days to be included in product affinity model output. |
Ranking |
Integer |
A product attribute’s rank for this customer, where 1 equals the highest product affinity. |
Score |
Float |
The strength of a customers’s affinity for this product, shown as an uncalibrated probability between 0 and 1 that combines product-specific affinity with general likelihood to purchase. A higher score represents a stronger predicted affinity. Caution A customer score should only be used in relation to other customer scores for the same product attribute value. A customer score should not be used in absolute terms. A score does not directly correlate to ranking or audience sizes and should not be used in segments. Important Use audience size attributes or ranking when building segments for product affinity instead of customer scores. |
Predicted CLV Attributes¶
The Predicted CLV Attributes table has information, for each individual Amperity ID, about predicted future spend and the probability of churn.
Note
See Predicted CLV Attributes for more information about how this table is built and maintained within the customer 360 database and how it interacts with features within predictive modeling.
The Predicted CLV Attributes table has the following columns:
Column name |
Data type |
Description |
|---|---|---|
Amperity ID |
String |
The unique identifier assigned to clusters of customer profiles that all represent the same individual. The Amperity ID does not replace primary, foreign, or other unique customer keys, but exists alongside them within unified profiles. Note The Amperity ID is a universally unique identifier (UUID) that is 36 characters spread across five groups separated by hyphens: 8-4-4-4-12. For example: 123e4567-e89b-12d3-a456-426614174000
|
Days Since Last Order |
Integer |
The number of days elapsed since the customer’s last order. |
Historical Order Frequency Lifetime |
Integer |
The total number of historical orders a customer has made. |
Predicted Average Order Revenue Next 365D |
Decimal |
The predicted average order revenue over the next 365 days. |
Predicted CLV Next 365D |
Decimal |
The total predicted customer spend over the next 365 days. |
Predicted Customer Lifecycle Status |
String |
A probabilistic grouping of a customer’s likelihood for future transactions. For repeat customers, groupings include the following tiers:
For one-time buyers, groupings include the following tiers:
|
Predicted Customer Lifetime Value Tier |
String |
A percentile grouping of customers by predicted CLV. Groupings include:
Note This attribute returns only the customers who belong to the selected value tier. For example, to return all of your top 10% customers, you must choose platinum, gold, and silver. Silver by itself will return 5% of your customers, specifically those are in your 5-10%. |
Predicted Order Frequency Next 365D |
Decimal |
The predicted number of orders over the next 365 days. |
Predicted Probability Of Transaction Next 365D |
Decimal |
The probability a customer will purchase again in the next 365 days. |
Stitch BadValues¶
The Stitch BadValues table has all of the values that were added to the bad-values blocklist.
The Stitch BadValues table has the following columns:
Column name |
Data type |
Description |
|---|---|---|
Datasource |
String |
The name of the data source from which the value originated. |
Semantic |
String |
The semantic tag that is associated with the value that was added to the bad-values blocklist. |
Value |
String |
The value that was added to the bad-values blocklist. |
Num Values |
String |
The number of times the value appeared in the data. |
Num Proxy |
String |
The number of proxies to which the value was associated. When this number exceeds the threshold defined for in the blocklist a value is added to the bad-values blocklist. |
Domain Table |
String |
The domain table from which the value originated. |
Is Preprocessed |
String |
Indicates if the value was changed during pre-processing by Stitch. For example, phone numbers often have dashes within their values. Dashes are removed by Stitch during pre-processing. When this column is true, and a phone number value is “12065551212”, the original value for that phone number in the associated datasource may be “1-206-555-1212”. |
Stitch Blocking Keys¶
The Stitch Blocking Keys table has all blocking keys used during identity resolution.
Note
The combination of BK, datasource, PK, and strategy forms the primary key. No values should be NULL.
The Stitch Blocking Keys table has the following columns:
Column name |
Data type |
Description |
|---|---|---|
BK |
String |
A blocking key defines a specific combination of characters for a blocking strategy. For example, the first three characters in given-name, the first character in surname, and birthdate represent a blocking key. |
Datasource |
String |
The name of the data source from which this customer profile originated. Tip The combination of PK and Datasource uniquely identifies a row in the Stitch Blocking Keys table, which correlates to a single row in a domain table. |
PK |
String |
The combination of data source and primary key allows Amperity to uniquely identify every row in every data table across the entirety of customer data input to Amperity. Tip The combination of PK and Datasource uniquely identifies a row in the Stitch Blocking Keys table, which correlates to a single row in a domain table. |
Strategy |
String |
A blocking strategy acts like a filter against large datasets. Each blocking strategy applies its filter. All matching records group together into a block. Each record that matches a blocking strategy is a blocking key. |
Stitch BlocklistValues¶
Note
The Stitch BlocklistValues table may be added after the bad-values blocklist is configured for your tenant.
The Stitch BlocklistValues table has the following columns:
Column name |
Data type |
Description |
|---|---|---|
Datasource |
String |
The name of the data source from which the blocklisted value originated. A value of |
Domain Table |
String |
The name of the domain table from which the blocklisted value originated. |
Num Proxy |
Integer |
The distinct number of individuals to which Num Values is associated. |
Num Values |
Integer |
The total number of values. |
PK |
String |
|
Semantic |
String |
The semantic type associated with the value that was blocklisted. For example: Email. |
Value |
String |
The value that was blocklisted. For example: |
Stitch Scores¶
The Stitch Scores table has all scores assigned by Stitch during identity resolution, including scores that are not associated with an Amperity ID. Use this table to help understand why records are not associated with an Amperity ID.
The Stitch Scores table has the following columns:
Column name |
Data type |
Description |
||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
Amperity ID1 |
String |
The unique identifier assigned to clusters of customer profiles that all represent the same individual. The Amperity ID does not replace primary, foreign, or other unique customer keys, but exists alongside them within unified profiles. The Amperity ID for the first of two compared records. Note The Amperity ID is a universally unique identifier (UUID) that is 36 characters spread across five groups separated by hyphens: 8-4-4-4-12. For example: 123e4567-e89b-12d3-a456-426614174000
|
||||||||||||||
Amperity ID2 |
String |
The Amperity ID for the second of two compared records. |
||||||||||||||
Match Category |
String |
A match category is applied to individual record-pair comparisons discovered by deterministic and probabilistic matching strategies during identity resolution.
|
||||||||||||||
Match Type |
String |
The score assigned to matched records is the match type. Possible values: “scored”, “scored_transitive”, and “trivial_duplicate”. Records assigned a “scored” value are directly connected by deterministic or probabilistic matching. Records assigned a “scored_transitive” value are transitively connected. |
||||||||||||||
PK1 |
String |
|||||||||||||||
PK2 |
String |
|||||||||||||||
Score |
Float |
A score has a value from “0.0” to “5.0” that represents the combined score assigned to the record pair by Stitch. A score has two parts: the score is on the left side and the score’s strength is on the right. The record pair score correlates to the match category, which is a classifier applied by Amperity to individual record pairs. The record pair score corresponds to the classification:
The record pair strength represents the strength of the record pair score assigned by Stitch during identity resolution. It is a two digit number. For example: .31 is a lower strength and .93 is a higher strength. |
||||||||||||||
Source1 |
String |
|||||||||||||||
Source2 |
String |
Transaction Attributes Extended¶
The Transaction Attributes Extended table has attributes for customer flags, customer orders, data differences, time period roll-ups, and RFM scores. Many extended attributes have duration, order position, frequency, and revenue.
The Transaction Attributes Extended table has the following columns:
Column name |
Data type |
Description |
|---|---|---|
Amperity ID |
String |
The unique identifier assigned to clusters of customer profiles that all represent the same individual. The Amperity ID does not replace primary, foreign, or other unique customer keys, but exists alongside them within unified profiles. This column is added when a transaction is associated with an Amperity ID from the Unified Transactions table. Note The Amperity ID is a universally unique identifier (UUID) that is 36 characters spread across five groups separated by hyphens: 8-4-4-4-12. For example: 123e4567-e89b-12d3-a456-426614174000
|
Early Repeat Purchaser |
Boolean |
Early repeat purchaser is a Boolean flag that indicates if a customer made a repeat purchase within 12 weeks, or 84 days. Tip Use the Early Repeat Purchaser attribute as a leading indicator for overall conversion rate of one-time buyers to repeat customers, even when it does not capture the total number of one-time buyers who have returned to purchase again. This column is calculated from the First Order Datetime and Second Order Datetime columns in the Transaction Attributes Extended table. |
First Order Datetime |
Datetime |
First order date is the date on which a customer placed their first order. This column is calculated from the Order Datetime column in the Unified Transactions table, which is created when the order-datetime semantic tag is applied to interaction records that contain transactions data. |
First Order ID |
String |
First order ID is the order ID for a customer’s first order. This column is calculated from the Order ID column in the Unified Transactions and Unified Itemized Transactions tables, which is created when the order-id semantic tag is applied to interaction records that contain transactions and itemized transactions data. |
First Order Is Retained |
Boolean |
First order is retained is a flag that indicates if a customer has made a repeat purchase within 365 days of their first order. |
First Order Revenue |
Decimal |
First order revenue is the total revenue connected with a customer’s first order, ignoring returned and canceled items. This column is calculated from the Order Revenue column in the Unified Transactions table, which is created when the order-revenue semantic tag is applied to interaction records that contain transactions data. |
First Order Total Items |
Integer |
First order total items represents the number of items purchased in a customer’s first order, ignoring returned and canceled items. This column is calculated from the Order Quantity column in the Unified Transactions table, which is created when the order-quantity semantic tag is applied to interaction records that contain transactions data. |
Latest Order Datetime |
Datetime |
Latest order date is the date on which the customer placed their most recent order. This column is calculated from the Order Datetime column in the Unified Transactions table, which is created when the order-datetime semantic tag is applied to interaction records that contain transactions data. |
Latest Order ID |
String |
Latest order ID is the order ID for a customer’s most recent order. This column is calculated from the Order ID column in the Unified Transactions and Unified Itemized Transactions tables, which is created when the order-id semantic tag is applied to interaction records that contain transactions and itemized transactions data. |
Latest Order Revenue |
Decimal |
Latest order revenue is the total revenue connected with a customer’s most recent order, ignoring returned and canceled items. This column is calculated from the Order Revenue column in the Unified Transactions table, which is created when the order-revenue semantic tag is applied to interaction records that contain transactions data. |
Latest Order Total Items |
Integer |
Latest order total items is the number of items purchased in a customer’s most recent order, ignoring returned and canceled items. This column is calculated from the Order Quantity column in the Unified Transactions table, which is created when the order-quantity semantic tag is applied to interaction records that contain transactions data. |
Lifetime Average Item Price |
Decimal |
The average individual item price for all orders, ignoring returns and cancellations. This column is calculated from the Order Quantity and Order Revenue columns in the Unified Transactions table, which are created when the order-quantity and order-revenue semantic tags are applied to interaction records that contain transactions data. |
Lifetime Average Num Items |
Decimal |
The average number of items purchased for all orders, ignoring returns and cancellations. This column is calculated from the Order ID and Order Quantity columns in the Unified Transactions table, which are created when the order-id and order-quantity semantic tags are applied to interaction records that contain transactions data. |
Lifetime Average Order Value |
Decimal |
The average lifetime revenue for all orders, ignoring returns and cancellations. This column is calculated from the Order ID and Order Revenue columns in the Unified Transactions table, which are created when the order-id and order-revenue semantic tags are applied to interaction records that contain transactions data. |
Lifetime Largest Order Value |
Decimal |
Lifetime largest order value identifies the largest order connected with a customer, ignoring returns and cancellations, for a customer’s entire purchase history. This column is calculated from the Order Revenue column in the Unified Transactions table, which is created when the order-revenue semantic tag is applied to interaction records that contain transactions data. |
Lifetime Order Frequency |
Integer |
A lifetime order frequency is the total number of orders that a customer has made during their entire relationship with your brand. This column is calculated from the Order ID column in the Unified Transactions and Unified Itemized Transactions tables, which is created when the order-id semantic tag is applied to interaction records that contain transactions and itemized transactions data. |
Lifetime Order Revenue |
Decimal |
The lifetime revenue for all items, ignoring returns and cancellations. This column is calculated from the Order Revenue column in the Unified Transactions table, which is created when the order-revenue semantic tag is applied to interaction records that contain transactions data. |
Lifetime Preferred Purchase Brand |
String |
The most frequent brand for all orders. |
Lifetime Preferred Purchase Channel |
String |
The most frequent purchase-channel for all orders. |
Lifetime Total Items |
Integer |
The lifetime number of individual items associated with the transaction, ignoring returns and cancellations. This column is calculated from the Order Quantity column in the Unified Transactions table, which is created when the order-quantity semantic tag is applied to interaction records that contain transactions data. |
Multi Purchase Brand |
Boolean |
A flag that indicates if a customer has interacted with more than one brand. This column is calculated from the Purchase Brand column in the Unified Transactions table, which is created when the purchase-brand semantic tag is applied to interaction records that contain transactions data. |
Multi Purchase Channel |
Boolean |
Multi-purchase channel is a flag that indicates if a customer has purchased from more than one channel. This column is calculated from the Purchase Channel column in the Unified Transactions table, which is created when the purchase-channel semantic tag is applied to interaction records that contain transactions data. |
One And Done |
Boolean |
One and done is a flag that indicates if a customer has made only one purchase. Important Amperity uses the range of data that is provided to it to identify one-time buyers. For example, if Amperity is provided data for the years 2015-2022, purchases made in 2014 are not used to identify one-time buyers. This column is calculated from the Lifetime Order Frequency column in the Transaction Attributes Extended table. |
Second Order Datetime |
Datetime |
Second order date is the date on which the customer placed their second order. This column is calculated from the Order Datetime column in the Unified Transactions and Unified Itemized Transactions tables, which is created when the order-datetime semantic tag is applied to interaction records that contain transactions and itemized transactions data. |
Second Order ID |
String |
Second order ID is the order ID for a customer’s second order. This column is calculated from the Order ID column in the Unified Transactions and Unified Itemized Transactions tables, which are created when the order-id semantic tag is applied to interaction records that contain transactions and itemized transactions data. |
Second Order Is Retained |
Boolean |
Second order is retained is a flag that indicates if a customer made a repeat purchase within 365 days of their second order. |
Second Order Revenue |
Decimal |
Second order revenue is the total revenue connected with a customer’s second order, ignoring returned and canceled items. This column is calculated from the Order Revenue column in the Unified Transactions table, which is created when the order-revenue semantic tag is applied to interaction records that contain transactions data. |
Second Order Total Items |
Integer |
Second order total items is the number of items purchased in a customer’s second order, ignoring returned and canceled items. This column is calculated from the Order Quantity column in the Unified Transactions table, which is created when the order-quantity semantic tag is applied to interaction records that contain transactions data. |
Transaction attributes, calculated¶
Extended transaction attributes–customer flags, customer orders, date differences, time period rollups, and RFM–are also calculated by Amperity based on data sources that contain interaction records that were tagged with transactions and itemized transaction semantics.
Extended transaction attributes are presented as a single table (with many columns), including an Amperity ID, and fit into the following categories:
Customer flags¶
Each record has a set of flags that indicate if a customer has purchased, the number of brand interactions, the number of brand channels, and if that customer is an early repeat purchaser.
Column Name |
Data type |
PII |
Description |
|---|---|---|---|
Amperity ID |
String |
An Amperity ID is a unique identifier assigned to a cluster of records within an identity graph. Each Amperity ID represents all of the records within a customer profile. |
|
Early Repeat Purchaser |
Boolean |
Early repeat purchaser is a Boolean flag that indicates if a customer made a repeat purchase within 12 weeks, or 84 days. Tip Use the Early Repeat Purchaser attribute as a leading indicator for overall conversion rate of one-time buyers to repeat customers, even when it does not capture the total number of one-time buyers who have returned to purchase again. |
|
Multi Purchase Brand |
Boolean |
A flag that indicates if a customer has interacted with more than one brand. This column is calculated from the Purchase Brand column in the Unified Transactions table, which is created when the purchase-brand semantic tag is applied to interaction records that contain transactions data. |
|
Multi Purchase Channel |
Boolean |
Multi-purchase channel is a flag that indicates if a customer has purchased from more than one channel. This column is calculated from the Purchase Channel column in the Unified Transactions table, which is created when the purchase-channel semantic tag is applied to interaction records that contain transactions data. |
|
One And Done |
Boolean |
One and done is a flag that indicates if a customer has made only one purchase. Important Amperity uses the range of data that is provided to it to identify one-time buyers. For example, if Amperity is provided data for the years 2015-2022, purchases made in 2014 are not used to identify one-time buyers. |
Customer orders¶
Each record has a subset of order data from a customers first, second, and latest order. Each set of attributes is prefixed by first, second, or latest, depending on the order data that is being summarized.
Column Name |
Data type |
PII |
Description |
|---|---|---|---|
<X> Order Datetime |
Datetime |
The datetime on which the order was made. Available columns:
|
|
<X> Order ID |
String |
The ID of the order. Available columns:
|
|
<X> Order Purchase Brand |
String |
The brand of the order made by the customer. Available columns:
|
|
<X> Order Purchase Channel |
String |
The channel in which the customer’s order was made. Available columns:
|
|
<X> Order Revenue |
Decimal |
The total revenue for orders at each interval. Available columns:
|
|
<X> Store ID |
String |
The ID of the store where the customer made their order. This value may be NULL if the associated channel is not retail or some equivalent. Available columns:
|
|
<X> Total Items |
Integer |
The total number of items in the order. Available columns:
|
Date differences¶
Each record has three attributes that specify the number of days between certain events.
Column Name |
Data type |
PII |
Description |
|---|---|---|---|
Days Since Latest Order |
Integer |
Days since latest order measures the number of days that have elapsed since a customer has placed an order. |
|
First To Latest Order Days |
Integer |
First-to-latest order days is the number of days that have elapsed between the date of the first order and the date of the latest order. |
|
First To Second Order Days |
Integer |
First-to-second order days is the number of days that have elapsed between the date of the first order and the date of the second order. |
Time period rollups¶
Each record has time period rollups of the customer’s transaction history. The time periods used are lifetime, L12M (the 12 months of transaction history starting 12 months ago), LY12M (the 12 months of transaction history starting 24 months ago), and L30D (the last 30 days).
Column Name |
Data type |
PII |
Description |
|---|---|---|---|
<X> Average Item Price |
Decimal |
The average item price during the time period. Available columns:
|
|
<X> Average Net Item Price |
Decimal |
The average net item price during the time period, minus returns, cancellations, and discounts. Available columns:
Note These attributes must be enabled in the SQL template for the Transaction Attributes Extended table. |
|
<x> Average Num Items |
Decimal |
The average number of items during the time period. Available columns:
|
|
<X> Average Order Value |
Decimal |
The average order value during the time period. Available columns:
|
|
<X> Largest Net Order Value |
Decimal |
The total value for the largest orders in the time period, minus returns, cancellations, and discounts. Available columns:
Note These attributes must be enabled in the SQL template for the Transaction Attributes Extended table. |
|
<X> Net Order Revenue |
Decimal |
The net order revenue for orders in the time period, minus returns, cancellations, and discounts. Available columns:
Note These attributes must be enabled in the SQL template for the Transaction Attributes Extended table. |
|
<X> Net Order Value |
Decimal |
The total value for orders in the time period, minus returns, cancellations, and discounts. Available columns:
Note These attributes must be enabled in the SQL template for the Transaction Attributes Extended table. |
|
<X> Order Cost |
Datetime |
The cost for an order during the time period. Available columns:
|
|
<X> Order Frequency |
Integer |
The count of distinct order IDs that are associated with the customer during the time period. Available columns:
|
|
<X> Order Canceled Frequency |
Integer |
The count of distinct order IDs that are associated with canceled items during the time period. Available columns:
Note These attributes must be enabled in the SQL template for the Transaction Attributes Extended table. |
|
<X> Order Returned Frequency |
Integer |
The count of distinct order IDs that are associated with returned items during the time period. Available columns:
Note These attributes must be enabled in the SQL template for the Transaction Attributes Extended table. |
|
<X> Order Revenue |
Decimal |
The total revenue for orders in the time period. Available columns:
|
|
<X> Order canceled Revenue |
Decimal |
The total revenue for canceled items in the time period. Available columns:
Note These attributes must be enabled in the SQL template for the Transaction Attributes Extended table. |
|
<X> Order Returned Revenue |
Decimal |
The total revenue for returned items in the time period. Available columns:
Note These attributes must be enabled in the SQL template for the Transaction Attributes Extended table. |
|
<X> Preferred Purchase Brand |
String |
The brand with the greatest number of orders during the time period. Available columns:
|
|
<X> Preferred Purchase Channel |
String |
The channel with the greatest number of orders during the time period. Available columns:
|
|
<X> Preferred Store ID |
String |
The store ID with the greatest number of orders during the time period. Available columns:
|
|
<X> Purchase Brands |
Integer |
The count of the distinct brands a customer interacted with during the time period. Available columns:
|
|
<X> Purchase Channels |
Integer |
The count of the distinct channels (online, in store, etc.) that the customer interacted with during the time period. Available columns:
|
|
<X> Stores |
Integer |
The count of the distinct stores that the customer interacted with during the time period. Available columns:
|
|
<X> Total Items |
Integer |
The total number of items purchased by the customer during the time period. Available columns:
|
|
<X> Total canceled Items |
Integer |
The total number of items canceled by the customer during the time period. Available columns:
Note These attributes must be enabled in the SQL template for the Transaction Attributes Extended table. |
|
<X> Total Returned Items |
Integer |
The total number of items returned by the customer during the time period. Available columns:
Note These attributes must be enabled in the SQL template for the Transaction Attributes Extended table. |
RFM¶
Amperity calculates RFM scores against transactions that occurred within the last 12 months.
Each of the recency (R), frequency (F), and monetary (M) scores are represented by a number between 0 and 9. The final RFM score is a concatenation of the individual scores: recency first, then frequency, monetary last. The final RFM score is between 0 and 999.
Note
RFM uses approximate calculations to optimize the performance of the Transaction Attributes Extended table.
Column Name |
Data type |
PII |
Description |
|---|---|---|---|
L12M RFM Score |
Integer |
The RFM score for the customer is based on transactions that occurred within the last 12 months. The RFM score is represented as an integer between “111” and “101010”. This is a concatenated score that uses each of the individual recency, frequency, and monetary scores. The order is recency, then frequency, and then monetary. For example, you can build an audience that has your top 20% customers for recency, your top 30% customers for frequency, and your top 10% customers for monetary by setting the L12M RFM Score attribute to “9810” (or “9” for recency, “8” for frequency, and then “10” for monetary). 
|
|
L12M Recency |
Integer |
L12M Recency is a score that sorts customers by how recently they purchased during the previous 12 months. Each RFM score is split into ten percentile groups. The lowest percentile is 1 and the highest percentile is 10. Each percentile represents 10% of the customers who belong to that segment.
Tip Combine percentiles to build larger groups of customers. For example 9 and 10 together represent the “top 20%” while 8, 9, and 10 represent the “top 30%”. |
|
L12M Frequency |
Integer |
L12M Frequency is a score that sorts customers by purchase frequency during the previous 12 months. Each RFM score is split into ten percentile groups. The lowest percentile is 1 and the highest percentile is 10. Each percentile represents 10% of the customers who belong to that segment.
Tip Combine percentiles to build larger groups of customers. For example 9 and 10 together represent the “top 20%” while 8, 9, and 10 represent the “top 30%”. |
|
L12M Monetary |
Integer |
L12M Monetary is a score that sorts customers by spend amount during the previous 12 months. Each RFM score is split into ten percentile groups. The lowest percentile is 1 and the highest percentile is 10. Each percentile represents 10% of the customers who belong to that segment.
Tip Combine percentiles to build larger groups of customers. For example 9 and 10 together represent the “top 20%” while 8, 9, and 10 represent the “top 30%”. |
UID2¶
Unified ID 2.0 (UID2) is an open-source framework that enables deterministic identity for advertising opportunities across the open internet for participants with access to the advertising ecosystem. UID2 is a standalone solution with a unique namespace and privacy controls that help participants meet local market requirements.
The UID2 table has the results of UID2 token generation when enabled for your tenant.
The UID2 table has the following columns:
Column name |
Data type |
Description |
|---|---|---|
Bucket ID |
String |
A unique identifier for the salt bucket used to ensure that expired UID2 tokens are refreshed. This value is returned in the response from the POST /identity/map endpoint. Note Each UID2 token is associated with a salt bucket that links that token to a specific point in time. Salt buckets expire. Approximately 1/365th of all salt buckets are rotated daily. Amperity monitors salt buckets on a daily basis to determine which UID2 tokens need to be refreshed. |
String |
The email address for the customer. Amperity gets this value from the email field in the Unified Coalesced table. |
|
Normalized Email |
String |
The normalized email address sent from Amperity to the POST /identity/map endpoint for mapping. This value is returned in the response from the POST /identity/map endpoint. |
UID2 |
String |
The raw UID2 value for the customer. This value, when encrypted, may be used as a UID2 token. This value is returned in the response from the POST /identity/map endpoint. |
The UID2 History table has the following columns:
Column name |
Data type |
Description |
|---|---|---|
Bucket ID |
String |
The salt bucket ID associated with this version of the UID2 token. |
Created At |
Datetime |
The timestamp at which this version of the UID2 token was recorded. |
String |
The email address for the customer. Amperity gets this value from the email field in the Unified Coalesced table. |
|
Normalized Email |
String |
The normalized email address used when generating the UID2 token. |
UID2 |
String |
The raw UID2 token value at the time this record was written. |
Unified Changes Clusters¶
The Unified Changes Clusters table has a history of changes to cluster graphs, relative to the previous identity graph.
The Unified Changes Clusters table has the following columns:
Column name |
Data type |
Description |
|---|---|---|
Amperity ID |
String |
The unique identifier assigned to clusters of customer profiles that all represent the same individual. The Amperity ID does not replace primary, foreign, or other unique customer keys, but exists alongside them within unified profiles. Note The Amperity ID is a universally unique identifier (UUID) that is 36 characters spread across five groups separated by hyphens: 8-4-4-4-12. For example: 123e4567-e89b-12d3-a456-426614174000
|
Change Type |
String |
The type of change that occurred within the Stitch job. Possible values include:
Also in: Unified Changes PKS |
Job ID |
String |
The job ID for database table generation. For example: Also in: Unified Changes PKS |
Timestamp |
Datetime |
The timestamp that is associated with Job ID. Each row that shares the same job ID have the same value for Timestamp. Also in: Unified Changes PKS |
Unified Changes PKS¶
The Unified Changes PKS table has a history of changes to primary keys, relative to the previous identity graph.
The Unified Changes PKS table has the following columns:
Column name |
Data type |
Description |
|---|---|---|
Amperity ID |
String |
The unique identifier assigned to clusters of customer profiles that all represent the same individual. The Amperity ID does not replace primary, foreign, or other unique customer keys, but exists alongside them within unified profiles. Note The Amperity ID is a universally unique identifier (UUID) that is 36 characters spread across five groups separated by hyphens: 8-4-4-4-12. For example: 123e4567-e89b-12d3-a456-426614174000
|
Amperity ID Prev |
String |
The Amperity ID that was previously associated with the primary key ( |
Change Type |
String |
The type of change that occurred within the Stitch job. Possible values include:
Also in: Unified Changes Clusters |
Datasource |
String |
The name of the data source from which this customer profile originated. Tip The combination of PK and Datasource uniquely identifies a row in the Unified Coalesced table, which correlates to a single row in a domain table. |
Job ID |
String |
The job ID for database table generation. For example: Also in: Unified Changes Clusters |
PK |
String |
The combination of data source and primary key allows Amperity to uniquely identify every row in every data table across the entirety of customer data input to Amperity. Tip The combination of PK and Datasource uniquely identifies a row in the Unified Coalesced table, which correlates to a single row in a domain table. |
Timestamp |
Datetime |
The timestamp that is associated with Job ID. Each row that shares the same job ID have the same value for Timestamp. Also in: Unified Changes Clusters |
Unified Coalesced¶
The Unified Coalesced table has all PII data processed through Stitch. Each semantic tag is a column header. All data is coalesced into a single table. A unique Amperity ID may appear in more than one row.
The Unified Coalesced table has the following columns:
Column name |
Data type |
Description |
|---|---|---|
Amperity ID |
String |
The unique identifier assigned to clusters of customer profiles that all represent the same individual. The Amperity ID does not replace primary, foreign, or other unique customer keys, but exists alongside them within unified profiles. Note The Amperity ID is a universally unique identifier (UUID) that is 36 characters spread across five groups separated by hyphens: 8-4-4-4-12. For example: 123e4567-e89b-12d3-a456-426614174000
|
Address |
String |
The address connected with the location of a customer, such as “123 Main Street”. Values in this column depend on fields that are tagged with the Address semantic. Also in: Customer 360, Merged Customers, Unified Customer, Unified Preprocessed Raw |
Address2 |
String |
Address information, such as an apartment number or a post office box, connected with the location of a customer, such as “Apt #9”. Values in this column depend on fields that are tagged with the Address2 semantic. Also in: Merged Customers, Unified Customer |
Birthdate |
Date |
The date of birth connected with a customer. Values in this column depend on fields that are tagged with the birthdate semantic. Also in: Customer 360, Merged Customers, Unified Customer, Unified Preprocessed Raw |
BLV Address |
Boolean |
When true, the address on this customer profile matches a blocklist value. |
BLV Email |
Boolean |
When true, the email on this customer profile matches a blocklist value. |
BLV Given Name |
Boolean |
When true, the given-name on this customer profile matches a blocklist value. |
BLV Phone |
Boolean |
When true, the phone on this customer profile matches a blocklist value. |
BLV Surname |
Boolean |
When true, the surname on this customer profile matches a blocklist value. |
City |
String |
The city connected with the location of a customer. Values in this column depend on fields that are tagged with the City semantic. Also in: Customer 360, Merged Customers, Unified Customer, Unified Preprocessed Raw |
CK |
String |
The ck semantic tag identifies pre-existing, tenant-specific customer IDs. Amperity compares customer keys to the Amperity ID as part of the deduplication process. Tip What happens to customer keys in the Unified Coalesced table?
Also in: Unified Customer |
Component ID |
Integer |
An identifier that represents a set of records that are transitively connected. Records that share a component ID, but have different Amperity IDs, are split during identity resolution. Tip Records with different component_id values may show as having blocked together. This can occur after removing a connecting record pair that scored below the pairwise comparison threshold. Also in: Unified Preprocessed Raw |
Country |
String |
The country connected with the location of a customer. Values in this column depend on fields that are tagged with the Country semantic. Important The country field is added to the Unified Coalesced table when fields are tagged with the country profile semantic. Also in: Merged Customers, Unified Customer |
Create DT |
String |
Apply the create-dt semantic tag to columns that identify the creation date or time. The field must be a datetime field type. Also in: Merged Customers, Unified Customer |
Datasource |
String |
The name of the data source from which this customer profile originated. Tip The combination of PK and Datasource uniquely identifies a row in the Unified Coalesced table, which correlates to a single row in a domain table. |
String |
The email address connected with a customer. A customer may have more than one email address. Values in this column depend on fields that are tagged with the Email semantic. Also in: Customer 360, Merged Customers, Unified Customer, Unified Preprocessed Raw |
|
FK [Name] |
String |
The fk-[namespace] semantic tag identifies a field as a foreign key. A foreign key semantic tag must use a namespace and “namespace” is a string of characters. For example: fk-customer-id, fk-interaction, fk-audience, fk-loyalty-id, or fk-brand. A column is added for each foreign key that is defined in the Sources page. Tip What happens to foreign keys in the Unified Coalesced table?
Also in: Unified Customer, Unified Preprocessed Raw |
Full Name |
String |
A combination of given name and surname–or first name and last name–for a customer. Amperity selects the first non-nil value:
Also in: Merged Customers, Unified Customer |
Gender |
String |
The gender connected with a customer. Values in this column depend on fields that are tagged with the Gender semantic. Also in: Customer 360, Merged Customers, Unified Customer, Unified Preprocessed Raw |
Generational Suffix |
String |
The suffix that identifies to which family generation a customer record belongs. For example: Jr., Sr. II, and III. Also in: Merged Customers, Unified Customer |
Given Name |
String |
The first name connected with a customer. Values in this column depend on fields that are tagged with the Given Name semantic. Also in: Customer 360, Merged Customers, Unified Customer, Unified Preprocessed Raw |
Has BLV |
Boolean |
The has_blv column indicates if blocklist values for address, email, phone, given-name, or surname are present in customer profiles. |
Is Supersized |
Boolean |
Indicates when a rough heuristic applies to the first grouping of records–the rep_pk field–to partition supersized records into smaller parts. Supersized records occur when more than 500 groups associate with the first grouping of records. |
Loyalty ID |
String |
The identifier for a loyalty program connected with a customer. This column is added when the loyalty-id semantic tag is applied to customer profiles. Also in: Merged Customers |
Phone |
String |
The phone number connected with a customer. A customer may have more than one phone number. Values in this column depend on fields that are tagged with the Phone semantic. Also in: Customer 360, Merged Customers, Unified Customer, Unified Preprocessed Raw |
PK |
String |
The combination of data source and primary key allows Amperity to uniquely identify every row in every data table across the entirety of customer data input to Amperity. Tip The combination of PK and Datasource uniquely identifies a row in the Unified Coalesced table, which correlates to a single row in a domain table. |
Postal |
String |
The ZIP code or postal code connected with the location of a customer. Values in this column depend on fields that are tagged with the postal semantic. Also in: Customer 360, Merged Customers, Unified Customer, Unified Preprocessed Raw |
Rep DS |
Integer |
The rep_ds column shows the data source connected with the rep_pk column. |
Rep PK |
Integer |
The rep_pk column is an identifier that represents the first grouping of records done by Stitch. This grouping relies on semantic patterns. Tip The combination of Rep DS and Rep PK represent qualified trivial duplications, which are records with enough identical PII to score 3.0 (or greater) and were grouped together by Stitch early in the identity resolution process. All qualified trivial duplicates are treated as a single record by downstream Stitch processes. The Rep DS and Rep PK fields are included in the Unified Coalesced table to help with situations where it is necessary to understand why two records were not clustered together. |
State |
String |
The state or province connected with the location of a customer. Values in this column depend on fields that are tagged with the state semantic. Also in: Customer 360, Merged Customers, Unified Customer, Unified Preprocessed Raw |
Supersized ID |
Integer |
An identifier represents supersized records partitioned into smaller parts. Also in: Unified Preprocessed Raw |
Surname |
String |
The last name connected with a customer. Values in this column depend on fields that are tagged with the Surname semantic. Also in: Customer 360, Merged Customers, Unified Customer, Unified Preprocessed Raw |
Title |
String |
The title that precedes a full name connected with a customer, such as “Mr”, “Mrs”, and “Dr”. Also in: Merged Customers, Unified Customer |
Update DT |
String |
Apply the update-dt semantic tag to datetime fields in customer profiles that identify the most recent update in the source system. At least one customer profile must have this semantic tag applied to ensure that the update_dt column exists in the Unified Coalesced table. Also in: Merged Customers, Unified Customer |
Unified Compliance¶
The Unified Compliance table supports privacy rights workflows and has the search results for data subject access requests (DSAR) and customer delete requests. Each matching record has a row in the Unified Compliance table.
Column name |
Data type |
Description |
|---|---|---|
Request Datasource |
String |
The location (database and table) from which the request to find matching records originated. |
Request ID |
Integer |
An identifier for the request to find matching records. |
Request Type |
String |
The request type for the compliance action. May be one of: delete, delete_pii, or dsar. |
Request Strategy |
String |
The request strategy for the compliance action. May be one of: exact or connected_pii. |
Request Semantic |
String |
The type of PII used to search for matching records. For example: email, address, or phone. |
Request Semantic Value |
String |
The value that was used to search for matching records. For example: paul.jackson@amperity.com. |
Request Match Category |
String |
The match category will be direct for matches on pii, connected for matches on the amperity-id of a direct match, and source_key or linkage_table for upstream source records. |
Amperity ID |
String |
The unique identifier assigned to clusters of customer profiles that all represent the same individual. The Amperity ID does not replace primary, foreign, or other unique customer keys, but exists alongside them within unified profiles. |
Datasource |
String |
The location (database and table) in which the matched record was found. |
PK |
String |
The primary key for the matched record. |
PII columms |
String |
A series of column names. Each added PII column matches the name of a column in which matching records were found. |
Unified Compliance Overview¶
The Unified Compliance Overview table has an overview of the results of data subject access requests (DSAR) and customer delete requests. The overview includes the number of records found, the time at which the request completed, and the request type.
Column name |
Data type |
Description |
|---|---|---|
Request Datasource |
String |
The location (database and table) from which the request to find matching records originated. |
Record Completion Date |
Datetime |
A timestamp that indicates when the request was completed. |
Request ID |
String |
An identifier for the request. |
Request Type |
String |
The request type for the compliance action. May be one of: delete, delete_pii, or dsar. |
Request Strategy |
String |
The request strategy for the compliance action. May be one of: exact or connected_pii. |
Request Email |
String |
Optional The email address used to match to source table records, if provided. |
Request Phone |
String |
Optional The phone number used to match to source table records, if provided. |
Request Address |
String |
Optional The street address used as part of an address group to match to source table records, if provided. |
Request Address2 |
String |
Optional The address2 field used as part of an address group to match to source table records, if provided. |
Request City |
String |
Optional The city used as part of an address group to match to source table records, if provided. |
Request State |
String |
Optional The state used as part of an address group to match to source table records, if provided. |
Request Postal |
String |
Optional The postal code used as part of an address group to match to source table records, if provided. |
Request Country |
String |
Optional The country used as part of an address group to match to source table records, if provided. |
Request Custom Key |
String |
Optional The custom key used to match to source table records, if provided. |
Rows Found |
String |
The number of matching records that were discovered by the request. |
Unified Customer¶
The Unified Customer table has every row of every stitched table with all semantics coalesced into a single column. Stitch removes bad values and supersized clusters. A unique Amperity ID may appear in more than one row.
Note
See Unified Customers for more information about how this table is built and maintained within the customer 360 database.
Note
This table is similar to the Unified Coalesced table, but will not contain columns related to blocklists or supersized clusters.
The Unified Customer table has the following columns:
Column name |
Data type |
Description |
|---|---|---|
Amperity ID |
String |
The unique identifier assigned to clusters of customer profiles that all represent the same individual. The Amperity ID does not replace primary, foreign, or other unique customer keys, but exists alongside them within unified profiles. Note The Amperity ID is a universally unique identifier (UUID) that is 36 characters spread across five groups separated by hyphens: 8-4-4-4-12. For example: 123e4567-e89b-12d3-a456-426614174000
|
Address |
String |
The address connected with the location of a customer, such as “123 Main Street”. Values in this column depend on fields that are tagged with the Address semantic. Also in: Customer 360, Merged Customers, Unified Coalesced, Unified Preprocessed Raw |
Address2 |
String |
Address information, such as an apartment number or a post office box, connected with the location of a customer, such as “Apt #9”. Values in this column depend on fields that are tagged with the Address2 semantic. Also in: Merged Customers, Unified Coalesced |
Birthdate |
Date |
The date of birth connected with a customer. Values in this column depend on fields that are tagged with the Birthdate semantic. Also in: Customer 360, Merged Customers, Unified Coalesced, Unified Preprocessed Raw |
City |
String |
The city connected with the location of a customer. Values in this column depend on fields that are tagged with the City semantic. Also in: Customer 360, Merged Customers, Unified Coalesced, Unified Preprocessed Raw |
CK |
String |
The ck semantic tag identifies pre-existing, tenant-specific customer IDs. Amperity compares customer keys to the Amperity ID as part of the deduplication process. Also in: Unified Coalesced |
Country |
String |
The country connected with the location of a customer. Values in this column depend on fields that are tagged with the Country semantic. Also in: Merged Customers, Unified Coalesced |
Create DT |
String |
Apply the create-dt semantic tag to columns that identify the creation date or time. The field must be a datetime field type. Also in: Merged Customers, Unified Coalesced |
Datasource |
String |
The name of the data source from which this customer profile originated. |
String |
The email address connected with a customer. A customer may have more than one email address. Values in this column depend on fields that are tagged with the Email semantic. Also in: Customer 360, Merged Customers, Unified Coalesced, Unified Preprocessed Raw |
|
FK [Name] |
String |
The fk-[namespace] semantic tag identifies a field as a foreign key. A foreign key semantic tag must use a namespace and “namespace” is a string of characters. For example: fk-customer-id, fk-interaction, fk-audience, fk-loyalty-id, or fk-brand. A column is added for each foreign key that is defined in the Sources page. Tip What happens to foreign keys in the Unified Coalesced table?
Also in: Unified Coalesced, Unified Preprocessed Raw |
Full Name |
String |
A combination of given name and surname–or first name and last name–for a customer. Amperity selects the first non-nil value:
Also in: Merged Customers, Unified Coalesced |
Gender |
String |
The gender connected with a customer. Values in this column depend on fields that are tagged with the Gender semantic. Also in: Customer 360, Merged Customers, Unified Coalesced, Unified Preprocessed Raw |
Generational Suffix |
String |
The suffix that identifies to which family generation a customer record belongs. For example: Jr., Sr. II, and III. Also in: Merged Customers, Unified Coalesced |
Given Name |
String |
The first name connected with a customer. Values in this column depend on fields that are tagged with the given-name semantic. Also in: Customer 360, Merged Customers, Unified Coalesced, Unified Preprocessed Raw |
Loyalty ID |
String |
The identifier for a loyalty program connected with a customer. |
Phone |
String |
The phone number connected with a customer. A customer may have more than one phone number. Values in this column depend on fields that are tagged with the Phone semantic. Also in: Customer 360, Merged Customers, Unified Coalesced, Unified Preprocessed Raw |
PK |
String |
The combination of data source and primary key allows Amperity to uniquely identify every row in every data table across the entirety of customer data input to Amperity. |
Postal |
String |
The ZIP code or postal code connected with the location of a customer. Values in this column depend on fields that are tagged with the Postal semantic. Also in: Customer 360, Merged Customers, Unified Coalesced, Unified Preprocessed Raw |
State |
String |
The state or province connected with the location of a customer. Values in this column depend on fields that are tagged with the state semantic. Customer 360, Merged Customers, Unified Coalesced, Unified Preprocessed Raw |
Surname |
String |
The last name connected with a customer. Values in this column depend on fields that are tagged with the surname semantic. Also in: Customer 360, Merged Customers, Unified Coalesced, Unified Preprocessed Raw |
Title |
String |
The title that precedes a full name connected with a customer, such as “Mr”, “Mrs”, and “Dr”. Also in: Merged Customers, Unified Coalesced |
Update DT |
String |
Apply the update-dt semantic tag to datetime fields in customer profiles that identify the most recent update in the source system. At least one customer profile must have this semantic tag applied to ensure that the update_dt column exists in the Unified Coalesced table. Also in: Merged Customers, Unified Coalesced |
Unified Email Events¶
The Unified Email Events table has individual email event information, such as sends, opens, clicks, opt-in and opt-out preferences, bounces, and conversions. Apply email event semantic tags to data sources to have Stitch generate this table.
Important
This table is only generated when email-events semantic tags are applied to data sources that provide at least 15 months of data for raw email events.
The Unified Email Events table has the following columns:
Column name |
Data type |
Description |
|---|---|---|
Brand |
String |
The brand or company from which an email was sent. Values in this column depend on fields that are tagged with the email-event/brand semantic. |
Datasource |
String |
|
String |
The email address to which an email was sent. Values in this column depend on fields that are tagged with the email-event/email semantic. |
|
Event Datetime |
Datetime |
The date and time at which email event occurred. Values in this column depend on fields that are tagged with the email-event/event-datetime semantic. |
Event Type |
String |
The type of email event. Possible values:
Important The values for email event types must spelled as expected to ensure the Email Engagement Summary can summarize email events. For example: “Optin” may not be “Opt-in”. Values in this column depend on fields that are tagged with the email-event/event-type semantic. |
PK |
String |
|
Region |
String |
The region or location from which an email was sent. The region or location is typically associated to a single brand. Values in this column depend on fields that are tagged with the email-event/region semantic. |
Send ID |
String |
The unique identifier for the email that was sent to an email address at a specific date and time. If a data source does not provide a send ID a unique key is generated. Values in this column depend on fields that are tagged with the email-event/send-id semantic. |
Unified Itemized Transactions¶
The Unified Itemized Transactions table has rows of transactional data summarized to the item level, and then coalesced into a single column for each unique combination of order ID and product ID. The order ID is unique by Amperity ID.
Note
These columns are created when txn-item semantics are applied to interaction records that contain itemized transaction data.
The following diagram shows an example of the Unified Itemized Transactions table (click to view a larger diagram):
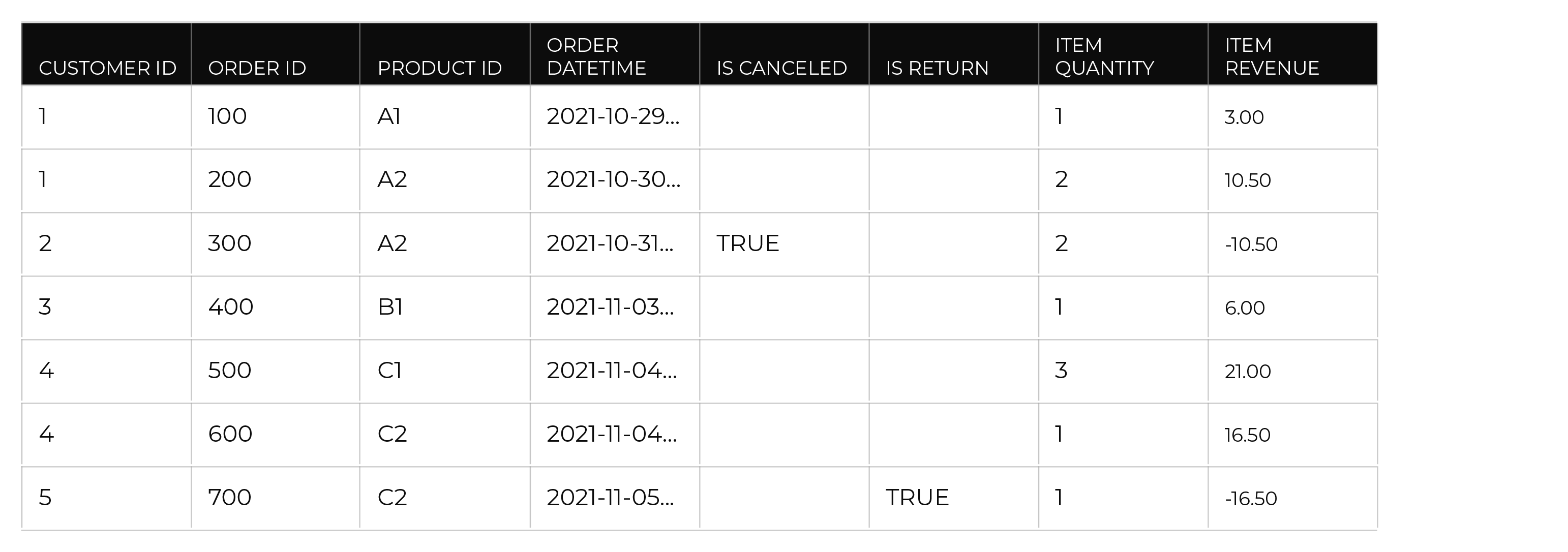
The Unified Itemized Transactions table has the following columns:
Column name |
Data type |
Description |
|---|---|---|
Amperity ID |
String |
The unique identifier assigned to clusters of customer profiles that all represent the same individual. The Amperity ID does not replace primary, foreign, or other unique customer keys, but exists alongside them within unified profiles. Note The Amperity ID is a universally unique identifier (UUID) that is 36 characters spread across five groups separated by hyphens: 8-4-4-4-12. For example: 123e4567-e89b-12d3-a456-426614174000
|
Customer ID |
String |
A customer ID is an identifier that uniquely identifies a customer within a dataset. For example, a loyalty ID, a mobile app ID, or a login name from a website. A customer ID may appear once for each unique order ID in the itemized transactions table. Note A namespaced foreign key may be used instead of (or in addition to) a customer ID. Values in this column depend on fields that are tagged with the txn-item/customer-id semantic or a foreign key. Also in: Unified Transactions |
Currency |
String |
Currency represents the currency used to pay for an item. The value should be a three character alphabetic ISO 4217 currency code , such as “USD” (United States dollar), “JPY” (Japanese Yen), “GBP” (Great Britain pound), or “EUR” (Euro). Note Currency must be consistent across all orders from the same data source. Values in this column depend on fields that are tagged with the txn-item/currency semantic. |
Digital Channel |
String |
The digital channel for a transaction. For example: Facebook, Google Ads, email, TikTok Ads, or Reddit. Note This column should only have values when purchase-channel specifies an online channel. Values in this column depend on fields that are tagged with the txn-item/digital-channel semantic. |
Is Cancellation |
Boolean |
A flag that identifies a canceled item. Values in this column depend on fields that are tagged with the txn-item/is-cancellation semantic. Important This value should be TRUE when items are canceled and FALSE when items are purchases and NULL when the value is unknown. |
Is Return |
Boolean |
This column is input to predictive modeling. A flag that identifies a returned item. Values in this column depend on fields that are tagged with the txn-item/is-return semantic. Important This value should be TRUE when items are returns and FALSE when items are purchases and NULL when the value is unknown. |
Item Cost |
Decimal |
Item cost is the cost to produce all units of an item. Note This value must be greater than or equal to 0 for purchases, but less than or equal to 0 for returns or cancellations. Values in this column depend on fields that are tagged with the txn-item/item-cost semantic. |
Item Discount Amount |
Decimal |
Item discount amount is the discount amount applied to all units of a single item within a single transaction. This value should equal item quantity multiplied by unit discount amounts. This value is used by Amperity for discount sensitivity analysis. Note This value must be greater than or equal to 0 for purchases, but less than or equal to 0 for returns or cancellations. Values in this column depend on fields that are tagged with the txn-item/item-discount-amount semantic. |
Item Discount Percent |
Decimal |
Item discount percent is the percentage discount applied to all units of a single item within a single transaction. This value is used by Amperity for discount sensitivity analysis. Note This value must be between 0 and 1. Values in this column depend on fields that are tagged with the txn-item/item-discount-percent semantic. |
Item List Price |
Decimal |
Item list price is the manufacturer’s suggested retail price (MSRP) for all units of this item. The manufacturer’s suggested retail price (MSRP) is the price before applying shipping costs, taxes, and discounts. MSRP is sometimes referred to as the base price. This value should equal item revenue plus item discount amount. Note This value must be greater than or equal to 0 for purchases, but less than or equal to 0 for returns or cancellations. Values in this column depend on fields that are tagged with the txn-item/item-list-price semantic. |
Item Profit |
Decimal |
Item profit represents the amount of profit earned after selling all units of an item. Note This value must be greater than or equal to 0 for purchases, but less than or equal to 0 for returns or cancellations. Values in this column depend on fields that are tagged with the txn-item/item-profit semantic. |
Item Quantity |
Integer |
This column is input to predictive modeling. Item quantity is the total number of items in an order. For returned and canceled items, item quantity is the total number of returned or canceled items. Note This value must be less than or equal to 0 when is-return or is-cancellation are true. Values in this column depend on fields that are tagged with the txn-item/item-quantity semantic. |
Item Revenue |
Decimal |
This column is input to predictive modeling. The total revenue for all units of an item, after applying discounts. For returned and canceled items, the total revenue for all returned or canceled items. This value should equal item quantity multiplied by unit revenue. Note This value must be less than or equal to 0 when is-return or is-cancellation are true. Tip A return or cancellation is stored as a separate record in the Unified Itemized Transactions table and is identified by a value of true in the Is Return or Is Cancellation column. Values in this column depend on fields that are tagged with the txn-item/item-revenue semantic. |
Item Subtotal |
Decimal |
An item subtotal is the amount for an item, after applying discounts. This value should equal unit list price times item quantity. This value is used by Amperity for discount sensitivity analysis. Note This value must be greater than or equal to 0 for purchases, but less than or equal to 0 for returns or cancellations. Values in this column depend on fields that are tagged with the txn-item/item-subtotal semantic. |
Item Tax Amount |
Decimal |
An item tax amount is the total amount of taxes paid for purchases. Note This value must be greater than or equal to 0 for purchases, but less than or equal to 0 for returns or cancellations. Values in this column depend on fields that are tagged with the txn-item/item-tax-amount semantic. |
Order Datetime |
Datetime |
This column is input to predictive modeling. Order datetime is the date and time on which a customer places an order. Note Other dates associated with an order that are not specific to a transactions, such as dates associated with hotel stays and reservations, should be added to the Unified Product Catalog table. When Is Return is TRUE, the date and time on which the order was returned. When IS Cancellation is TRUE, the date and time on which the order was canceled. Values in this column depend on fields that are tagged with the txn-item/order-datetime semantic. This column is used to calculate the following transaction attributes:
Also in: Unified Transactions |
Order Discount Amount |
Decimal |
This column is input to predictive modeling. Order discount amount is the total discount amount applied to the entire order. Note This value must be greater than or equal to 0 for purchases, but less than or equal to 0 for returns or cancellations. Caution This value should match the customer’s definition of an order-level discount. For example, some customers associate this value to order value, whereas others associate this value to a subtotal. Use domain SQL to update this field for the desired calculation. Also in: Unified Transactions |
Order ID |
String |
This column is input to predictive modeling. An order ID is the unique identifier for the order. It links together all items in the same transaction. For returns and cancellations, the order ID is the unique identifier for the original order, including returned or canceled items. This field is often the primary key and associated with the pk semantic tag. Note For data that has itemized transactions, where a single transaction includes more than one of the same item, the order ID appears more than once. Note The order ID should never change, even when an item in the order is returned or canceled. Caution If order IDs are recycled and are otherwise not guaranteed to be unique over time, the unique identifier for the order must be updated to be a combination of the order ID and the date on which the order occurred. This must be done using domain SQL similar to: Values in this column depend on fields that are tagged with the txn-item/order-id semantic. The combination of Order ID and Product ID must be unique for each row in this table. This column is used to calculate the following transaction attributes:
Also in: Unified Transactions |
Payment Method |
String |
A payment method is how a customer chose to pay for the items they have purchased. For example: credit card, gift card, or cash. Values in this column depend on fields that are tagged with the txn-item/payment-method semantic. |
Product Catalogs |
String |
Optional Product catalog fields are added to the Unified Itemized Transactions table in two ways, depending on the approach your tenant used for defining your product catalog:
Important The names of the columns that are available for product catalogs are identical. For example: Product Brand, Product Category, and Product Gender. The difference is the outcome of the approach your tenant used to define your product catalog within Amperity. |
Product ID |
String |
This column is input to predictive modeling. The unique identifier for a product. A stock keeping unit (SKU) is an identifier that captures unique details for individual products, including specific attributes to differentiate by color, size, material, and other product details. For example, a shirt with the same color and material, but with three different sizes would be represented by three unique SKUs and would also be represented by three unique product IDs. Note For data that has itemized transactions, where a single transaction includes more than one of the same product, the product ID appears more than once. Caution Every customer has their own definition for SKUs and product IDs. Be sure to understand this definition before applying semantic tags to fields with product IDs to ensure they accurately reflect the customer’s definition. Values in this column depend on fields that are tagged with the txn-item/product-id semantic. The combination of Order ID and Product ID must be unique for each row in this table. Product quantity is counted using Item Quantity. Important This column is recommended when using a product catalog. A product catalog is a requirement for certain predictive features of Amperity, such as for product affinity and audience sizes. |
Purchase Brand |
String |
The brand purchased by customer in a transaction. Note This column should only have values when interaction records contain transactions data for more than one brand. Values in this column depend on fields that are tagged with the txn-item/purchase-brand semantic. This column is used to calculate the following transaction attributes: Multi Purchase Brand. |
Purchase Channel |
String |
This column is input to predictive modeling. A purchase channel is the channel in which a customer makes a transaction. For example: in-store or online. Values in this column depend on fields that are tagged with the txn-item/purchase-channel semantic. |
Store ID |
String |
A store ID is a unique identifier for the location of a store. Values in this column depend on fields that are tagged with the txn-item/store-id semantic. |
Unit Cost |
Decimal |
Unit cost is the cost to produce a single unit of one item. Note This value must be greater than or equal to 0 for purchases, but less than or equal to 0 for returns or cancellations. Values in this column depend on fields that are tagged with the txn-item/unit-cost semantic. |
Unit Discount Amount |
Decimal |
Unit discount amount is the discount amount applied to a single unit of one item. This discount is often applied to all units of the same item within a single transaction. This value is used by Amperity for discount sensitivity analysis. Note This value must be greater than or equal to 0 for purchases, but less than or equal to 0 for returns or cancellations. Values in this column depend on fields that are tagged with the txn-item/unit-discount-amount semantic. |
Unit List Price |
Decimal |
Unit list price is the manufacturer’s suggested retail price (MSRP) for a single unit of an item. The manufacturer’s suggested retail price (MSRP) is the price before applying shipping costs, taxes, and discounts. MSRP is sometimes referred to as the base price. This value should equal the unit discount amount plus the unit subtotal. Note This value must be greater than or equal to 0 for purchases, but less than or equal to 0 for returns or cancellations. Values in this column depend on fields that are tagged with the txn-item/unit-list-price semantic. |
Unit Profit |
Decimal |
Unit profit represents the amount of profit earned when selling a single unit of an item. Note This value must be greater than or equal to 0 for purchases, but less than or equal to 0 for returns or cancellations. Values in this column depend on fields that are tagged with the txn-item/unit-profit semantic. |
Unit Revenue |
Decimal |
The total revenue for a single unit of an item or the total revenue for a single unit of a returned or cancelled item. Note This value must be less than or equal to 0 when is-return or is-cancellation are true. Values in this column depend on fields that are tagged with the txn-item/unit-revenue semantic. |
Unit Subtotal |
Decimal |
A unit subtotal is the amount for a single unit of one item, after applying discounts. This value is used by Amperity for discount sensitivity analysis. Note This value must be greater than or equal to 0 for purchases, but less than or equal to 0 for returns or cancellations. Values in this column depend on fields that are tagged with the txn-item/unit-subtotal semantic. |
Unit Tax Amount |
Decimal |
A unit tax amount is the total amount of taxes for a single unit. Note This value must be greater than or equal to 0 for purchases, but less than or equal to 0 for returns or cancellations. Values in this column depend on fields that are tagged with the txn-item/unit-tax-amount semantic. |
Custom attributes |
Varies |
You may extend the Unified Itemized Transactions table to define custom attributes for use with a product catalog. Important This column is recommended when using a product catalog. A product catalog is a requirement for certain predictive features of Amperity, such as for product affinity and audience sizes. Add custom attributes to the Unified Itemized Transactions table by extending it to add columns that support using a product catalog. Custom attributes should include the columns to which product catalog semantic tags were applied, but may include additional custom attributes that are unique to your tenant and your brands. Important The Unified Product Catalog table represents the taxonomy for your products and brands. Add attributes to the Unified Product Catalog table by applying pc/ semantic tags to fields in data sources that contain information about products. All pc/ semantic tags are optional. Use the ones that best define the shape of your product catalog and best describe the individual items within it. |
Unified Loyalty¶
The Unified Loyalty table has a row for every customer who belongs to your loyalty program, unique by combination of Amperity ID and loyalty ID.
The Unified Loyalty table has the following columns:
Column name |
Data type |
Description |
|---|---|---|
Amperity ID |
String |
The unique identifier assigned to clusters of customer profiles that all represent the same individual. The Amperity ID does not replace primary, foreign, or other unique customer keys, but exists alongside them within unified profiles. Note Loyalty profiles are unique by Amperity ID when:
(Source tables for loyalty profiles and events should not be made available to Stitch.) |
Birthdate |
Date |
The date of birth for the customer who belongs to the loyalty profile. |
Current Balance |
Integer |
The customer’s current rewards balance. |
Current Balance Expiration Datetime |
Datetime |
The date and time at which a customer’s current rewards balance will expire. |
Current Tier |
String |
The name of the rewards tier to which a customer belongs. |
Current Tier Expiration Datetime |
Datetime |
The date and time at which a customer’s membership in their current rewards tier will end. |
Current Tier Start Datetime |
Datetime |
The date and time at which a customer’s membership in their current rewards tier started. |
String |
The email address that is associated with a loyalty ID. Also in: Unified Loyalty Events |
|
Is Opted-in |
Boolean |
Required. Indicates if the customer associated with the loyalty ID has given consent to being contacted by your loyalty program. |
Latest Opt-out Datetime |
Datetime |
The date and time at which a customer most recently opted out from being contacted by your loyalty program. |
Latest Opted-in Datetime |
Datetime |
Required. The date and time at which a customer most recently opted in to being contacted by your loyalty program. |
Latest Update Datetime |
Datetime |
The date and time at which the information associated with the loyalty profile was updated. |
Lifetime Balance |
Integer |
The lifetime reward balance associated with the loyalty ID. |
Loyalty ID |
String |
Required. The unique ID for a loyalty profile. Also in: Unified Loyalty Events |
Next Tier |
String |
The name of the next loyalty tier to which, pending points accumulation, a customer belong. |
Sign-up Channel |
String |
The channel through which the customer signed up for the loyalty program. |
Sign-up Method |
String |
The method used by the customer to sign-up for the loyalty program. |
Spend To Keep Tier |
Decimal |
The amount of money a customer must spend to stay in their current loyalty tier. |
Spend To Next Tier |
Decimal |
The amount of money a customer must spend to move to the next loyalty tier. |
Unified Loyalty Events¶
The Unified Loyalty Events table has a row for loyalty program events, unique by Amperity ID and event datetime.
The Unified Loyalty Events table has the following columns:
Column name |
Data type |
Description |
|---|---|---|
Amperity ID |
String |
The unique identifier assigned to clusters of customer profiles that all represent the same individual. The Amperity ID does not replace primary, foreign, or other unique customer keys, but exists alongside them within unified profiles. Note Loyalty events are unique by Amperity ID and event datetime when:
|
Accrual Amount |
Integer |
The loyalty rewards amount that was accrued. |
Accrual Datetime |
Datetime |
The date and time at which loyalty rewards were accrued. |
Award ID |
String |
The unique ID for an award that is associated with a redemption or accrual event. |
Current Point Balance |
Integer |
The loyalty rewards balance that is associated with the current loyalty event. |
Current Tier |
String |
The loyalty tier that is associated with the current loyalty event. |
String |
The email address that is associated with a loyalty ID. Also in: Unified Loyalty |
|
Event Datetime |
Datetime |
Required. The date and time at which a loyalty event occurred. Note For transactions that represent accruals this value can also represent the date and time of the transaction. |
Event Description |
String |
A description of the loyalty event. |
Event Type |
String |
Required. The loyalty event type. May be one of the following values: “redemption”, “opt-out”, or “tier change”, or a custom event type. |
Expiration Datetime |
Datetime |
The date and time at which loyalty awards accrue or the loyalty tier changes. |
Loyalty ID |
String |
Required. The unique ID for a loyalty profile. Also in: Unified Loyalty |
Order Datetime |
Datetime |
The date and time at which an order that used accrued or redeemed loyalty rewards was made. |
Order ID |
String |
The unique ID for an order that is associated with a redemption or accrual event. |
Previous Point Balance |
Integer |
The loyalty rewards balance that is associated with the previous loyalty event. |
Previous Tier |
String |
The loyalty tier that is associated with the previous loyalty event. |
Redemption Amount |
Decimal |
The loyalty rewards amount that was redeemed. |
Redemption Datetime |
Datetime |
The date and time at which loyalty rewards were redeemed. |
Reservation Datetime |
Datetime |
The date and time at which a reservation that used accrued or redeemed loyalty rewards was made. |
Reservation ID |
String |
The unique ID for a reservation that is associated with a redemption or accrual event. |
Tier End Datetime |
Datetime |
The date and time at which the current loyalty tier ends or ended. |
Tier Start Datetime |
Datetime |
The date and time at which the current loyalty tier starts or started. |
Unified Preprocessed Raw¶
The Unified Preprocessed Raw table is an output of Stitch with rows of preprocessed values from every source table with Amperity IDs, including trivial duplicates. Bad values are removed and replaced with NULL.
Tip
Because there is only one row per trivial duplicate, join this table on the Unified Coalesced table for ongoing usage. For example:
SELECT *
FROM Unified_Coalesced uc
JOIN Unified_Preprocessed_Raw up
ON uc.rep_ds=up.datasource AND uc.rep_pk=up.pk
The Unified Preprocessed Raw table has the following columns:
Column name |
Data type |
Description |
|---|---|---|
Amperity ID |
String |
The unique identifier assigned to clusters of customer profiles that all represent the same individual. The Amperity ID does not replace primary, foreign, or other unique customer keys, but exists alongside them within unified profiles. Note The Amperity ID is a universally unique identifier (UUID) that is 36 characters spread across five groups separated by hyphens: 8-4-4-4-12. For example: 123e4567-e89b-12d3-a456-426614174000
|
Address |
String |
The address connected with the location of a customer, such as “123 Main Street”. Also in: Customer 360, Merged Customers, Unified Coalesced, Unified Customer |
Birthdate |
Date |
The date of birth connected with a customer. Also in: Customer 360, Merged Customers, Unified Coalesced, Unified Customer |
City |
String |
The city connected with the location of a customer. Also in: Customer 360, Merged Customers, Unified Coalesced, Unified Customer |
Component ID |
Integer |
An identifier that represents a set of records that are transitively connected. Records that share a component ID, but have different Amperity IDs, are split during identity resolution. Tip Use this field during the Stitch QA process to help identify why certain records were grouped or not grouped together. Also in: Unified Preprocessed Raw |
Datasource |
String |
The name of the data source from which this customer profile originated. Tip The combination of PK and Datasource uniquely identifies a row in the Unified Preprocessed Raw table, which correlates to a single row in a domain table. |
String |
The email address connected with a customer. A customer may have more than one email address. Also in: Customer 360, Merged Customers, Unified Coalesced, Unified Customer |
|
FK [Name] |
String |
The fk-[namespace] semantic tag identifies a field as a foreign key. A foreign key semantic tag must use a namespace and “namespace” is a string of characters. For example: fk-customer-id, fk-interaction, fk-audience, fk-loyalty-id, or fk-brand. A column is added for each foreign key that is defined in the Sources page. Note If foreign keys are linked together by a trivial duplicate they appears in the Unified Preprocessed Raw table as a comma-separated list. Also in: Unified Coalesced, Unified Customer |
Gender |
String |
The gender connected with a customer. Also in: Customer 360, Merged Customers, Unified Coalesced, Unified Customer |
Given Name |
String |
The first name connected with a customer. Also in: Customer 360, Merged Customers, Unified Coalesced, Unified Customer |
Int ID |
Integer |
An identifier that represents a unique combination of datasource and pk (primary key) and their position in the Stitch record sort order after Stitch has identified and removed trivial duplicates. Important This identifier is based on Stitch record sort order and is determined each time Stitch runs. Records will not always have the same position in the record sort order. You should not expect this ID to be stable over time. Tip Use this field during the Stitch QA process to help identify why certain records were grouped or not grouped together. |
Login Trimmed |
String |
|
Phone |
String |
The phone number connected with a customer. A customer may have more than one phone number. Also in: Customer 360, Merged Customers, Unified Coalesced, Unified Customer |
PK |
String |
The combination of data source and primary key allows Amperity to uniquely identify every row in every data table across the entirety of customer data input to Amperity. Tip The combination of PK and Datasource uniquely identifies a row in the Unified Preprocessed Raw table, which correlates to a single row in a domain table. |
PO Box |
String |
Address information, such as an apartment number or a post office box, connected with the location of a customer, such as “Apt #9”. |
Postal |
String |
The ZIP code or postal code connected with the location of a customer. Also in: Customer 360, Merged Customers, Unified Coalesced, Unified Customer |
SK Generational Suffix |
String |
|
SK Given Name |
String |
|
State |
String |
The state or province connected with the location of a customer. Also in: Customer 360, Merged Customers, Unified Coalesced, Unified Customer |
Supersized ID |
Integer |
The identifier for a supersized record. Indicates when a rough heuristic applies to the first grouping of records–the rep_pk field–to partition supersized records into smaller parts. Supersized records occur when more than 500 groups associate with the first grouping of records. Also in: Unified Coalesced |
Surname |
String |
The last name connected with a customer. Also in: Customer 360, Merged Customers, Unified Coalesced, Unified Customer |
Unified Product Catalog¶
The Unified Product Catalog table has a row for every item in your product catalog. Descriptive attributes include name, brand, size, and color. Grouping attributes include category, sub-category, class, and sub-class. Other attributes include MSRP, gender, and description.
Important
The Unified Product Catalog table represents the taxonomy for your products and brands. Add attributes to the Unified Product Catalog table by applying pc/ semantic tags to fields in data sources that contain information about products.
All pc/ semantic tags are optional. Use the ones that best define the shape of your product catalog and best describe the individual items within it.
The Unified Product Catalog table has the following columns:
Column name |
Data type |
Description |
|---|---|---|
Datasource |
String |
The name of the data source from which this customer profile originated. Tip The combination of PK and Datasource uniquely identifies a row in the Unified Coalesced table, which correlates to a single row in a domain table. |
PK |
String |
The combination of data source and primary key allows Amperity to uniquely identify every row in every data table across the entirety of customer data input to Amperity. Tip The combination of PK and Datasource uniquely identifies a row in the Unified Coalesced table, which correlates to a single row in a domain table. |
Product Brand |
String |
The brand name of a product or item. |
Product Brand ID |
String |
The ID for the brand name of a product or item. |
Product Category |
String |
This column is input to predictive modeling when joined to Unified Itemized Transactions. A category to which the product belongs. |
Product Category ID |
String |
The ID for the category to which a product belongs. |
Product Class |
String |
The name of the class (or grouping) to which a product or item belongs. |
Product Class ID |
String |
The ID for the name of the class (or grouping) to which a product or item belongs. |
Product Collection |
String |
The name of the collection to which a product or item belongs. |
Product Collection ID |
String |
The ID for the name of the collection to which a product or item belongs. |
Product Color |
String |
The color of a product or item. |
Product Color ID |
String |
The ID for the color of a product or item. |
Product Department |
String |
The department to which a product or item belongs. |
Product Department ID |
String |
The ID for the department to which a product or item belongs. |
Product Description |
String |
This column is input to predictive modeling when joined to Unified Itemized Transactions. A description of the product. |
Product Division |
String |
The division to which a product or item belongs. |
Product Division ID |
String |
The ID for the division to which a product or item belongs. |
Product Fabric |
String |
The fabric used for a product or item. |
Product Fabric ID |
String |
The ID for the fabric used for a product or item. |
Product Gender |
String |
A list of gender options for products. For example: F, M, unisex, NULL (for unknown). |
Product Group |
String |
The group to which a product or item belongs. |
Product ID |
String |
The unique identifier for a product. Values in this column depend on fields that are tagged with the pc/product-id semantic. |
Product Material |
String |
The material used for a product or item. |
Product Material ID |
String |
The ID for the material used for a product or item. |
Product MSRP |
Decimal |
The manufacturer’s suggested retail price (MSRP) for a product or item. The manufacturer’s suggested retail price (MSRP) is the price before applying shipping costs, taxes, and discounts. MSRP is sometimes referred to as the base price. |
Product Name |
String |
The name of the product or item. |
Product Season |
String |
The season to which a product or item is associated. |
Product Season ID |
String |
The ID for the season to which a product or item is associated. |
Product Silhouette |
String |
|
Product Size |
String |
The size of a product or item. |
Product Size ID |
String |
The ID for the size of a product or item. |
Product Sku |
String |
The stock keeping unit, or SKU, for the product or item. A stock keeping unit (SKU) is an identifier that captures unique details for individual products, including specific attributes to differentiate by color, size, material, and other product details. |
Product Style |
String |
The style of a product or item. |
Product Subcategory |
String |
This column is input to predictive modeling when joined to Unified Itemized Transactions. A subcategory or secondary variant to which a product belongs. |
Product Subcategory ID |
String |
The ID for the subcategory or secondary variant to which a product belongs. |
Product Subclass |
String |
The subclass to which a product or item is assigned. |
Product Subclass ID |
String |
The ID for the subclass to which a product or item is assigned. |
Product Subdepartment |
String |
The sub-department to which a product or item is assigned. |
Product Subdepartment ID |
String |
The ID for the sub-department to which a product or item is assigned. |
Product Type |
String |
The type assigned to a product or item. |
Product UPC |
String |
The UPC code for the product or item. A Universal Product Code (UPC or UPC code) is a barcode that is widely used to track items in stores. |
Unified Scores¶
The Unified Scores table records scoring for all pairwise comparisons and match categories for all scorable record pairs within an identity graph.
Note
See Unified Scores for more information about how this table is built and maintained within the customer 360 database.
The Unified Scores table has the following columns:
Column Name |
Data type |
PII |
Description |
||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
Amperity ID |
String |
|
The unique identifier assigned to clusters of customer profiles that all represent the same individual. The Amperity ID does not replace primary, foreign, or other unique customer keys, but exists alongside them within unified profiles. Note The Amperity ID is a universally unique identifier (UUID) that is 36 characters spread across five groups separated by hyphens: 8-4-4-4-12. For example: 123e4567-e89b-12d3-a456-426614174000
|
||||||||||||||
Source1 |
String |
||||||||||||||||
Source2 |
String |
||||||||||||||||
PK1 |
String |
||||||||||||||||
PK2 |
String |
||||||||||||||||
Score |
Float |
A score has a value from “0.0” to “5.0” that represents the combined score assigned to the record pair by Stitch. A score has two parts: the score is on the left side and the score’s strength is on the right. The record pair score correlates to the match category, which is a classifier applied by Amperity to individual record pairs. The record pair score corresponds to the classification:
The record pair strength represents the strength of the record pair score assigned by Stitch during identity resolution. It is a two digit number. For example: .31 is a lower strength and .93 is a higher strength. Note Scores are shown for records that end up in the same cluster, including any scores that are below threshold. Scores are not shown for records that do not end up in the same cluster. Also in: Detailed Examples |
|||||||||||||||
Match Category |
String |
A match category is applied to individual record-pair comparisons discovered by deterministic and probabilistic matching strategies during identity resolution.
Also in: Detailed Examples |
|||||||||||||||
Match Type |
String |
The score assigned to matched records is the match type. Possible values: “scored”, “scored_transitive”, and “trivial_duplicate”. Records assigned a “scored” value are directly connected by deterministic or probabilistic matching. Records assigned a “scored_transitive” value are transitively connected. A match is assigned “scored_transitive” when that match was not identified during blocking. For example: three records (A, B, and C). If records A and B and records B and C were identified as matching during blocking, all three records will end up in the same group of records for pairwise comparison. Records A and C have a transitive connection. |
Unified Transactions¶
The Unified Transactions table has one row for each unique transaction record, with each order ID associated to an Amperity ID.
The following diagram shows an example of the Unified Transactions table. Click to view a larger diagram.
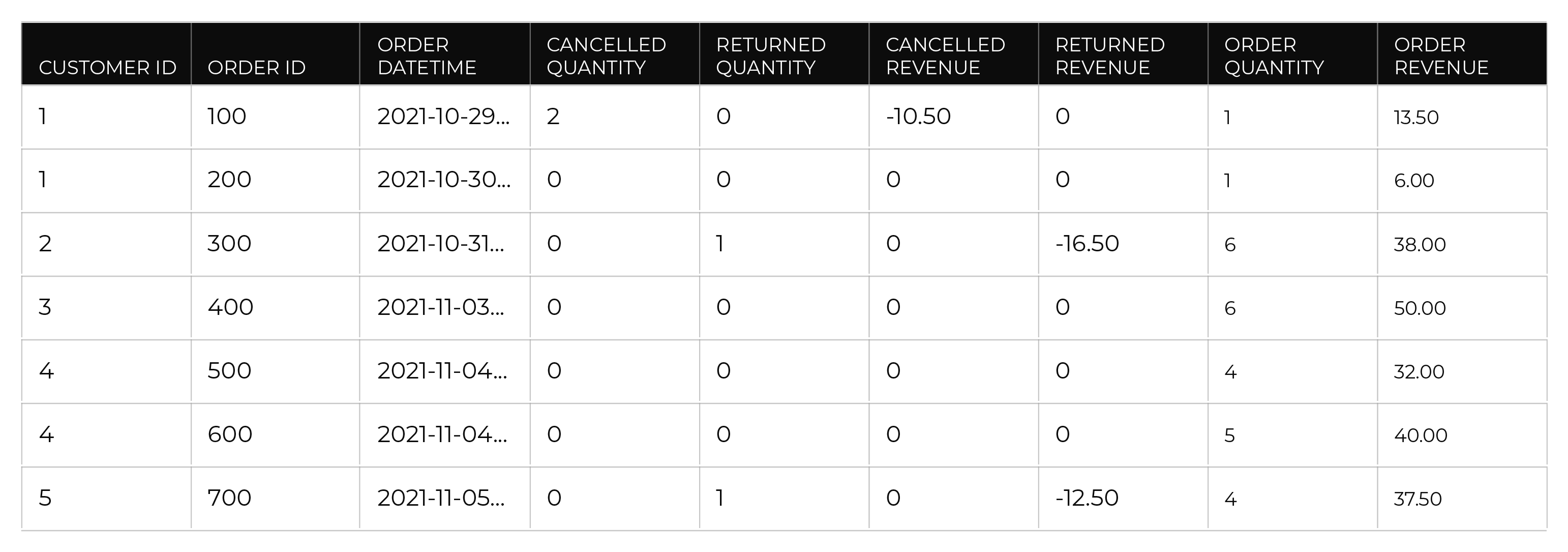
The Unified Transactions table has the following columns:
Column name |
Data type |
Description |
|---|---|---|
Amperity ID |
String |
This column is input to predictive modeling. The unique identifier assigned to clusters of customer profiles that all represent the same individual. The Amperity ID does not replace primary, foreign, or other unique customer keys, but exists alongside them within unified profiles. Note The Amperity ID is a universally unique identifier (UUID) that is 36 characters spread across five groups separated by hyphens: 8-4-4-4-12. For example: 123e4567-e89b-12d3-a456-426614174000
|
Currency |
String |
Currency represents the currency used to pay for an item. The value should be a three character alphabetic ISO 4217 currency code , such as “USD” (United States dollar), “JPY” (Japanese Yen), “GBP” (Great Britain pound), or “EUR” (Euro). Note Currency must be consistent across all orders from the same data source. |
Customer ID |
String |
A customer ID is an identifier that uniquely identifies a customer within a dataset. For example, a loyalty ID, a mobile app ID, or a login name from a website. A customer ID may appear once for each order ID in the transactions table. When a foreign key is not present, the customer ID is used to join interaction records to tables that contain the Amperity ID. Note A namespaced foreign key should be used along with a customer ID. When a foreign key is added to transactions data it:
Also in: Unified Itemized Transactions |
Digital Channel |
String |
The digital channel for a transaction. For example: Facebook, Google Ads, email, TikTok Ads, or Reddit. Note This column should only have values when purchase-channel specifies an online channel. |
Fiscal Calendars |
Varies |
A fiscal calendar is a yearly accounting period that aligns the weeks and months in a calendar year with holidays and a brand calendar. Use a fiscal calendar to align the business for an entire calendar year. A common fiscal calendar brands use is the 4-5-4 fiscal calendar. The SQL template for the Unified Transaction table has a series of fields for use with fiscal calendars. For example:
Before you can use fiscal calendar attributes in the Unified Transactions table you must configure the SQL template for your brand’s fiscal calendar. |
Net Order Revenue |
Decimal |
Net order revenue is total revenue minus costs, returns, and discounts. This value must be configured in the SQL template for the Unified Transaction table. |
Order Canceled Quantity |
Integer |
This column is input to predictive modeling. The total number of cancelled items in the original transaction. This value should match the sum of all items in the itemized transactions that were canceled for the same order ID. Important This value must be less than or equal to 0 when is_canceled is TRUE. |
Order Canceled Revenue |
Decimal |
This column is input to predictive modeling. The total amount of revenue for all canceled items in the transaction. This value should match the sum of the revenue for all items in the itemized transactions that were canceled. Important This value must be less than or equal to 0 when is_canceled is TRUE. |
Order Cost |
Decimal |
Order cost represents the total cost of goods sold (COGS) for a single transaction, minus returns, cancellations, and discounts. Cost of goods sold (COGS) are the direct costs of producing goods sold by a brand, including the costs of materials and labor to produce the item, but excluding indirect expenses like distribution or sales. This value must be configured in the SQL template for the Unified Transaction table. Note This value must be greater than or equal to 0 for purchases, but less than or equal to 0 for returns or cancellations. Warning Only one of order-profit and order-cost may be present for a transaction. |
Order Datetime |
Datetime |
This column is input to predictive modeling. Order datetime is the date and time on which a customer places an order. The order date:
Note Other dates associated with an order that are not specific to a transactions, such as dates associated with hotel stays and reservations, should be added to the Unified Product Catalog table. This column is used to calculate the following transaction attributes:
Also in: Unified Itemized Transactions |
Order Discount Amount |
Decimal |
This column is input to predictive modeling. Order discount amount is the total discount amount applied to the entire order. Note This value must be greater than or equal to 0 for purchases, but less than or equal to 0 for returns or cancellations. This value is used by Amperity for discount sensitivity analysis and must be configured in the SQL template for the Unified Transaction table. Caution This value should match the customer’s definition of an order-level discount. For example, some customers associate this value to order value, whereas others associate this value to a subtotal. Use domain SQL to update this field for the desired calculation. Also in: Unified Itemized Transactions |
Order Discount Percent |
Decimal |
Order discount percent is the percentage discount applied to the order value for the entire transaction, along with any item-specific or unit-specific discount percentages. This value may be used as an input to order discount amount. Note This value must be between 0 and 1. This value is used by Amperity for discount sensitivity analysis. Caution This value should match the customer’s definition of an order-level discount percentage. For example, some customers associate this value to order value, whereas others associate this value to a subtotal. Use domain SQL to update this field for the desired calculation. |
Order ID |
String |
This column is input to predictive modeling. An order ID is the unique identifier for the order. It links together all items in the same transaction. For returns and cancellations, the order ID is the unique identifier for the original order, including returned or canceled items. This column is the primary key and must be associated with the PK semantic tag. Each unique order ID must:
Note The order ID should never change, even when an item in the order is returned or canceled. Caution If order IDs are recycled and are otherwise not guaranteed to be unique over time, the unique identifier for the order must be updated to be a combination of the order ID and the date on which the order occurred. This must be done using domain SQL similar to: This column is used to calculate the following transaction attributes:
Also in: Unified Itemized Transactions |
Order List Price |
Decimal |
Order list price is the total value for a transaction, as defined by the manufacturer’s suggested retail price (MSRP) for all units of this item. The manufacturer’s suggested retail price (MSRP) is the price before applying shipping costs, taxes, and discounts. MSRP is sometimes referred to as the base price. This value should match the sum of item list price amounts in the itemized transactions that are associated with the same order ID. Note This value must be greater than or equal to 0 for purchases, but less than or equal to 0 for returns or cancellations. |
Order Profit |
Decimal |
Order profit is the amount of profit earned from a single transaction. Note This value must be greater than or equal to 0 for purchases, but less than or equal to 0 for returns or cancellations. Warning Only one of order-profit and order-cost may be present for a transaction. |
Order Quantity |
Integer |
This column is input to predictive modeling. Order quantity is the total number of individual items in the transaction. This value should match the sum of all items in the itemized transactions that have not been returned or canceled for the same order ID. Note This value must be greater than or equal to 0 for purchases, but less than or equal to 0 for returns or cancellations. This column is used to calculate the following transaction attributes:
|
Order Returned Quantity |
Integer |
This column is input to predictive modeling. Order returned quantity is the total number of returned items in the original transaction. This value should match the sum of all items in the itemized transaction that were returned for the same order ID. Note This value must be less than or equal to 0. Important This value must be less than or equal to 0 when is_return is TRUE. |
Order Returned Revenue |
Decimal |
This column is input to predictive modeling. Order returned revenue is the total amount of revenue for all returned items. This value should match the sum of the revenue for all items in the itemized transactions that were returned. Important This value must be less than or equal to 0 when is_return is TRUE. |
Order Revenue |
Decimal |
This column is input to predictive modeling. The total amount of revenue for all items in a transaction after discounts and ignoring returns or cancellations. Note This value must be greater than or equal to 0 for purchases, but less than or equal to 0 for returns or cancellations. This column is used to calculate the following transaction attributes:
|
Order Shipping Amount |
Decimal |
The order shipping amount is the total cost of shipping all items in the same transaction. Note This value must be greater than or equal to 0 for purchases, but less than or equal to 0 for returns or cancellations. |
Order Subtotal |
Decimal |
An order subtotal is the amount for an order, after applying discounts. This value should match the sum of item subtotal revenue in the itemized transactions that are associated with the same order ID. |
Order Tax Amount |
Decimal |
An order tax amount is the total amount of taxes applied to the entire order. Note This value must be greater than or equal to 0 for purchases, but less than or equal to 0 for returns or cancellations. |
Payment Method |
String |
A payment method is how a customer chose to pay for the items they have purchased. For example: credit card, gift card, or cash. |
Purchase Brand |
String |
This column is input to predictive modeling. The brand purchased by customer in a transaction. Note This column should only have values when interaction records contain transactions data for more than one brand. This column is used to calculate the following transaction attributes: Multi Purchase Brand. |
Purchase Channel |
String |
This column is input to predictive modeling. A purchase channel is the channel in which a customer makes a transaction. For example: in-store or online. |
Store ID |
String |
This column is input to predictive modeling. A store ID is a unique identifier for the location of a store. |
Sum Item Discount Amount |
Decimal |
The sum of discount amounts is the total of all discount amounts applied to each item within a transaction. This value should match the sum of item discount amounts in the itemized transactions that are associated with the same order ID. |
Sum Item Revenue |
Decimal |
The sum of itemized revenue for the original order, not including returns or cancellations. This value may be used as an input to order revenue. This value should match the sum of item revenue in the itemized transactions that are associated with the same order ID. Note This value must be greater than or equal to 0 for purchases, but less than or equal to 0 for returns or cancellations. |